ML/DL
1.[스터디 내용 정리] 0. 스터디 방향

초과 학기가 시작됐다.조금 늦은 감이 있지만 딥러닝 스터디를 시작하기로 했다.일단 인공지능 공부하는 동아리에 들어갔는데 인원이 50여 명 정도로 꽤 많았다.동아리 내부에서 자율적으로 그룹을 꾸려 스터디를 시작하는 형식이다.나는 밑바닥부터 시작하는 딥러닝 3권 스터디를
2.[스터디 내용 정리] step01. 상자로서의 변수
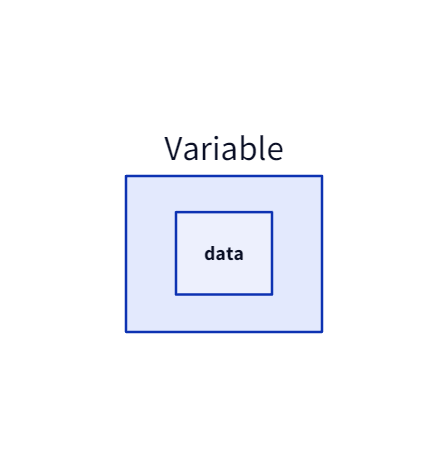
이 책에서 구현하는 코드는 객체 지향으로 특히 캡슐화(encapsulation)와 다형성(Polymorphism)에 무게를 두고 있다.그중 캡슐화에 첫 단계인 1고지는 Variable과 Function 클래스 구현이 중심이다.Variable은 Function과 상호작용
3.[스터디 내용 정리] step02. 변수를 낳는 함수
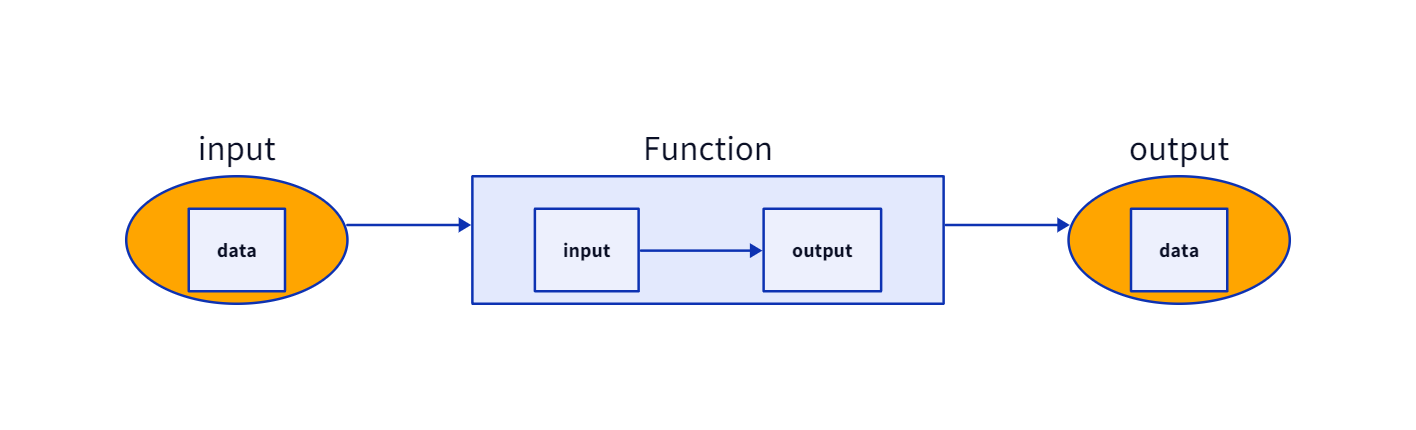
지난 step에서 변수를 Variable 클래스로 간단하게 구현했다.이번 step에는 함수를 Function 클래스로 구현한다.함수의 수학적 정의도 좋지만, 좀 더 직관으로 바라보자.함수는 입/출력의 관계이다.함수 내부에 자체적인 연산을 포함해서 그림으로 표현하면 다음
4.[스터디 내용 정리] step03. 함수 연결
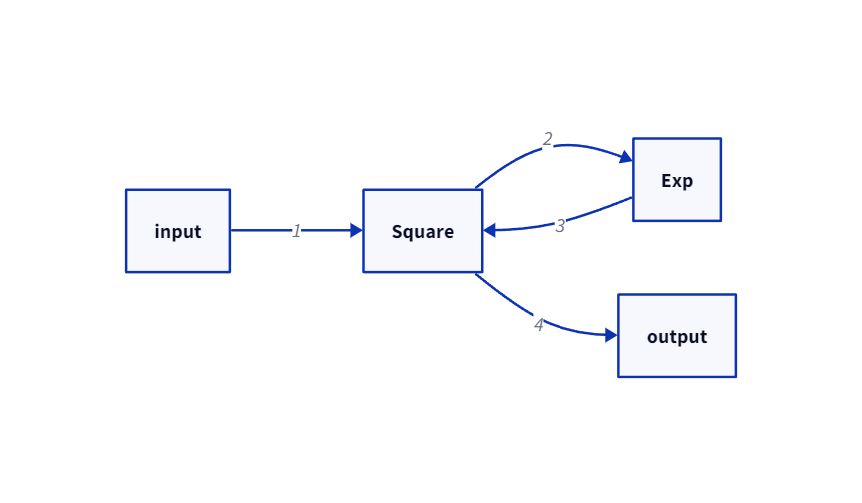
지난 step에서 함수를 나타내는 Function 클래스와 이를 상속받아 실제 연산하는 Square 클래스를 구현했다.이번 step에서는 또 다른 실제 연산 클래스를 구현하고 두 클래스간의 연결을 수행한다.${y} = {e}^{x}$를 Exp 클래스로 구현하자.여기서
5.[스터디 내용 정리] step04. 수치 미분
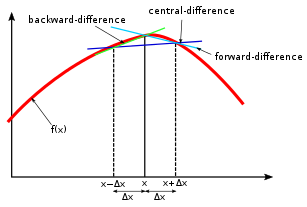
미분 계수의 정의는 다음과 같다.$f'({x}) = \\displaystyle\\lim\_{h\\to 0}{f({x+h}) - f({x})\\over h}$이를 프로그램으로 구현한다면 $\\displaystyle\\lim\_{h\\to 0}$ 부분이 문제가 생긴다.수치
6.키워드 기반 보고서 자동화 모델

아는 지인 분과 이야기하다가 크몽에서 대학 과제를 대신 해준다는 이야기가 나왔다. 특정 키워드로 보고서를 작성하는 과제가 많은데, 지인 분은 키워드에 해당하는 뉴스 기사를 모으고 chatGPT를 거쳐 약간의 수정을 통해 만든다고 했다.이 이야기를 들으며 자동화 아이디어
7.chatGPT에게 물어본 신입 머신러닝 엔지니어 면접 문항 50개
머신러닝과 딥러닝의 차이점은 무엇인가요? 머신러닝은 딥러닝의 상위 개념, 머신러닝은 데이터와 정답(레이블)을 통해 규칙을 찾는 모델인 반면, 딥러닝은 인공신경망 층이 쌓인 머신러닝 모델 지도학습과 비지도학습의 차이점은 무엇인가요? 둘 다 데이터셋을 활용하여 학습함. 지
8.Boosting 모델의 종류
본 포스팅은 김성범 교수님의 유튜브 강좌, 강필성 교수님의 유튜브 강좌, Kicarus 티스토리를 참고했습니다.여러 개의 learning 모델을 순차적으로 구축하여 최종적으로 합침(Ensemble)여기서 사용하는 learning 모델은 매우 단순한 모델: 정확도가 0.
9.유튜브 추천 시스템 모델 논문 리뷰
포트폴리오를 정리하면서 기존에 진행했던 프로젝트를 리뷰했다. 그 중 음악 추천 모델 설계 프로젝트가 있었는데 지금 보니 내용이 매우 빈약했다. 추천 시스템 설계가 어떻게 이루어지는지 궁금증이 생겨서 논문을 리뷰한다. 해당 논문은 16년도에 구글에서 나온 논문이다.
10.Dataset.map

허깅페이스에 제공하는 여러가지 라이브러리 중 datasets은 허깅페이스에 있는 수 많은 데이터셋을 쉽게 사용할 수 있는 강력한 도구이다. 허깅페이스 라이브러리를 사용하면서 두 클래스의 차이점을 경시하고 사용했다. Dataset.map을 조사하면서 두 클래스의 차이를
11.RoBERTa 논문 리뷰
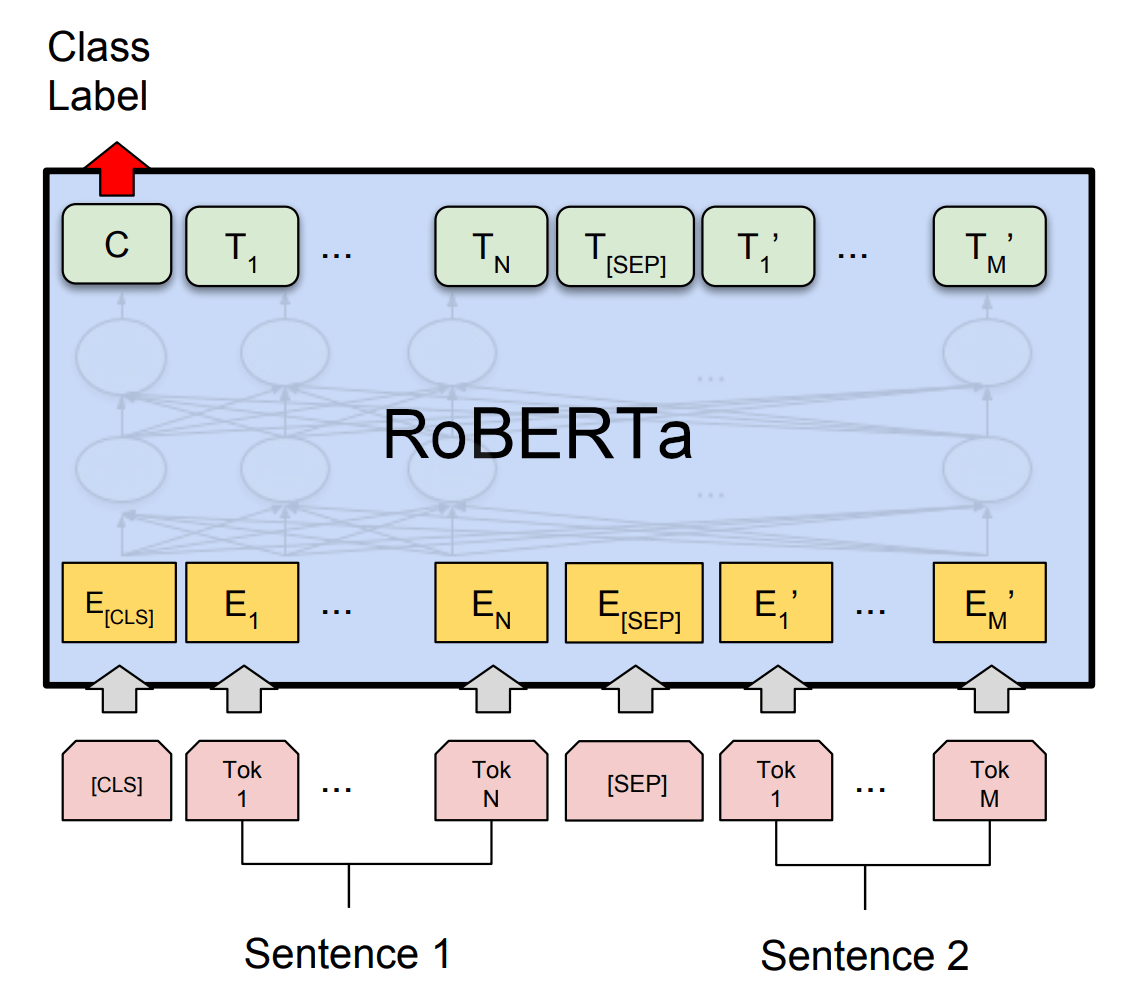
💡 Robustly optimized BERT approachRoBERTa 모델의 의의: BERT 모델의 훈련 과정과 설계에서 한계 보완훈련 데이터와 훈련 시간 부족: BERT 모델의 훈련 시간과 데이터 양이 부족함 → BERT 모델 성능이 최적화 덜 된 체 학습 종
12.Attention is All You Need 논문 리뷰
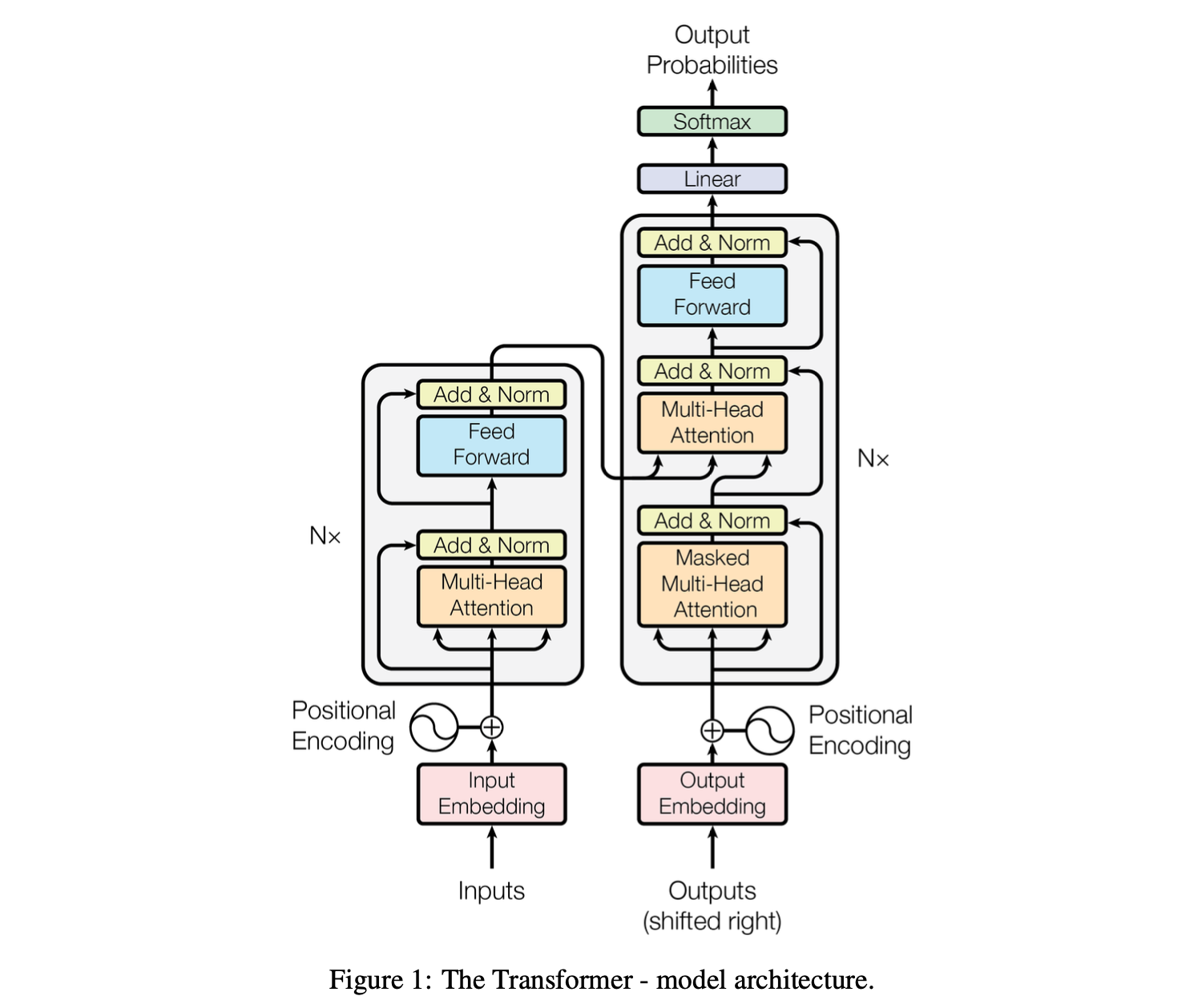
대부분 시퀀스 변환 모델은 RNN/CNN 기반 인코더-디코더 구조. 가장 성능 좋은 모델도 어텐션 메커니즘으로 인코더-디코더 구조→ 더 심플한 트랜스포머 구조 제안. Recurrent/Convolution 연산 배제2개 기계 번역 테스크에서 병렬화, 학습 시간 줄이는데
13.BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
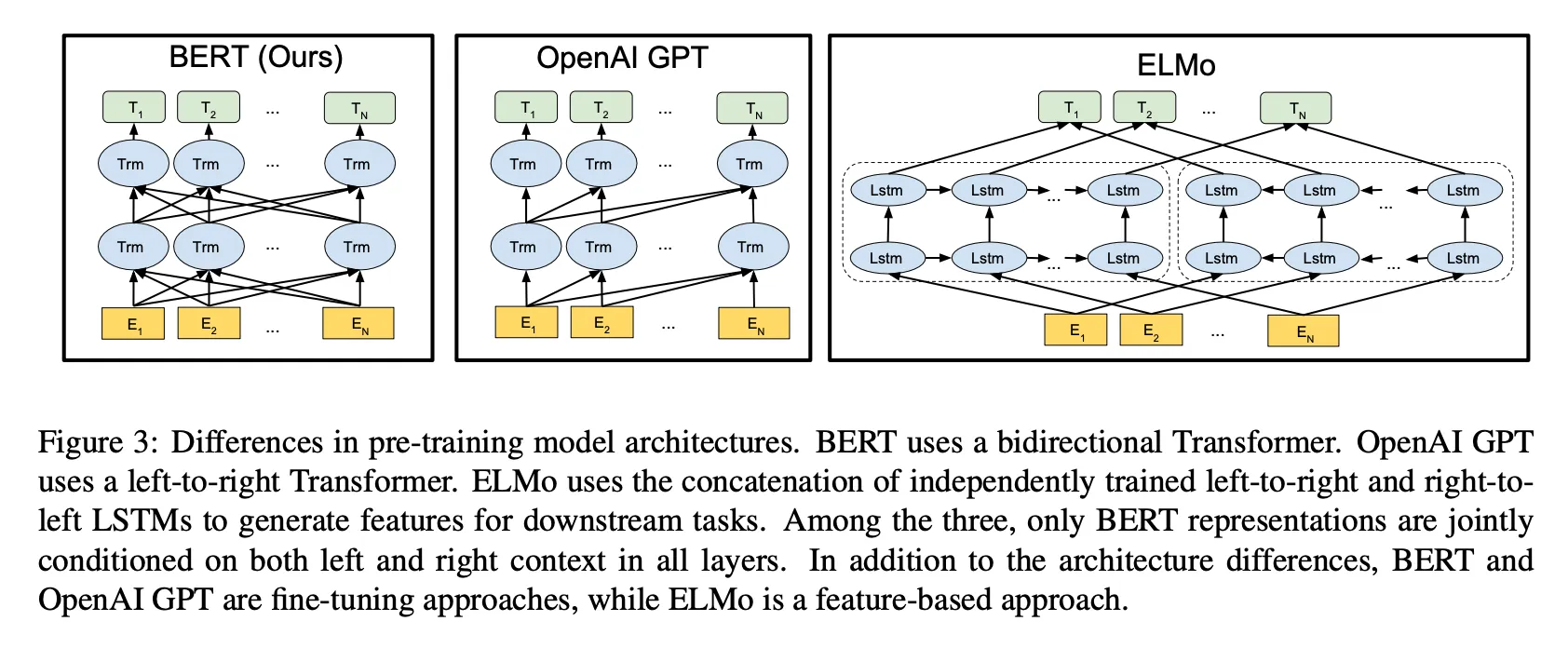
BERT: Bidirectional Encoder Representations from Transformers → 트랜스포머 기반 양방향 인코더 모델(혹은 Representation)ELMo, GPT: 단방향 모델 ↔ BERT: 양방향 문맥을 동시에 고려. 라벨 없는
14.MCP와 통신 프로토콜
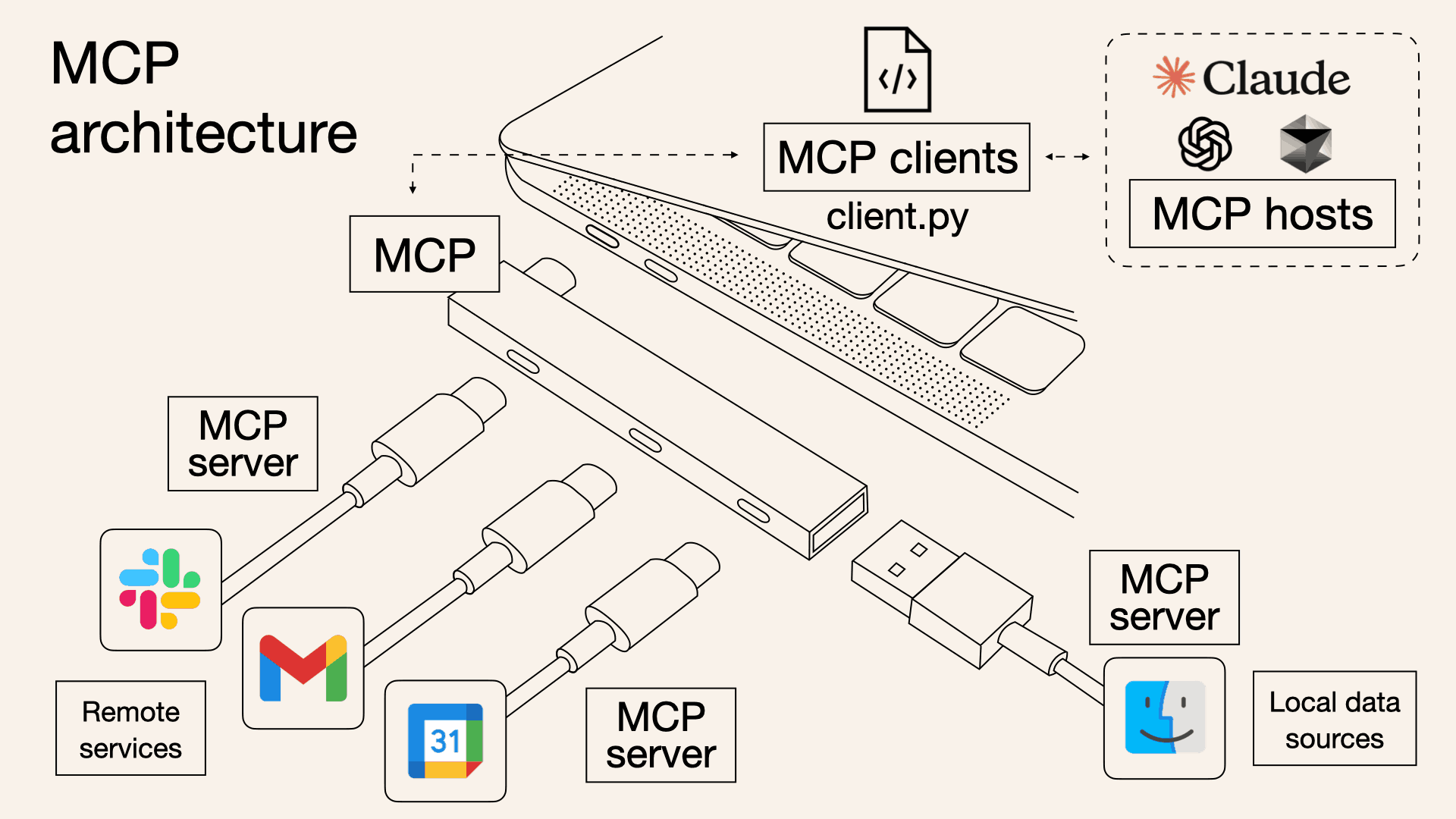
MCP는 Model Context Protocol의 약자로, LLM 혹은 LLM 어플리케이션이 외부 도구 혹은 데이터를 접근하기 용이하도록 구상된 통신 규약(Protocol) 이다.MCP는 크게 3가지로 구성되어 있다. 일반적인 네트워크 프로토콜과 비교하면서 보자.네트