1. 어? ollama 연동도 된다.
-
google 의 모델을 사용하는게 아니기 때문에 사용량 변화는 없다.
자료가 없으니 찾는데 애좀 먹었다... -
모델명은 https://docs.litellm.ai/docs/providers/ollama#example-usage 를 참고해서 넣었더니 되더라...
-
허깅페이스는 여기로 https://docs.litellm.ai/docs/providers/huggingface
from google.adk.models.lite_llm import LiteLlm
...
...
...
# Agent 선언부의 model 을 이런 식으로 작성하면 된다.
model=LiteLlm(model="ollama/llama3:8b-instruct-q4_0")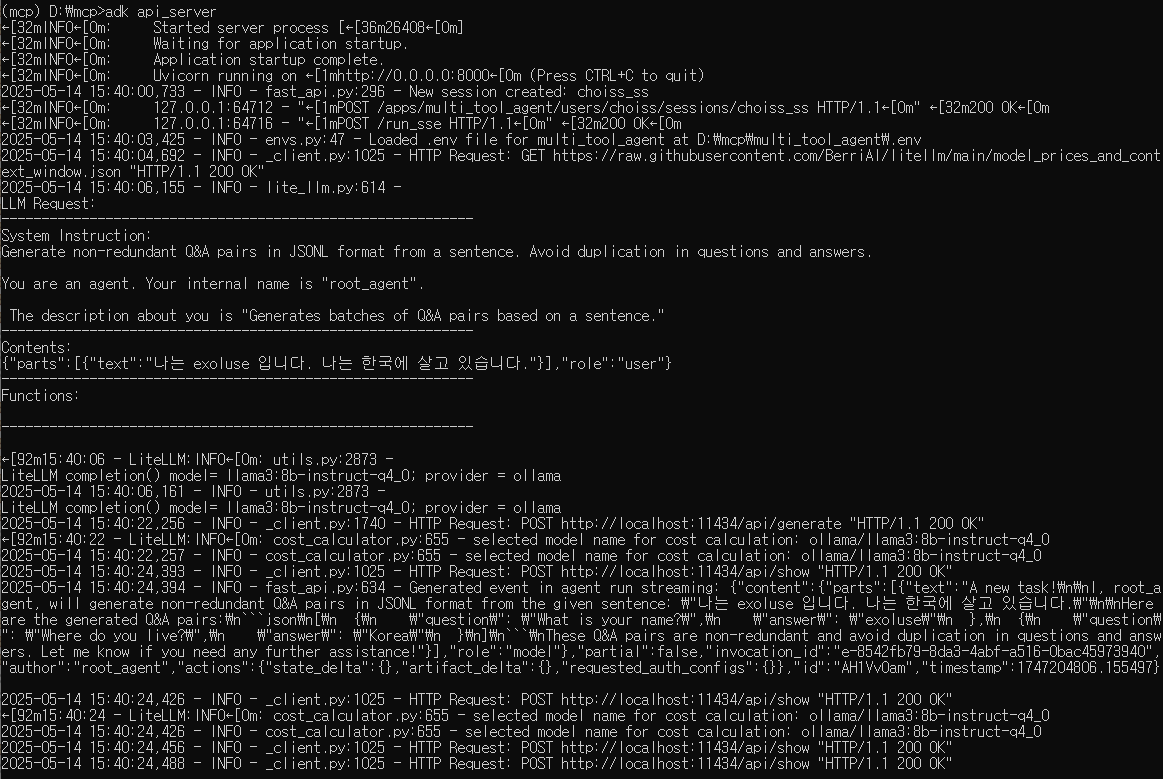
2. 한국어 그나마 좀 하는 모델로 테스트
같은 조건으로 모델만 바꿔본다.
테스트 모델은 exaone3.5:7.8b 이다.
{
"content": {
"parts": [
{
"text": "```jsonl\n{\"question\": \"어디에 거주하시나요?\", \"answer\": \"한국에 거주하고 계십니다.\"}\n{\"question\": \"귀하의 이름은 무엇인가요?\", \"answer\": \"exoluse 입니다.\"}\n```"
}
],
"role": "model"
},
"partial": false,
"invocation_id": "e-1bb7d20b-3466-4b42-82a4-ab768741caba",
"author": "root_agent",
"actions": {
"state_delta": {},
"artifact_delta": {},
"requested_auth_configs": {}
},
"id": "WIW06AmT",
"timestamp": 1747209890.686386
}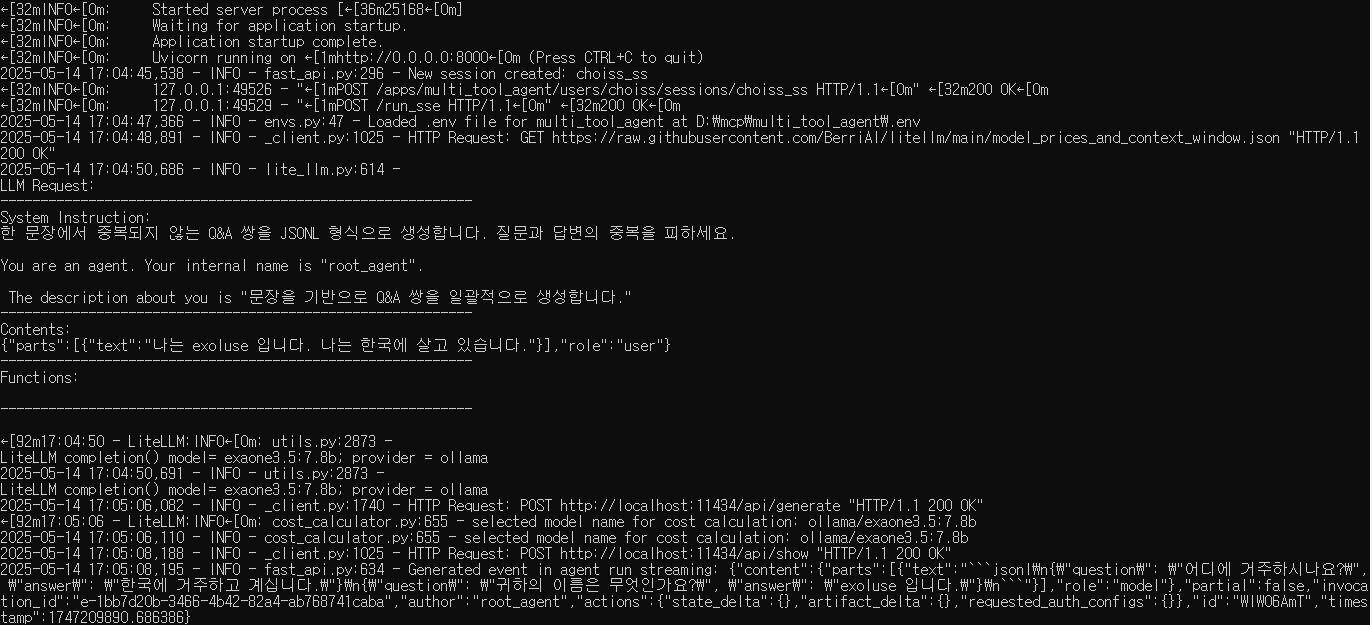
나름 만족스러운 결과를 보여준다.
허깅페이스 테스트는 조만간...
역시 한국어. 펄럭~


인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.