1. agent_alone.py
from litellm import completion as litellm_completion
from typing import List, Callable, Any, Dict
def generate_qa_prompt(context: str, batch_index: int, batch_size: int = 10) -> str:
return (
f"[문장]: {context}\n\n"
f"이 문장을 바탕으로 반드시 {batch_size}개의 서로 다른 질문과 그에 대한 답변을 생성해 주세요.\n"
"각 질문과 답변은 중복되지 않아야 하며, 표현 방식도 다양해야 합니다.\n"
"형식은 JSONL이며, 각 줄은 아래 형식과 완전히 일치해야 합니다:\n"
'{"instruction": "질문", "input": "", "output": "답변"}\n\n'
"예시:\n"
'{"instruction": "서울은 어떤 나라의 수도인가요?", "input": "", "output": "대한민국의 수도는 서울입니다."}\n'
'{"instruction": "사과에 많이 들어있는 영양소는?", "input": "", "output": "비타민 C와 식이섬유입니다."}\n\n'
f"{batch_index * batch_size + 1}번부터 {batch_index * batch_size + batch_size}번까지 생성해 주세요.\n"
"※ 3~5개 정도 생성해 주세요."
"※ 중요 : instruction과 output은 한국어로 작성해 주세요."
"**※ 매우 중요 : JSONL 형식만 출력하고, 그 어떤 다른 텍스트(예: ```jsonl, ```)도 포함하지 마세요.**"
)
def after_model_callback(input: str, output: str) -> None:
print(f"\nInput:\n{input}\n")
print(f"\nOutput:\n{output}\n")
class LiteLlm:
def __init__(self, model: str):
self.model = model
def complete(self, prompt: str, **kwargs):
response = litellm_completion(model=self.model, messages=[{"content": prompt, "role": "user"}], **kwargs)
return response.choices[0].message.content
class Agent:
def __init__(self, name: str, model: Any, description: str, instruction: str, after_model_callback: Callable = None, tools: List = None):
self.name = name
self.model = model
self.description = description
self.instruction = instruction
self.after_model_callback = after_model_callback
self.tools = tools or []
def run(self, input_data: str):
# prompt = f"{self.instruction}\n\n문장: {input_data}"
prompt = generate_qa_prompt(input_data, 0, 5)
output = self.model.complete(prompt)
if self.after_model_callback:
self.after_model_callback(input_data, output)
return output
root_agent = Agent(
name="root_agent",
model=LiteLlm(model="ollama/exaone3.5:7.8b"),
description="문장을 기반으로 Q&A 쌍을 일괄적으로 생성합니다.",
instruction="한 문장에서 중복되지 않는 Q&A 쌍을 JSONL 형식으로 생성합니다. 질문과 답변의 중복을 피하세요.",
after_model_callback=after_model_callback,
tools=[]
)
def append_text_to_file(path: str, lines: str | List[str]) -> None:
# 문자열 하나를 리스트로 변환
if isinstance(lines, str):
lines = [lines]
with open(path, "a", encoding="utf-8") as f:
for line in lines:
f.write(line.rstrip() + "\n") # 줄 끝 개행을 보장
def remove_extra_format(output: str) -> str:
output = output.replace("```jsonl", "").replace("```", "").strip()
return output
# 에이전트를 실행할 입력 데이터 (예시)
input_sentence = "브루클린의 평범한 배관공 형제 '마리오'와 '루이지'는 배수관 고장으로 위기에 빠진 도시를 구하려다 미스터리한 초록색 파이프 안으로 빨려 들어가게 된다. 파이프를 통해 새로운 세상으로 차원 이동하게 된 형제. 형 마리오는 뛰어난 리더십을 지닌 '피치'가 통치하는 버섯왕국에 도착하지만 동생 루이지는 빌런 '쿠파'가 있는 다크랜드로 떨어지며 납치를 당하고 마리오는 동생을 구하기 위해 피치와 '키노피오'의 도움을 받아 쿠파에 맞서기로 결심한다. 그러나 슈퍼스타로 세상을 지배하려는 그의 강력한 힘 앞에 이들은 예기치 못한 위험에 빠지게 되는데...! 동생을 구하기 위해! 세상을 지키기 위해! '슈퍼 마리오'로 레벨업 하기 위한 마리오의 스펙터클한 스테이지가 시작된다!"
# 에이전트를 여러 번 실행하고 결과를 파일에 추가
num_runs = 300
for i in range(num_runs):
print(f"\n--- 실행 {i+1} ---")
output = root_agent.run(input_sentence)
append_text_to_file("result.jsonl", remove_extra_format(output))
print("\n작업이 완료되었습니다. 'result.jsonl' 파일을 확인하세요.")2. 실행!
한번에 여러개가 나오지는 않지만 조금씩 계속 돌리면 될 듯 하다.
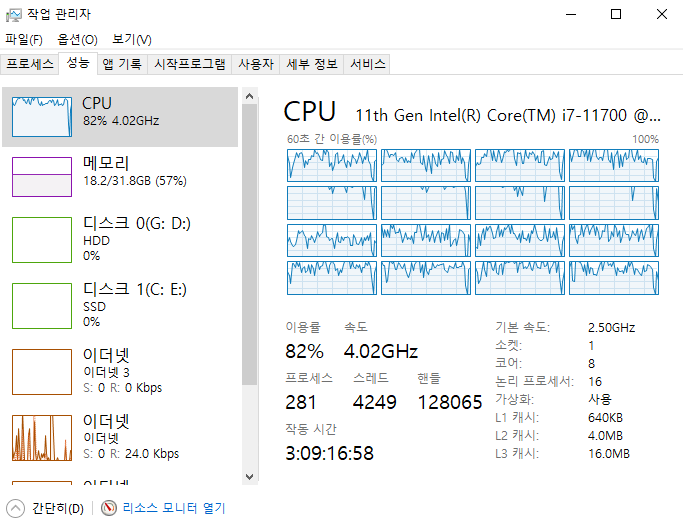
품질은 예상보다 뛰어나다! 속도는 느리지만... 회사컴퓨터로 돌려놓고 집에가서 훈련하기!
오우 완벽...
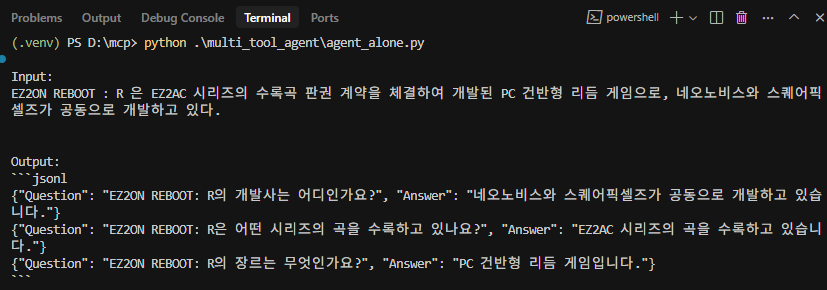
% python agent_alone.py
그러나... 자원의 한계는 역력했다...
Finally
이렇게 질문, 응답 데이터 수집 과정을 거쳤다.
여러 방법이 있었지만 결국 돈이 드는 GPT 계열 대신 google-adk Agent 를 쓰게 되었고 다행히(?) ollama 연동도 시원하게 되어서 모델 선택에도 부담이 없어졌다. (이제 장비만 있으면 된다.)

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.