1. Agent 의 callback 사용법
종류는 총 4가지가 있다.
- before_model_callback
- after_model_callback
- before_agent_callback
- after_agent_callback
root_agent = Agent(
name="root_agent",
model=LiteLlm(model="ollama/llama3:8b-instruct-q4_0"),
description="문장을 기반으로 Q&A 쌍을 일괄적으로 생성합니다.",
instruction="한 문장에서 중복되지 않는 Q&A 쌍을 JSONL 형식으로 생성합니다. 질문과 답변의 중복을 피하세요.",
before_model_callback=before_model_callback,
after_model_callback=after_model_callback,
before_agent_callback=before_agent_callback,
after_agent_callback=after_agent_callback
)2. callback parameter
자세한 내용은 https://google.github.io/adk-docs/callbacks/types-of-callbacks/
before_agent_callback (callback_context: CallbackContext) -> Optional[types.Content]:
after_agent_callback (callback_context: CallbackContext) -> Optional[types.Content]:
before_model_cakkback (
callback_context: CallbackContext, llm_request: LlmRequest
) -> Optional[LlmResponse]:
after_model_callback (
callback_context: CallbackContext, llm_response: LlmResponse
) -> Optional[LlmResponse]:
3. 데이터 생성에 적용해 보자.
import json
import os
from typing import List, Dict, Set, Tuple
from google.adk.agents import Agent
from google.adk.models.lite_llm import LiteLlm
from google.adk.agents.callback_context import CallbackContext
from typing import Optional
from google.adk.models import LlmResponse, LlmRequest
from google.genai import types # For types.Content
# ------------------ 프롬프트 생성 ------------------
def generate_qa_prompt(context: str, batch_index: int, batch_size: int = 10) -> str:
return (
f"[문장]: {context}\n\n"
f"이 문장을 바탕으로 반드시 {batch_size}개의 서로 다른 질문과 그에 대한 답변을 생성해 주세요.\n"
"각 질문과 답변은 중복되지 않아야 하며, 표현 방식도 다양해야 합니다.\n"
"형식은 JSONL이며, 각 줄은 아래 형식과 완전히 일치해야 합니다:\n"
'{"instruction": "질문", "input": "", "output": "답변"}\n\n'
"예시:\n"
'{"instruction": "서울은 어떤 나라의 수도인가요?", "input": "", "output": "대한민국의 수도는 서울입니다."}\n'
'{"instruction": "사과에 많이 들어있는 영양소는?", "input": "", "output": "비타민 C와 식이섬유입니다."}\n\n'
f"{batch_index * batch_size + 1}번부터 {batch_index * batch_size + batch_size}번까지 생성해 주세요.\n"
"※ 3~5개 정도 생성해 주세요."
"※ 중요:instruction과 output은 한국어로 작성해 주세요."
)
# ------------------ 파싱 / 중복 제거 ------------------
def parse_jsonl(text: str) -> List[Dict[str, str]]:
return [json.loads(line) for line in text.strip().splitlines() if line.strip()]
def normalize(text: str) -> str:
import re
return re.sub(r"\s+", " ", text.strip().lower())
def remove_duplicates(qa_list: List[Dict[str, str]], existing_set: Set[Tuple[str, str]]) -> List[Dict[str, str]]:
seen = set(existing_set)
unique = []
for qa in qa_list:
key = (normalize(qa['instruction']), normalize(qa['output']))
if key not in seen:
seen.add(key)
unique.append(qa)
return unique
# ------------------ 기존 결과 불러오기 ------------------
def load_existing_qa(path: str) -> Tuple[List[Dict[str, str]], Set[Tuple[str, str]]]:
if not os.path.exists(path):
return [], set()
with open(path, "r", encoding="utf-8") as f:
qa_list = [json.loads(line) for line in f if line.strip()]
key_set = {(normalize(q["instruction"]), normalize(q["output"])) for q in qa_list}
return qa_list, key_set
# --- Define the Callback Function ---
def after_model_callback(
callback_context: CallbackContext, llm_response: LlmResponse
) -> Optional[LlmResponse]:
"""Inspects/modifies the LLM response after it's received."""
agent_name = callback_context.agent_name
print(f"[Callback] After model call for agent: {agent_name}")
print("[Callback - val] "+llm_response.content.parts[0].text)
result_jsonl = llm_response.content.parts[0].text
append_text_to_file("result.jsonl", result_jsonl)
def append_text_to_file(path: str, lines: str | List[str]) -> None:
# 문자열 하나를 리스트로 변환
if isinstance(lines, str):
lines = [lines]
with open(path, "a", encoding="utf-8") as f:
for line in lines:
f.write(line.rstrip() + "\n") # 줄 끝 개행을 보장
# ------------------ 생성 에이전트 ------------------
root_agent = Agent(
name="root_agent",
model=LiteLlm(model="ollama/llama3:8b-instruct-q4_0"),
description="문장을 기반으로 Q&A 쌍을 일괄적으로 생성합니다.",
instruction="한 문장에서 중복되지 않는 Q&A 쌍을 JSONL 형식으로 생성합니다. 질문과 답변의 중복을 피하세요.",
after_model_callback=after_model_callback,
)--- 이렇게 여러번 돌린 후---
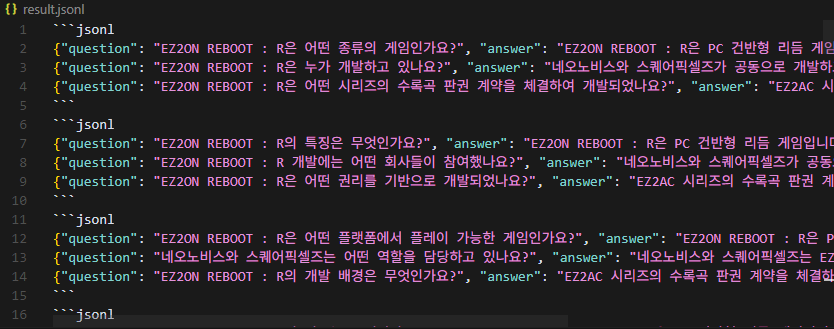
4. 생성된 jsonl 파일
모델이 주는 텍스트를 그대로 넣다보니 이렇게 되었다.
데이터 정제는 필수다.

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.