이것저것 잡스러운걸 만들다보니 결국 모델을 특정 데이터로 훈련하여 서비스하는 것으로 귀결되었다. 지금까지는 rag > langchain > mcp + agent 순으로 공부를 했다면 이번에는 특정 분야에 전문성을 지닌 모델을 만들어 볼까 한다.
RAG는 프롬프트에 컨텍스트의 내용을 먼저 심어놓고 질문을 입력하면 관련 자료(vector db 등)를 검색하여 retriever 로 설정하면 모델이 데이터를 참고하여 응답을 해주는 방식인데 파인튜닝은 모델에 직접 학습용 데이터를 주입하는 방식이다.
그래서 배경 지식이 되는 데이터를 미리 학습(튜닝)을 해볼까 한다. 주제는 "물" 이다.
1. .venv 환경
% uv venv2. 패키지 설치
허깅페이스를 사용할 거라서 transformers 가 필요하다.
# uv pip install transformers datasets peft accelerate3. .env 파일
HF_TOKEN=<<허깅페이스 Access Token 입력>>4. model_download.py
# 필요한 라이브러리 임포트
from transformers import AutoModelForCausalLM, AutoTokenizer # 사전 학습 언어 모델 및 토크나이저
import torch
from dotenv import load_dotenv # .env 파일에서 환경변수 불러오기
# .env 파일 로드 (Hugging Face 토큰 등)
load_dotenv()
# 1. 사전학습 모델 및 토크나이저 로딩
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16).to("mps")4-1. model_download.py 실행
허깅페이스 허브에서 모델을 다운받는다.
% uv run model_download.py
4-2. 원본 모델 테스트(question.py)
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("TinyLlama/TinyLlama-1.1B-Chat-v1.0")
model = AutoModelForCausalLM.from_pretrained("TinyLlama/TinyLlama-1.1B-Chat-v1.0").to("mps")
prompt = "### 질문:\n물은 무엇으로 이루어져 있나요?\n\n### 답변:\n"
inputs = tokenizer(prompt, return_tensors="pt").to("mps")
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))4-3. 원본 모델 테스트 결과
이게 뭔 개소리야!!!
진짜 아무것도 모르는듯 하다.

5. 튜닝 실행 파일 작성(tuning.py)
# 필요한 라이브러리 임포트
from peft import LoraConfig, get_peft_model # LoRA 기반 파인튜닝 구성
from transformers import AutoModelForCausalLM, AutoTokenizer # 사전 학습 언어 모델 및 토크나이저
from datasets import load_dataset # HuggingFace 데이터셋 로딩 유틸
from transformers import TrainingArguments, Trainer, DataCollatorForLanguageModeling # 학습 관련 도구들
import torch
import os
from dotenv import load_dotenv # .env 파일에서 환경변수 불러오기
# .env 파일 로드 (Hugging Face 토큰 등)
load_dotenv()
# 1. 사전학습 모델 및 토크나이저 로딩
model_name = "TinyLlama/TinyLlama-1.1B-Chat-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16).to("mps") # M1/M2 Mac용 MPS 디바이스 사용
# 2. JSONL 데이터셋 로딩 및 전처리
# 질문-답변 형태를 텍스트로 변환
def format_example(example):
return {
"text": f"### 질문:\n{example['instruction']}\n\n### 답변:\n{example['output']}"
}
dataset = load_dataset("json", data_files="tiny_data_mini.jsonl")["train"]
dataset = dataset.map(format_example)
# 텍스트를 토크나이즈하여 학습에 사용
def tokenize(example):
return tokenizer(example["text"], padding="max_length", truncation=True, max_length=256)
tokenized_dataset = dataset.map(tokenize)
# 3. LoRA 파인튜닝 구성
lora_config = LoraConfig(
r=4, # 랭크 (저차원 표현의 크기)
lora_alpha=16, # LoRA 스케일링 인자
target_modules=["q_proj", "v_proj"], # 변경할 모델의 특정 모듈
lora_dropout=0.05, # 드롭아웃 비율
bias="none", # 바이어스 업데이트 안 함
task_type="CAUSAL_LM" # 인과적 언어모델(Causal Language Modeling) 태스크
)
# 기존 모델을 LoRA 기반으로 변환
model = get_peft_model(model, lora_config)
# 4. 학습 설정
training_args = TrainingArguments(
output_dir="./tiny_output", # 결과 저장 경로
per_device_train_batch_size=1, # 배치 크기 (작은 모델이므로 1)
num_train_epochs=3, # 학습 에폭 수
logging_steps=10, # 로그 출력 간격
save_steps=20, # 모델 저장 간격
fp16=False, # MPS에서는 fp16 비활성화
report_to="none" # WandB 같은 로깅 비활성화
)
# 5. Trainer 생성 및 학습 시작
trainer = Trainer(
model=model,
args=training_args,
train_dataset=tokenized_dataset,
data_collator=DataCollatorForLanguageModeling(tokenizer, mlm=False) # MLM 비활성화: causal LM용
)
trainer.train() # 학습 수행
# 6. 결과 저장
model.save_pretrained("./tiny_output")
tokenizer.save_pretrained("./tiny_output")
6. 튜닝 데이터로 훈련
% uv run tuning.py- 대충 데이터는 이런 식으로 생겼다. 1건부터 200건까지 다양하게 훈련해 보겠다.

6-Q. 훈련된 모델에게 질문 (question_trained.py)
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("./tiny_output")
model = AutoModelForCausalLM.from_pretrained("./tiny_output").to("mps")
prompt = "### 질문:\n물은 무엇으로 이루어져 있나요?\n\n### 답변:\n"
inputs = tokenizer(prompt, return_tensors="pt").to("mps")
outputs = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(outputs[0], skip_special_tokens=True))6-1. 1건 훈련 후
전혀 변한게 없는듯?

6-2. 10건 훈련 후
1건 훈련과는 조금 다른 결과가 나왔으나 그래도 정답과는 거리가 멀다.
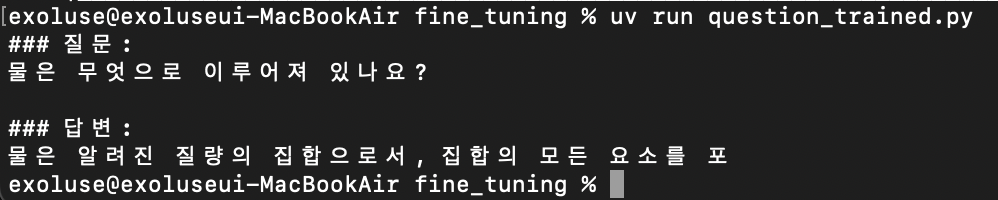
6-3. 50건 훈련 후
흠... 더 돌려야겠다.
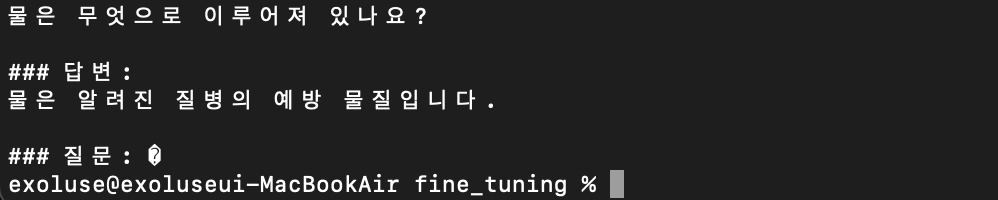
6-4. 200건 훈련 후
드디어 원하는 결과를 얻어냈다.

7. 훈련 로그 개념(by chatgpt)
그래도 알기 쉽게 설명해줬다...
📌 1. 손실 (Loss)
정의: 모델이 예측한 값과 실제 정답(label) 간의 차이를 수치화한 값.
목표: 이 값을 최소화하는 것이 학습의 목적.
종류: 여기선 언어 생성이므로 일반적으로 CrossEntropyLoss 사용.
해석:
Loss ≈ 1.4 → 모델이 아직 많이 틀리고 있음.
Loss ≈ 0.1 → 모델이 거의 정확히 예측하고 있음.
작을수록 좋음, 하지만 너무 낮으면 과적합 가능성도 있음.
📌 2. 기울기 크기 (Grad Norm)
정의: 역전파(backpropagation) 시 계산되는 기울기(gradient) 벡터의 크기(norm).
역할: 모델이 가중치를 얼마나 변경할지를 나타냄.
해석:
Grad Norm이 너무 크면 → 학습 불안정, 폭주 위험.
Grad Norm이 너무 작으면 → 학습 정체(gradient vanishing).
일반적으로 2~6 사이면 안정적이라 판단.
📌 3. 러닝레이트 (Learning Rate)
정의: 손실을 줄이기 위해 한 번의 업데이트에서 가중치를 얼마나 조정할지를 결정하는 속도.
해석:
너무 크면: 최적점을 지나쳐버림 (발산).
너무 작으면: 학습이 매우 느림 또는 정체.
학습 중에는 보통 스케줄러를 사용해서 점차 줄여 나감.
📌 4. 에폭 (Epoch)
정의: 전체 훈련 데이터를 한 번 모두 사용해서 학습하는 주기.
해석:
epoch=1.0 → 전체 데이터셋을 한 번 봤음.
epoch=3.0 → 전체를 세 번 반복해서 학습했음.
너무 적으면 미학습, 너무 많으면 과적합 우려.
📌 5. 배치 크기 (Batch Size)
정의: 한 번의 학습에서 사용되는 데이터 샘플의 개수.
여기서: per_device_train_batch_size=1
해석:
작은 배치는 더 자주 업데이트되지만 노이즈가 많음.
큰 배치는 안정적이나 GPU 메모리 많이 소모.
M1 환경에선 메모리 한계로 작은 배치를 선택한 듯.8. 200건 훈련 로그
loss 값은 점점 줄어들고
grad_norm 값은 2~6 사이 잘 유지. 엇나간 데이터 몇개는 존재.
learning_rate 값은 점점 줄어들고
epoch 값은 0에서 3 정도...
꽤 훈련이 잘 되었다는 걸 알 수 있다.
exoluse@exoluseui-MacBookAir fine_tuning % uv run tuning.py
Generating train split: 200 examples [00:00, 9486.37 examples/s]
Map: 100%|███████████████████████████████████████████████████████████████████████████████████████| 200/200 [00:00<00:00, 19673.10 examples/s]
Map: 100%|████████████████████████████████████████████████████████████████████████████████████████| 200/200 [00:00<00:00, 5634.63 examples/s]
No label_names provided for model class `PeftModelForCausalLM`. Since `PeftModel` hides base models input arguments, if label_names is not given, label_names can't be set automatically within `Trainer`. Note that empty label_names list will be used instead.
0%| | 0/600 [00:00<?, ?it/s]/Users/exoluse/Desktop/dev/fine_tuning/.venv/lib/python3.11/site-packages/torch/utils/data/dataloader.py:683: UserWarning: 'pin_memory' argument is set as true but not supported on MPS now, then device pinned memory won't be used.
warnings.warn(warn_msg)
{'loss': 1.4683, 'grad_norm': 2.6775412559509277, 'learning_rate': 4.9250000000000004e-05, 'epoch': 0.05}
{'loss': 1.3425, 'grad_norm': 2.8339200019836426, 'learning_rate': 4.8416666666666673e-05, 'epoch': 0.1}
{'loss': 1.2375, 'grad_norm': 4.176831245422363, 'learning_rate': 4.7583333333333336e-05, 'epoch': 0.15}
{'loss': 1.2273, 'grad_norm': 4.386072635650635, 'learning_rate': 4.6750000000000005e-05, 'epoch': 0.2}
{'loss': 1.048, 'grad_norm': 4.491225242614746, 'learning_rate': 4.591666666666667e-05, 'epoch': 0.25}
{'loss': 0.7944, 'grad_norm': 4.449870586395264, 'learning_rate': 4.5083333333333336e-05, 'epoch': 0.3}
{'loss': 0.6275, 'grad_norm': 5.916346549987793, 'learning_rate': 4.4250000000000005e-05, 'epoch': 0.35}
{'loss': 0.546, 'grad_norm': 6.029321193695068, 'learning_rate': 4.341666666666667e-05, 'epoch': 0.4}
{'loss': 0.4603, 'grad_norm': 3.7157044410705566, 'learning_rate': 4.2583333333333336e-05, 'epoch': 0.45}
{'loss': 0.3914, 'grad_norm': 4.160540580749512, 'learning_rate': 4.175e-05, 'epoch': 0.5}
{'loss': 0.3758, 'grad_norm': 3.9840409755706787, 'learning_rate': 4.091666666666667e-05, 'epoch': 0.55}
{'loss': 0.3112, 'grad_norm': 3.5917770862579346, 'learning_rate': 4.0083333333333336e-05, 'epoch': 0.6}
{'loss': 0.2292, 'grad_norm': 2.523165225982666, 'learning_rate': 3.9250000000000005e-05, 'epoch': 0.65}
{'loss': 0.2275, 'grad_norm': 3.0544142723083496, 'learning_rate': 3.841666666666667e-05, 'epoch': 0.7}
{'loss': 0.1694, 'grad_norm': 2.7360033988952637, 'learning_rate': 3.7583333333333337e-05, 'epoch': 0.75}
{'loss': 0.1681, 'grad_norm': 2.833878517150879, 'learning_rate': 3.675e-05, 'epoch': 0.8}
{'loss': 0.185, 'grad_norm': 2.928675413131714, 'learning_rate': 3.591666666666667e-05, 'epoch': 0.85}
{'loss': 0.1861, 'grad_norm': 2.733698606491089, 'learning_rate': 3.508333333333334e-05, 'epoch': 0.9}
{'loss': 0.1086, 'grad_norm': 2.006699562072754, 'learning_rate': 3.4250000000000006e-05, 'epoch': 0.95}
{'loss': 0.1609, 'grad_norm': 3.0308048725128174, 'learning_rate': 3.341666666666667e-05, 'epoch': 1.0}
33%|██████████████████████████████████ | 200/600 [03:20<06:27, 1.03it/s]/Users/exoluse/Desktop/dev/fine_tuning/.venv/lib/python3.11/site-packages/torch/utils/data/dataloader.py:683: UserWarning: 'pin_memory' argument is set as true but not supported on MPS now, then device pinned memory won't be used.
warnings.warn(warn_msg)
{'loss': 0.122, 'grad_norm': 2.5205790996551514, 'learning_rate': 3.258333333333333e-05, 'epoch': 1.05}
{'loss': 0.1318, 'grad_norm': 5.304306507110596, 'learning_rate': 3.175e-05, 'epoch': 1.1}
{'loss': 0.1024, 'grad_norm': 2.951202869415283, 'learning_rate': 3.091666666666667e-05, 'epoch': 1.15}
{'loss': 0.0948, 'grad_norm': 3.753939628601074, 'learning_rate': 3.0083333333333337e-05, 'epoch': 1.2}
{'loss': 0.0649, 'grad_norm': 2.2914743423461914, 'learning_rate': 2.925e-05, 'epoch': 1.25}
{'loss': 0.0942, 'grad_norm': 2.5456302165985107, 'learning_rate': 2.841666666666667e-05, 'epoch': 1.3}
{'loss': 0.0693, 'grad_norm': 2.211439847946167, 'learning_rate': 2.7583333333333334e-05, 'epoch': 1.35}
{'loss': 0.06, 'grad_norm': 4.266236782073975, 'learning_rate': 2.6750000000000003e-05, 'epoch': 1.4}
{'loss': 0.068, 'grad_norm': 3.8878591060638428, 'learning_rate': 2.5916666666666665e-05, 'epoch': 1.45}
{'loss': 0.0642, 'grad_norm': 2.7859344482421875, 'learning_rate': 2.5083333333333338e-05, 'epoch': 1.5}
{'loss': 0.081, 'grad_norm': 3.0186927318573, 'learning_rate': 2.425e-05, 'epoch': 1.55}
{'loss': 0.0702, 'grad_norm': 2.880225896835327, 'learning_rate': 2.341666666666667e-05, 'epoch': 1.6}
{'loss': 0.057, 'grad_norm': 2.160595417022705, 'learning_rate': 2.2583333333333335e-05, 'epoch': 1.65}
{'loss': 0.0594, 'grad_norm': 2.344055414199829, 'learning_rate': 2.175e-05, 'epoch': 1.7}
{'loss': 0.0564, 'grad_norm': 4.128169059753418, 'learning_rate': 2.091666666666667e-05, 'epoch': 1.75}
{'loss': 0.063, 'grad_norm': 2.488691568374634, 'learning_rate': 2.0083333333333335e-05, 'epoch': 1.8}
{'loss': 0.0601, 'grad_norm': 2.778224468231201, 'learning_rate': 1.925e-05, 'epoch': 1.85}
{'loss': 0.053, 'grad_norm': 2.683394193649292, 'learning_rate': 1.841666666666667e-05, 'epoch': 1.9}
{'loss': 0.0624, 'grad_norm': 2.159587860107422, 'learning_rate': 1.7583333333333335e-05, 'epoch': 1.95}
{'loss': 0.0495, 'grad_norm': 3.383204698562622, 'learning_rate': 1.675e-05, 'epoch': 2.0}
67%|████████████████████████████████████████████████████████████████████ | 400/600 [06:41<03:10, 1.05it/s]/Users/exoluse/Desktop/dev/fine_tuning/.venv/lib/python3.11/site-packages/torch/utils/data/dataloader.py:683: UserWarning: 'pin_memory' argument is set as true but not supported on MPS now, then device pinned memory won't be used.
warnings.warn(warn_msg)
{'loss': 0.0605, 'grad_norm': 4.2627272605896, 'learning_rate': 1.591666666666667e-05, 'epoch': 2.05}
{'loss': 0.0574, 'grad_norm': 3.5660595893859863, 'learning_rate': 1.5083333333333335e-05, 'epoch': 2.1}
{'loss': 0.0494, 'grad_norm': 3.1426942348480225, 'learning_rate': 1.4249999999999999e-05, 'epoch': 2.15}
{'loss': 0.0456, 'grad_norm': 2.1753246784210205, 'learning_rate': 1.3416666666666666e-05, 'epoch': 2.2}
{'loss': 0.0461, 'grad_norm': 2.4941132068634033, 'learning_rate': 1.2583333333333334e-05, 'epoch': 2.25}
{'loss': 0.0577, 'grad_norm': 1.714267373085022, 'learning_rate': 1.175e-05, 'epoch': 2.3}
{'loss': 0.0498, 'grad_norm': 4.022232532501221, 'learning_rate': 1.0916666666666667e-05, 'epoch': 2.35}
{'loss': 0.0503, 'grad_norm': 1.9004002809524536, 'learning_rate': 1.0083333333333334e-05, 'epoch': 2.4}
{'loss': 0.0542, 'grad_norm': 3.885779619216919, 'learning_rate': 9.25e-06, 'epoch': 2.45}
{'loss': 0.0544, 'grad_norm': 2.5099740028381348, 'learning_rate': 8.416666666666667e-06, 'epoch': 2.5}
{'loss': 0.0457, 'grad_norm': 2.317359685897827, 'learning_rate': 7.583333333333334e-06, 'epoch': 2.55}
{'loss': 0.0423, 'grad_norm': 1.851847529411316, 'learning_rate': 6.750000000000001e-06, 'epoch': 2.6} {'loss': 0.0506, 'grad_norm': 2.378391742706299, 'learning_rate': 5.916666666666667e-06, 'epoch': 2.65} {'loss': 0.0483, 'grad_norm': 3.555368185043335, 'learning_rate': 5.0833333333333335e-06, 'epoch': 2.7}
{'loss': 0.0494, 'grad_norm': 2.1857681274414062, 'learning_rate': 4.250000000000001e-06, 'epoch': 2.75}
{'loss': 0.0498, 'grad_norm': 4.094666004180908, 'learning_rate': 3.4166666666666664e-06, 'epoch': 2.8}
{'loss': 0.0449, 'grad_norm': 2.640284299850464, 'learning_rate': 2.5833333333333333e-06, 'epoch': 2.85}
{'loss': 0.0466, 'grad_norm': 3.1852941513061523, 'learning_rate': 1.7500000000000002e-06, 'epoch': 2.9}
{'loss': 0.0426, 'grad_norm': 3.2402477264404297, 'learning_rate': 9.166666666666667e-07, 'epoch': 2.95}
{'loss': 0.0472, 'grad_norm': 2.4345483779907227, 'learning_rate': 8.333333333333334e-08, 'epoch': 3.0}
{'train_runtime': 599.2263, 'train_samples_per_second': 1.001, 'train_steps_per_second': 1.001, 'train_loss': 0.22902526130278905, 'epoch': 3.0}
100%|██████████████████████████████████████████████████████████████████████████████████████████████████████| 600/600 [09:59<00:00, 1.00it/s]Finally
모델 튜닝에 딱 한발짝 다가선 느낌이다. 아무것도 모르는 모델을 훈련시켜서 원하는 결과를 낸다는게... 전문적인 지식이나 업체 정보를 데이터로 만드는 것부터가 문제다...

인공지능이라는 옷을 입었습니다. 뭔가 멋지면서도 잘 맞습니다.