Kakao Cloud School
1.0831(수) 리눅스 1
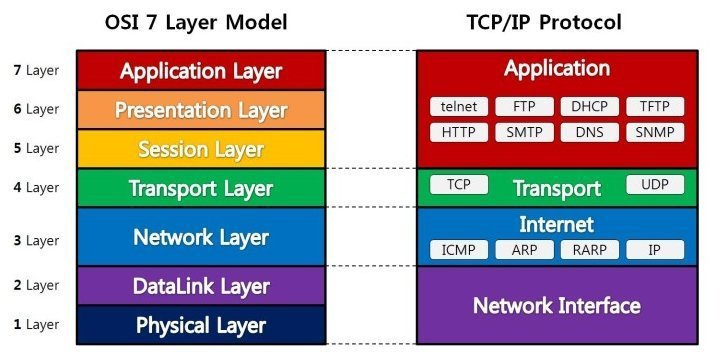
Linux Server, Serverless : 서버 구성없이도 애플리케이션을 배포할 수 있다. Linux 환경 or Serverless 환경 => 두개를 묶어서 MSA(MicroService Architecture)모든 서비스를 컨테이너로 만들어서 의존성과 종속성으로
2.9/1(목) 리눅스2

로그인 과정 인증(AuthN) -> ID(/etc/passwd), Pwd(/etc/shadow) 검증 수행 -> 접근 허용/비허용 : 암호 인증은 /etc/shadow에서 진행한다.유저 july 생성/etc/passwd 에 새로운 유저가 july가 추가됨 /etc/sh
3.09/02(금) 리눅스3
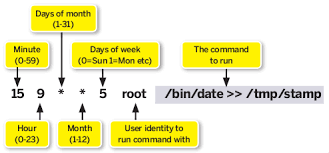
프로세스 프로세스 = 커널이 할당하고 메모리에서 일하는 일꾼 fork 함수에 의해 프로세스가 할당된다. automatic(프로그램에 의해서 움직이는 것), autonomous(자율) 프로세스의 개념 프로세스 : 현재 시스템에서 실행중인 프로그램 코드(job)이 내
4.09/05(월) 리눅스 4
시스템 Booting & shutdown 부트로더 단계 : LILO, GRUB systemd 서비스 단계: 최상위 프로세스 (PID = 1) 1) BIOS (Basic Input Output System) PC에 장착된 하드웨어의 상태 확인(키보드, 디스크 등등)
5.09/06(화) 리눅스 5

CentOS7에 MariaDB 설치하기vim /etc/yum.repos.d/MariaDB.repo 작성yum -y install MaraiDB-server MariaDB-clientservice mysql startsystemctl start mysql.service쉘
6.09/07(수) 도커1

현대화된 애플리케이션모든 서비스를 컨테이너로 구현할 수 있다.LXC (LinuX Containers)\-> 구현이 매우 복잡 가상화 발전 linux 프로세스 격리virtual machine 가상화 기술container 가상화 기술 container orchestrati
7.09/08(금) 도커 2
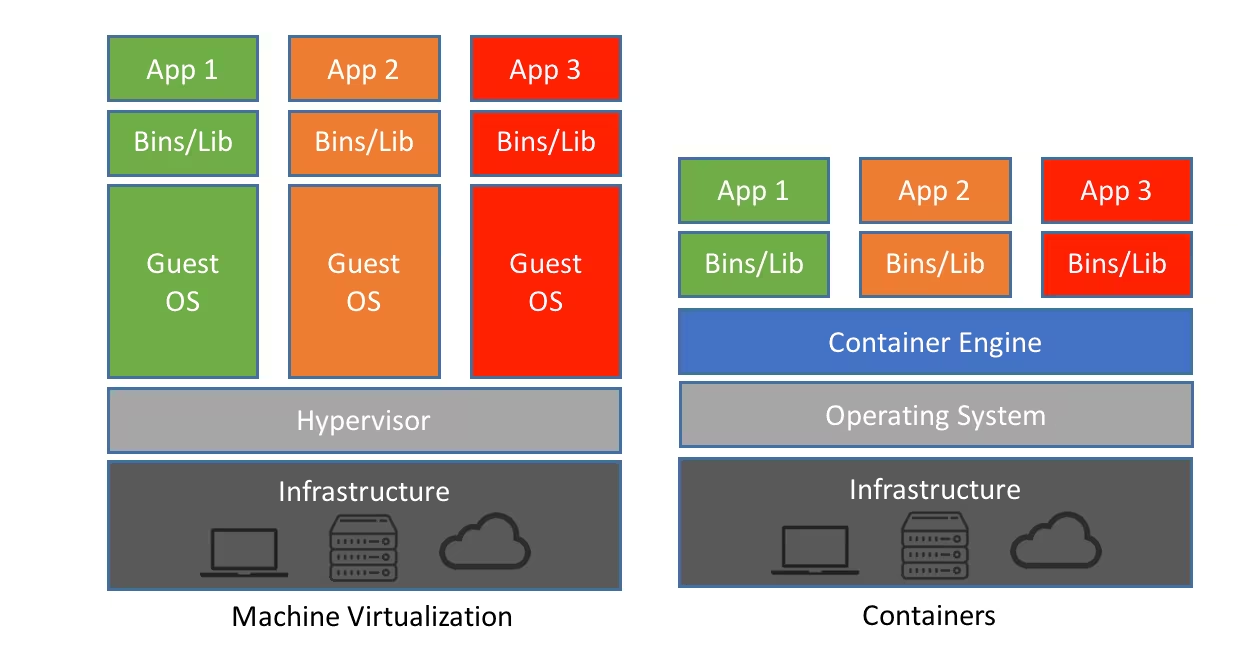
왜 도커를 사용하는가?복잡한 linux application을 여러 Container로 통합하여 실행할 수 있음 -> microservice개발, 테스트, 서비스 환경을 하나로 통합하여 효율적 관리가 가능하다 ! 통합 : 하나로 합친다 X, 개발 테스트 서비스가 모두
8.0913(화) - 도커3

docekr ps 0.0.0.0:9559->8080/tcp -> IPv4 :::9559->8080/tcp -> :(세미콜론)나오면 IPv6port 이렇게 변환해주는 기술이 NAT, ? docker에서는 docker proxy가 담당한다. treesudo apt -y
9.0914(수) - 도커4
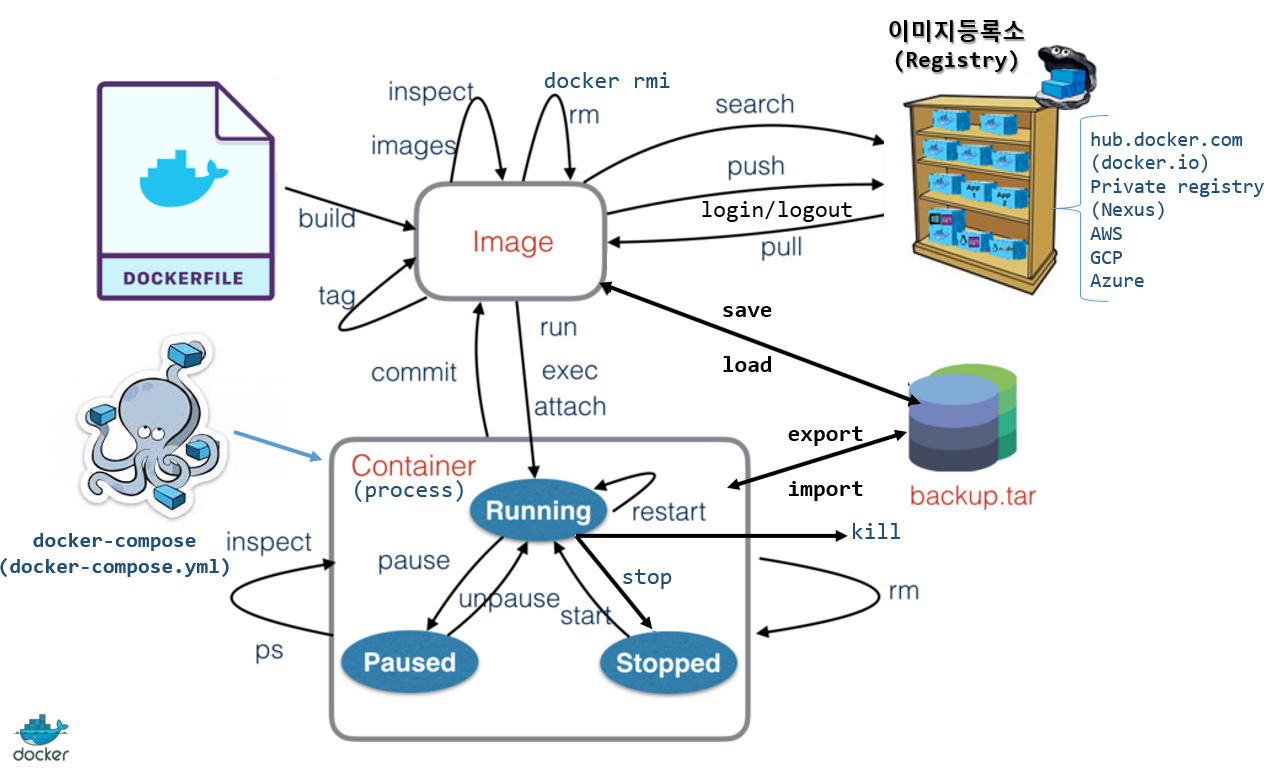
cexrm : alias로 확인할 수 있다.linux kill -> kill -9 \[PID] : 프로세스 강제 종료 ( session kill)docker kill -> force shutdown (강제 종료) -> 9) SIGKILLdocker stop -> gra
10.0915(목) - 도커5
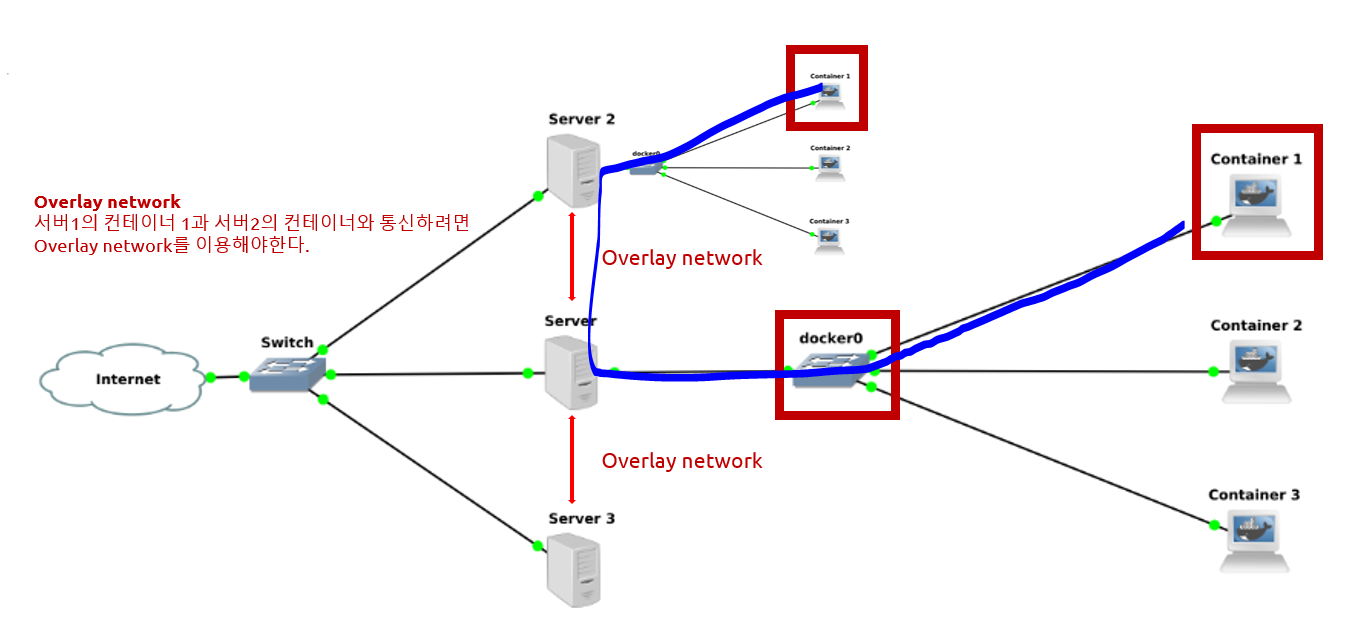
docker swarm, overlaySwarm: inactive -> kubernetes와 같은 orchestration 기능 docker network create switch -> 로드밸런싱 한다. server 3개 묶여있는 애들 = target groupswi
11.0916(금) - 도커 6
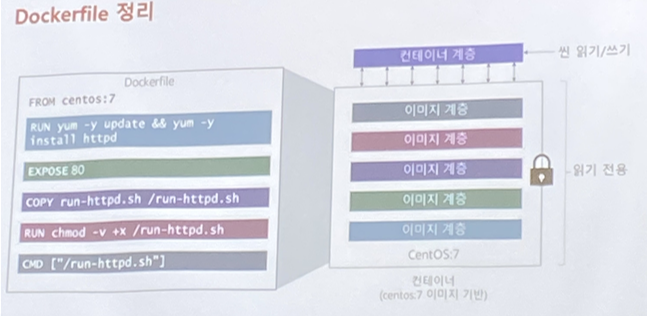
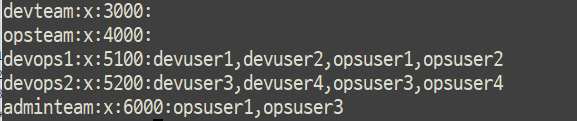
컨테이너 : All Denied 0) 개발팀 요청 -> 분석 -> OS, Package, ENV ... -> 작업 계획서 작성1) Dockerfile 작성 -> ⭐ build (build 과정 잘 보기) -> 빌드 성공과 실패 확인2) docker run 컨테이너 테스
12.09/29(목) 쿠버네티스 1

for Microservice설치 3번할거임 vm에 4대를 올림. 최소용량 => 100GB, ubuntu, 다다음주 월요일 발표OS세팅 -> 도커(container engine=dockerd, containerd,runC) 설치 -> 쿠버네티스 설치왜 도커 먼저 설치?
13.09/30(금) 쿠버네티스2

할 일 버전 업그레이드 ! 6443 포트 : kube-apiserver 📕 GKE Dashboard 연결 kube proxy로 연결한다 ! 📗 Kubernetes Components -> 5 binary components 아직 프로메테우스랑 그라파나 구축 X
14.10/04(화) 쿠버네티스3

VM 일시 정지 후 다시 연결하면 data 시간 동기화 해주세요 sudo rdate -s time.bora.netPod (기본 배포 단위)application 배포를 위해 컨테이너를 띄우고 이를 관리하기위해 쿠버네티스는 Pod 단위로 배포한다.ReplicaSet ->
15.10/5(수) 쿠버네티스4

멀티컨테이너 파드 -> ? pod cnt(large cluster) ---> QoSnode / 110 ~ 5000(max)all node -> 150,000개all container -> 300,000개4대 리소스cpu + memory + disk + networkno
16.10/06(목) 쿠버네티스5
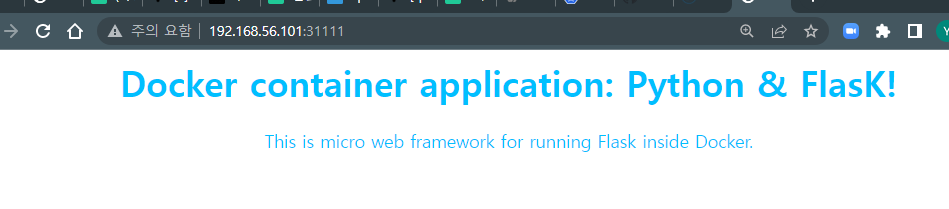
docker container 내부 용량 제한은 \--storage-opt size => /mount된 dir의 용량을 제어는 dd명령 임시 파일 -> fdisk -> mount단, 이 방법의 단점은 OS 의존적 쿠버네티스는 PV. PVC로 OS 의존적인 문제를 보완한
17.10/7 (금) 쿠버네티스6

secret 프로젝트에 넣으세요인증서 만들고 ~ 상위 추상화 개념Pod, Depolyment는 stateless object <-> stateful objectReplicaSet(rs). (old) REplication controller(rc)pod 복제 ->
18.10/11일(화) 쿠버네티스 7

cluster의 모든 node에 pod를 하나씩 배포하는 controller컨트롤러는 pall로 확인가능node-exoprter의 정체가 deamon set어떤 용도로 사용?주로 로그 수집기, 모니터링을 목적으로 사용prometheus / grafana = metric
19.10/13(목) 클라우드1

상암에서 300GB를 인터넷망으로 다른 곳에 옮길거야 -> 1시간 ~ 1시간 30분정도 걸린다. 근데 aws의 direct connect를 쓰면 300GB가 10분에 끝난다. 💭 Amazon S3 버킷에 최대한 빨리 집게하려고합니다. 솔루션은 운영 복잡성을 최소화해야
20.10/14(금) 클라우드2

📘Infrastructure 선택기준 리전이 해안가에 몰려있는 이유: 해저 광 케이블 때문 Region : 최종 사용자에게 더 가까운 위치에 특정 고객의 위치를 파악하여 근접 지역을 선택 전송 비용 최소화 서비스 관점에서 클라우드는 전송 비용(= 네
21.10/17(월) 클라우드3

감사(Audit) 도구 -> 책임소재의 명확성을 위해 on-demand : 워크로드가 일정하지 않을 때 spot-instance : 워크로드가 일정할 때,saving plan은 컴퓨터 리소스에 대한 예약 예약 인스턴스는 인스턴스에 대한 예약 고정 ip -> elasti
22.10/18(화) 클라우드4-스토리지

s3의 상위 개념이 ebs? -> XXXefs는 파일시스템s3는 오브젝트 스토리지어떻게하면 고가용성을 보장하면서 스토리지 비용을 최적화하고 보안을 제공할 수 있습니까? \-> 이건 우리가 답 찾으세요 일단 보안을 위해서는 암호화, 비용과 trade-off 관계오래된 이
23.10/19(수) - 클라우드5

\-> 여기까지하고 생성 ! VPC 대시보드에서 확인 ! 서브넷도 확인 가용영역도 확인! (a랑 c만 존재하는가 라우팅테이블 확인public은 라우팅에 igw와 연결되어있고private는 라우팅에 nat랑 연결되어있다. IGWNAT 게이트웨이 MYSQL/Aurora 추
24.10/20(목) 클라우드 6

 클라우드 7

사전 징후 감지를 통한 예방 운영 상태 : 시스템 전반에 대해애플리케이션 성능: 처리 속도 (응답 시간)리소스 활용: 임계값(기준 지표) 초과 여부 파악 -> 일시적인 현상인지 지속적인 현상인지 분석보안 감사: 규정 준수 여부비용 검사: 비용 효율적/ 절감 서비스 설계
26.10/27(목) 엘라스틱서치 1

엘라스틱서치는 검색엔진 DBMS 이다.구조 json저장된 데이터를 분석 -> 검색엔진json 형태라 조회는 REST API로 진행한다. (get, post ...)우리는 Elasticsearch 를 OpenSearch로 이용한다. 둘 다 클러스터왜 클러스터? 분산 왜
27.10/28(금) 엘라스틱서치2
index (= table)alias : 분리된 log data를 하나로 묶고 싶을 경우 reindex아래와 같이 sshd_fail 인덱스가 2개가 생겼으면 성공~이제 이걸 합쳐보자 유통 -> 쿠팡, 11번가, 롯데닷컴, 신세계, 마켓컬리 ...집계, 통계, 분석 ->