사실 RAG 로 구현하면 좀더 수월하게 진행될거 같지만 파인튜닝으로 해보고 싶어서... 진행시켜!!
1. 데이터 수집
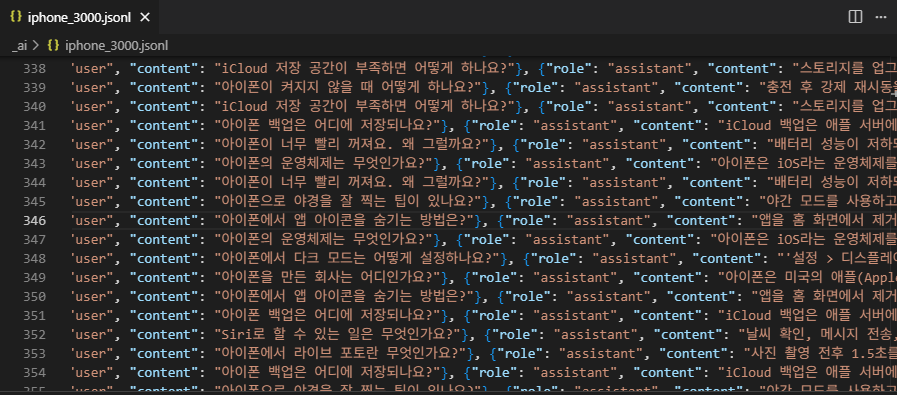
gpt에게 아이폰 관련 질문과 답변을 3,000개 만들어달라고 뗴쓴다.
역시 빠르게 만들어준다. Openorca 를 써볼까도 했지만 어제일(네이버 뉴스 학습 실패함)이 생각나서 빠르게 포기했다.
2. 기준이 될 모델 선정
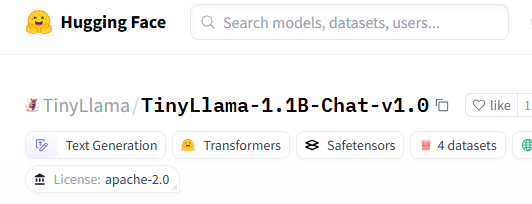
TinyLlama/TinyLlama-1.1B-Chat-v1.0 로 골랐다.
exaone3.5:2.4b 가 유력한 후보였으나 최대한 아는 정보가 없는 모델을 고르는게 핵심이라...
3. 기준 모델 테스트
from transformers import pipeline, AutoTokenizer, AutoModelForCausalLM
model_id = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_id, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", torch_dtype="auto", trust_remote_code=True)
# 파이프라인 정의
pipe = pipeline("text-generation", model=model, tokenizer=tokenizer)
# 입력 메시지를 chat template 형식으로 변환
messages = [
{"role": "system", "content": "당신은 아이폰 전문가 챗봇입니다. 사용자의 질문에 답변해 주세요."},
{"role": "user", "content": "아이폰으로 야경을 잘 찍는 팁이 있나요?"},
{"role": "assistant", "content": ""}
]
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# 생성
outputs = pipe(prompt, max_new_tokens=256, do_sample=True, temperature=0.7)
print(outputs[0]["generated_text"])4. 기준 모델 결과
이게 뭐여 시볼 ㅋㅋㅋㅋ
오케이 댔다. 내가 원하는게 이런거임.

5. 수집된 데이터를 훈련
RTX3090 24G * 2
배치 4, 에폭 10, 그라디엔트 4
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model
import torch
from datasets import load_dataset
from transformers import TrainingArguments, Trainer, DataCollatorForLanguageModeling
from dotenv import load_dotenv
import os
import gc
output_dir = "./TinyLlama/TinyLlama-1.1B-Chat-v1.0-iphone-faq"
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
jsonl_path = "./iphone_3000.jsonl"
# .env 파일에서 Hugging Face API 키를 로드
load_dotenv()
hf_token = os.getenv("HUGGINGFACE_API_KEY")
# 사전 학습된 인과 언어 모델을 float32 타입으로 CPU에 로드
# accelerate launch 로 실행할거라서 device_map 사용 안함
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
# device_map="auto",
token=hf_token,
trust_remote_code=True
)
# 모델에 맞는 토크나이저를 로드
tokenizer = AutoTokenizer.from_pretrained(model_name, token=hf_token, trust_remote_code=True)
# 토크나이저에 패딩 토큰이 없으면 EOS(문장 끝) 토큰을 사용한다.
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
# LoRA(Low-Rank Adaptation) 설정
lora_config = LoraConfig(
r=8, # LoRA의 랭크. 값이 작을수록 학습 파라미터가 적고 빠름
lora_alpha=32, # LoRA 스케일링 인자. r 값과 함께 LoRA 가중치의 스케일을 조절한다.
target_modules=["q_proj", "v_proj"], # LoRA를 적용할 모델의 특정 레이어(여기서는 쿼리, 값 프로젝션)를 지정한다.
lora_dropout=0.05, # LoRA 레이어에 적용할 드롭아웃 비율
bias="none", # 바이어스 파라미터에 LoRA를 적용할지 여부 ('none'은 적용 안 함).
task_type="CAUSAL_LM" # 미세 조정할 작업 유형을 인과 언어 모델링으로 설정한다.
)
# 정의된 LoRA 설정을 모델에 적용하여 PEFT 모델을 만듬
model = get_peft_model(model, lora_config)
# 학습 가능한 파라미터 수를 출력
model.print_trainable_parameters()
# JSON 형식의 데이터셋을 로드
dataset = load_dataset("json", data_files={"train": jsonl_path})["train"]
# 챗 메시지 데이터를 모델 입력 형식으로 전처리하는 함수
def preprocess_chat(example):
messages = example["messages"]
# 챗 템플릿을 사용하여 메시지를 문자열로 변환하고 토큰화
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=False)
tokenized = tokenizer(prompt, padding="max_length", truncation=True, max_length=512)
tokenized["labels"] = tokenized["input_ids"].copy()
return tokenized
# 데이터셋의 각 예제에 전처리 함수를 적용
dataset = dataset.map(preprocess_chat)
# 모델 학습에 필요한 인자(TrainingArguments)를 설정
training_args = TrainingArguments(
output_dir=output_dir, # 학습 중 생성되는 체크포인트 및 로그 파일의 저장 경로
per_device_train_batch_size=4, # 각 장치(CPU/GPU)당 학습에 사용될 배치 크기
gradient_accumulation_steps=4, # 기울기 업데이트를 하기 전까지 기울기를 축적할 단계 수. 늘리면 배치 크기 커짐.
num_train_epochs=10, # 전체 학습 데이터셋을 몇 번 반복하여 학습할지 지정하는 에포크 수
learning_rate=2e-4, # 모델 학습 시 사용될 학습률
save_total_limit=2, # 저장될 모델 체크포인트의 최대 개수. 이 개수를 초과하면 오래된 체크포인트가 삭제됨
logging_steps=3, # 학습 진행 상황(손실 등)을 로그로 기록할 단계 간격
bf16=False,
fp16=True,
report_to="none" # 학습 진행 상황을 보고할 외부 도구(예: TensorBoard, Weights & Biases)
)
# 언어 모델링을 위한 데이터 콜레이터를 설정
data_collator = DataCollatorForLanguageModeling(
tokenizer=tokenizer,
mlm=False
)
# Trainer 객체를 초기화
trainer = Trainer(
model=model,
train_dataset=dataset,
args=training_args,
data_collator=data_collator
)
# 모델 학습을 시작
trainer.train()
# 학습된 모델과 토크나이저를 지정된 경로에 저장
trainer.save_model(output_dir)
tokenizer.save_pretrained(output_dir)6. 훈련 결과
소요시간은 총 15분 정도였던거 같다. 완료 로그를 확인 못함...
7. 훈련된 모델로 추론 테스트
기존 모델에 튜닝된 모델을 얹어서 테스트한다.
질문내용은 똑같이 진행.
# inference_lora_exaone_cuda.py
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import PeftModel
import os
from dotenv import load_dotenv
import gc
# .env 파일에서 Hugging Face API 키를 로드
load_dotenv()
hf_token = os.getenv("HUGGINGFACE_API_KEY")
# --- 설정 변수 ---
# 학습된 LoRA 어댑터가 저장된 디렉토리
output_dir = "./TinyLlama/TinyLlama-1.1B-Chat-v1.0-iphone-faq"
# 원본 사전 학습 모델의 Hugging Face ID
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
# 병합된 모델을 저장할 새로운 디렉토리 (선택 사항)
merged_model_dir = "./TinyLlama/TinyLlama-1.1B-Chat-v1.0-iphone-faq"
# --- 모델 로드 및 LoRA 가중치 병합 ---
print(f"원본 모델 '{model_name}' 로드 중...")
base_model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16, # 학습 시 사용했던 dtype과 일치시키는 것이 좋음.
device_map="auto", # 사용 가능한 GPU에 모델 레이어 자동 할당 (CUDA 환경 자동 감지)
token=hf_token,
trust_remote_code=True
)
print("원본 모델 로드 완료.")
print(f"LoRA 어댑터 '{output_dir}' 로드 중...")
# PeftModel을 사용하여 로드한 원본 모델 위에 학습된 LoRA 어댑터를 연결
model = PeftModel.from_pretrained(base_model, output_dir)
print("LoRA 어댑터 로드 완료.")
print("LoRA 가중치를 기본 모델에 병합 중...")
# LoRA 가중치를 기본 모델에 영구적으로 병합하고, PeftModel 구조를 해제하여
# 일반 AutoModelForCausalLM 객체로 변환
model = model.merge_and_unload()
print("LoRA 가중치 병합 완료.")
# 병합된 모델을 저장 (선택 사항):
print(f"병합된 모델을 '{merged_model_dir}'에 저장 중...")
model.save_pretrained(merged_model_dir)
print("병합된 모델 저장 완료.")
# --- 토크나이저 로드 ---
print(f"토크나이저 '{model_name}' 로드 중...")
# 추론 시에도 학습 시 사용했던 동일한 토크나이저를 로드해야 함
tokenizer = AutoTokenizer.from_pretrained(model_name, token=hf_token, trust_remote_code=True)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
print("토크나이저 로드 완료.")
# --- 추론 예시 ---
print("\n--- 추론 시작 ---")
# 모델에게 질문을 던질 메시지 리스트를 정의
# assistant 역할의 content는 모델이 생성할 부분
messages = [
{"role": "system", "content": "당신은 아이폰 전문가 챗봇입니다. 사용자의 질문에 답변해 주세요."},
{"role": "user", "content": "아이폰은 지문 인식을 지원하나요?"},
{"role": "assistant", "content": ""}
]
# 챗 템플릿을 사용하여 모델 입력 형식에 맞는 문자열 프롬프트를 생성
# add_generation_prompt=True는 모델이 답변 생성을 시작해야 함을 나타내는 토큰을 추가
input_text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
print(f"입력 프롬프트:\n---\n{input_text}\n---")
# 생성된 문자열 프롬프트를 토큰 ID로 변환하고, 모델이 있는 장치로 이동
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
# 텍스트 생성 파라미터 설정
generation_params = {
"max_new_tokens": 512, # 생성할 최대 토큰 수
"top_p": 0.9, # Top-p 샘플링
"temperature": 0.2, # 온도 조절
"eos_token_id": tokenizer.eos_token_id, # 문장 종료 토큰 지정
"pad_token_id": tokenizer.pad_token_id # 패딩 토큰 지정
}
print("텍스트 생성 중...")
outputs = model.generate(
**inputs,
**generation_params
)
print("텍스트 생성 완료.")
# 생성된 토큰 ID를 다시 사람이 읽을 수 있는 텍스트로 변환
generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(f"생성된 텍스트:\n---\n{generated_text}\n---")
print("\n--- 추론 완료 ---")8. 결과
정답지는 아래와 같다.
첫 소절에 정답을 알려줬지만 뒤에 사족이 붙는다. 그래도 정답!
{"messages": [{"role": "system", "content": "당신은 아이폰 전문가 챗봇입니다. 사용자의 질문에 답변해 주세요."}, {"role": "user", "content": "아이폰은 지문 인식을 지원하나요?"}, {"role": "assistant", "content": "일부 모델은 Touch ID를 지원합니다."}]}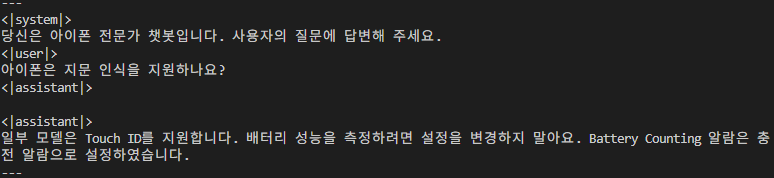
-------- 다른 질문도 해보자. ----------
튜닝 설정을 좀 깎으면 잘 될듯 하다.
{"messages": [{"role": "system", "content": "당신은 아이폰 전문가 챗봇입니다. 사용자의 질문에 답변해 주세요."}, {"role": "user", "content": "아이폰에서 알림을 끄는 방법은?"}, {"role": "assistant", "content": "'설정 > 알림'에서 개별 앱의 알림을 비활성화할 수 있습니다."}]}


인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.