1. 기다리다 늙어 죽겠다.
회사 컴퓨터로 파인튜닝을 돌려봤는데 업무 끝날때까지 Progress 화면을 보지 못했다고 한다.
기다리다 흰머리 날거같아서 빡종함.
2. cpu 만으로는 안되는건가?
perplexity 에게 물어보았다.
i7-11700 CPU(8코어/16스레드)로 1.1B 파라미터 모델을 LoRA(r=32, alpha=64) 방식으로 630개 Q/A 쌍 학습 시 예상 소요시간은 8-15시간 범위로 추정됩니다. 이는 다음과 같은 요소를 종합적으로 고려한 결과입니다:
2-1. 연산 자원 영향 요인
CPU 병렬화 효율: 16스레드 활용 시 이론적 최대 6-8배 속도 향상 가능,但 실제 학습 코드의 멀티스레딩 최적화 수준에 따라 변동
메모리 대역폭: DDR4-3200 기준 초당 45GB 처리 능력, 모델 가중치 이동에 따른 병목 발생 가능성
2-2. 모델 특성 분석
LoRA 연산량: 1.1B 모델에서 r=32 적용 시 약 0.8% 파라미터만 업데이트
배치 처리 시간: 630샘플/epoch 기준 배치 크기 32일 경우 20 step/epoch, 1회 전파(forward+backward)에 약 2-3초 소요
2-3. 시간 추정 계산식
총 소요시간 ≈ (샘플 수 × epoch 수 × 단일 샘플 처리 시간) / 병렬화 계수
≈ (630 × 5 × 3초) / 8 ≈ 8.2시간
2-4. 변동 요인
데이터 전처리 시간(임베딩 변환 등)
체크포인트 저장 주기
CPU 온도 제한으로 인한 클럭 스로틀링
메모리 교체 발생 시 추가 지연
실제 수행 시 PyTorch의 Intel MKL 최적화 빌드 사용과 배치 크기 조정(16~64)을 통해 20% 이상 시간 단축 가능. 학습 과정에서 CPU 사용률을 90% 이상 유지할 경우 상한 범위인 15시간 내 완료 가능성이 높습니다.
3. 그래서, GPU 임대서버로 결정!
3-1. vast.ai 가 가장 좋아보인다
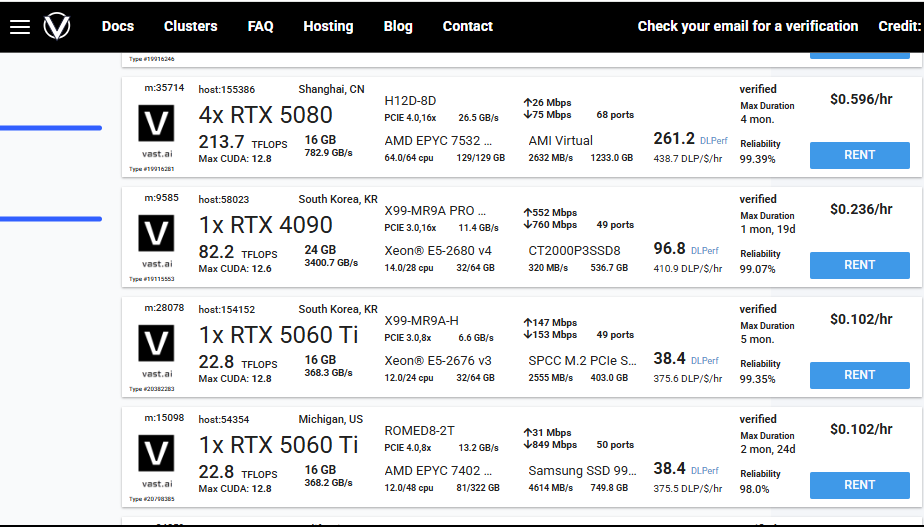
3-2. 서버 구경
1060부터 5090까지 다양하게 있다.
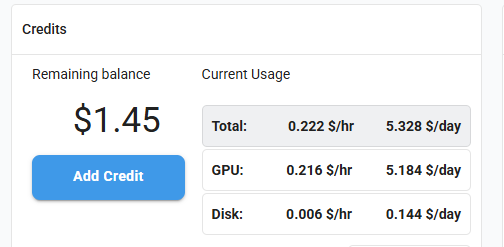
3-3. 결제는 하고 가셔야죠
카드 등록하고 5달러 충전하였다.
3-4. 결제후 RENT 하면 이런 모양새가...
3090 1개 달려있는 서버로 선택했다.
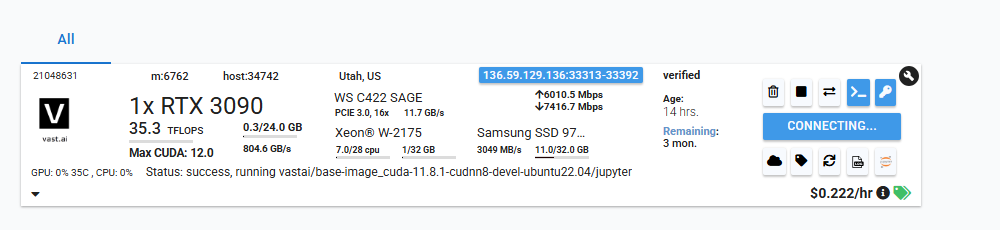
4. vast.ai SSH 설정
4-1. .ssh/id_rsa.pub 키 복사

4-2. 서버의 열쇠 모양 클릭
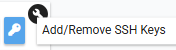
4-3. SSH Key 입력
Enter new SSH key here 에 넣고 하단의 OK 클릭
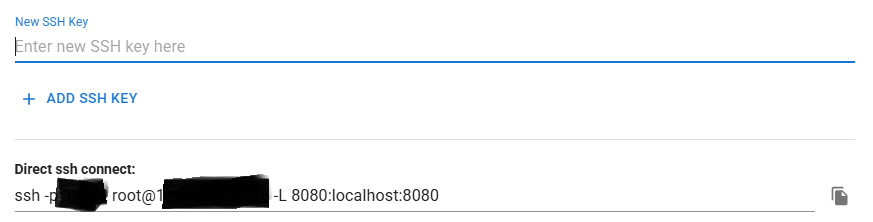
5. vscode SSH 설정
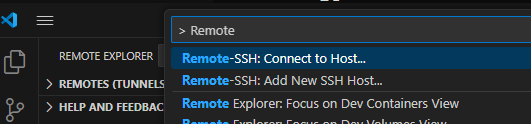
5-1. F1 > Remote-SSH: Add New SSH Host
5-2. Direct ssh connect 문자열 붙여넣기
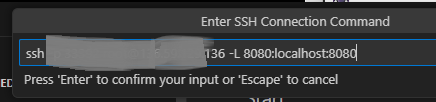
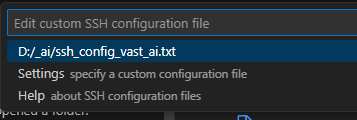
5-3. New Host 를 등록할 파일 선택
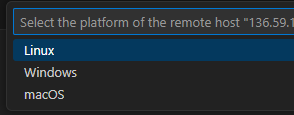
5-4. 새창이 뜨면 Linux 선택
5-5. vscode 터미널 연결 성공.
이제 마음껏 쓰면 된다.

6. 기본으로 설치 필요
% curl -Ls https://astral.sh/uv/install.sh | bash
% source $HOME/.local/bin/env
% uv pip install transformers peft torch datasets dotenv 7. 주의할 점
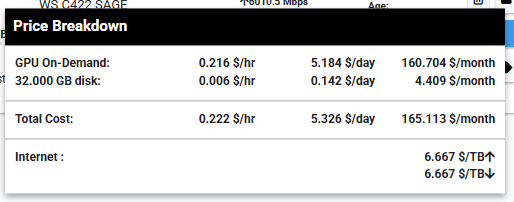
서버 오른쪽 하단에 시간당 요금을 보면 GPU On-Demand 와 disk 요금이 별도로 있는데
GPU를 다 쓰면 반드시 인스턴스를 종료하고 아예 쓸모없는 경우에는 삭제를 해야 요금이 나가지 않는다.
7. 결론
요즘 그래픽카드 비싸고 전기도 많이 먹는데 임대를 해보는건 어떤가?
10달러만 써도 재밌게 갖고 놀만 하다.
