Abstract
BERT: Bidirectional Encoder Representations from Transformers → 트랜스포머 기반 양방향 인코더 모델(혹은 Representation)
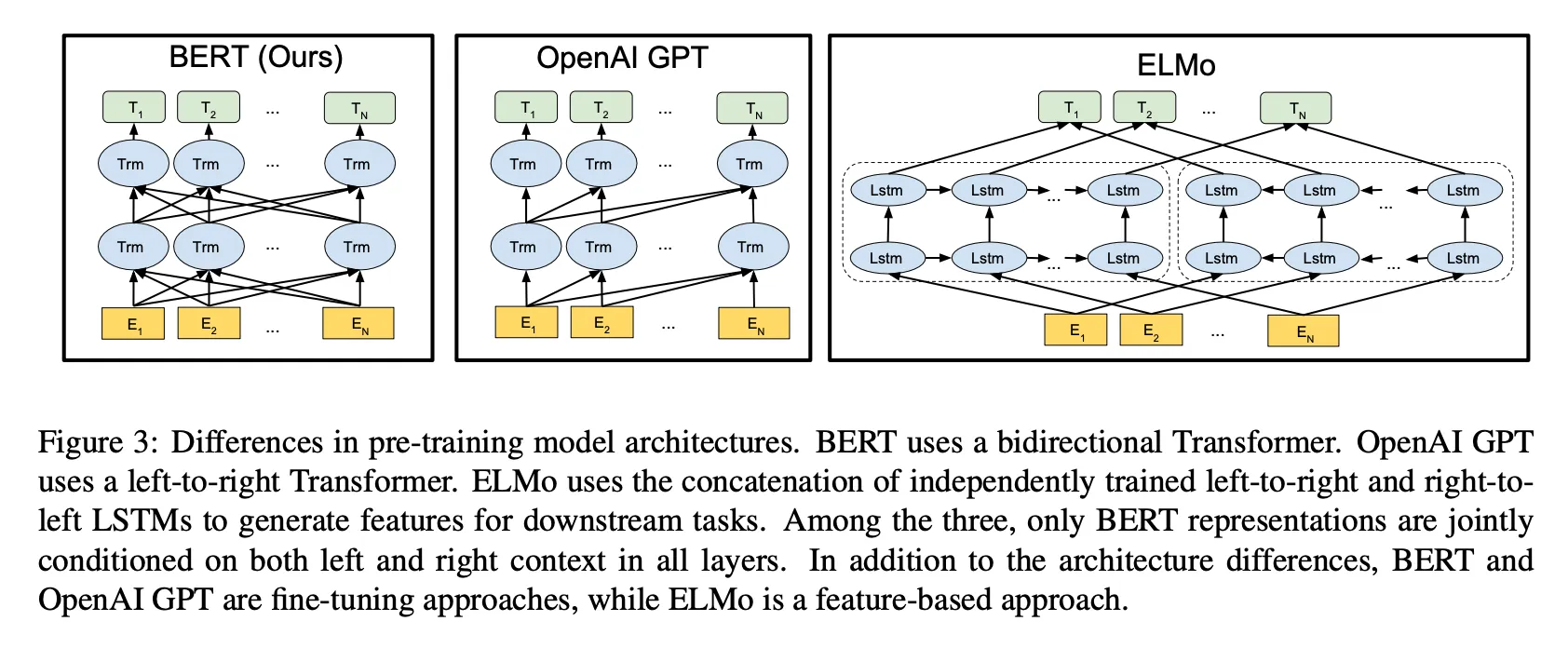
ELMo, GPT: 단방향 모델 ↔ BERT: 양방향 문맥을 동시에 고려. 라벨 없는 대규모 텍스트로 사전 학습. 모든 트랜스포머 레이어에서 양방향 학습함.
- ELMo, GPT
- ELMo: 좌-우 단방향을 따로 학습한 후 결합 (further reading)
- GPT: 왼쪽 → 오른쪽 문맥만 학습 (further reading)
BERT는 출력 레이어만 추가하면 파인 튜닝 가능 → 다양한 NLP 작업에서 SOTA. QA, Language Inference. 작업에 따라 모델 구조를 새로 설계할 필요가 없음
BERT → 직관적이고 성능이 우수함
11개 NLP 테스크에서 BERT가 SOTA임 ㅎㅎ → GLUE 80.5%로 기존 SOTA GLUE에서 7.7% 향상(절대적 수치). MultiNLI 86.7% (4.6% 향상), SQuAD v1.1 QA에서 F1 93.2 (1.5 향상), SQuAD v2.0에서 F1 83.1 (5.1 향상)
1. Introduction
언어 모델 사전 학습은 많은 NLP 테스크 향상시킴
- 인용 연구
- Dai and Le (2015): RNN을 활용한 텍스트 생성 및 문장 분류에 사전 학습 적용
- Peters et al. (2018a): EMLo 제안. 단어 임베딩이 문맥을 고려하도록 사전 학습
- Radford et al. (2018): GPT 제안. 단방향 트랜스포머로 사전 학습함
- Howard and Ruder (2018): ULMFit(Unsupervised Learning for Fine-tuning)으로 사전 학습의 일반화
→ 문장 단위 테스크 포함. ex) 자연어 추론, 패러프레이징(문장의 의미를 유지하며 다른 표현으로 변환하는 작업) → 문장 간 의미적 관계 예측함. 즉 문장 전체를 종합적으로 분석함. 또한 객체 명 인식, QA 등 출력이 단어 단위 세밀한 정보로 이뤄지는 토큰 단위 작업도 포함.
- 인용 연구
- 자연어 추론 Natural Language Inference(NLI)
- Bowman et al. (2015): SNLI(Stanford Natural Language Inference) 데이터셋 → NLI 기초
- Williams et al. (2018): MultiNLI(Multi-Genre NLI) 데이터셋 → 다양한 장르의 NLI
- 패러프레이징 Paraphrasing
- Dolan and Brockett (2005): Microsoft Research Paraphrase Corpus(MRPC) → 문장 간 유사성 판단
- 객체 명 인식 Named Entity Recognition(NER): 텍스트에서 고유 명사 식별
- Tjong Kim Sang and De Meulder (2003): CoNLL 2003 Shared Task → NER 표준 데이터셋과 평가 지표 제안
- Question Answering(QA): 주어진 질문에 대한 정확한 답변
- Rajpurkar et al. (2016): SQuAD(Stanford Question Answering Dataset) → QA 작업의 표준 데이터셋
- 자연어 추론 Natural Language Inference(NLI)
- 표현(representation)의 의미 https://en.wikipedia.org/wiki/Feature_learning 데이터에서, Feature == Representation 즉, 데이터에서는 모델이 이해할 수 있는 형태로 데이터를 변환하는 행위를 Representation이라고 한다. https://paperswithcode.com/task/representation-learning Representation Learning이란, 비정제 데이터에서 패턴을 추출해서 모델이 쉽고 작업하기 간편한 표현(바로 위에서 말하는)을 만들어내는 작업. 위 두 내용을 종합하자면, 모델이 이해할 수 있게 형태를 바꾸는 행위가 Representation이다. 그렇다면 Representation Model은 모델이 이해할 수 없는 데이터(예를 들면 literal한 문장. “The cat is on the mat.”)을 입력으로 받는 모델이라고 이해할 수 있겠다.
연구진은 GPT와 ELMo가 사전 학습의 이점을 충분히 사용하지 못한다고 주장함. 특히 파인 튜닝 접근 방법에서.
기존 언어 모델의 주요 한계: 단방향 → 사전 학습 단계에서 사용할 수 있는 모델 구조가 제한됨
OpenAI GPT를 예시로 듦
GPT는 입력 시퀀스를 왼쪽에서 오른쪽으로 처리 → 모든 토큰들이 이전 토큰만 참고할 수 있음
이러한 제한은 문장 단위 작업에서 적절하지 않음
QA와 같은 토큰 레벨 작업에 파인 튜닝을 적용하는 경우 부정적인 영향 → 좌우 문맥을 모두 활용해야 하니깐
파인 튜닝 기반 방식을 개선함. 뭘로? BERT로.
BERT는 Cloze task에서 영감 받은 “masked language model”(MLM)으로 단방향 제약을 완화함.
- 인용 연구
- Cloze task (Taylor, 1953): 주어진 문장에서 빈칸(누락된 단어)를 채우는 작업 → 문맥 이해 능력을 평가하기 위한 클래식한 접근 방식
- MLM
- MLM: 입력 문장에서 일부 토큰 마스킹 → 마스킹 예측하는 사전 학습 방식 (이후 설명)
MLM은 입력 문장에서 일부 토큰을 마스킹함. 마스킹의 목적은 마스킹된 단어의 원래 단어 ID를 문맥 만으로 예측. (객체인지 목적인지 살짝 헷갈림 → 다른 사람 참고할 것)
MLM의 목적은 양방향 문맥을 녹이는 것.(enables the representation to fuse) → BERT가 깊은 양방향 트랜스포머를 사전 학습하게 한다.
Next Sentence Prediction(NSP) 작업을 사용함 → NSP와 MLM을 함께 학습해 텍스트-쌍 표현을 같이 사전 학습함.
성과 1) 언어 표현에서 양방향 사전 학습 중요성 입증.
사전 학습에서 단방향 언어 모델을 사용하는 GPT와 달리, BERT는 마스킹된 언어 모델을 사용해서 깊은 양방향 표현을 학습함.
EMLo와도 대비됨 → ELMo는 좌→우와 우→좌 모델이 각각 독립적으로 학습되어, 이를 단순히 결합함
성과 2) 사전 학습된 언어 표현은 작업 별로 복잡하게 모델 구조를 설계할 부담을 줄여줬다는 것을 증명함
BERT는 첫 파인 튜닝 기반 representation model임. 테스크에 특화된 많은 모델보다 문장 레벨에서도, 토큰 레벨에서도 SOTA 찍음. 총 11개 ㅎㅎ
2. Related Work
2.1 Unsupervised Feature-based Approaches
수십년 동안, 보편적으로 적용할 수 있는 단어 표현이 연구됨
- 인용 연구
- Non-neural
- Brown et al. (1992): Brown 클러스터링 → 단어를 유사한 문맥에서 나타나는 그룹으로 클러스터링하는 방법
- Ando and Zhang (2005): 다중 작업 학습 → 공유 표현을 학습하는 접근법
- Blitzer et al. (2006): 도메인 별로 구조화 및 정렬된 단어 공간 활용
- Neural
- Mikolov et al. (2013): Word2Vec → 단어를 벡터로 표현하여 문맥 기반 의미를 학습
- Pennington et al. (2014): GloVe → co-occurrence 확률 기반 임베딩 생성 water는 각각 steam, ice가 포함된 문맥에서 등장할 확률이 비슷함. water로부터 비슷한 등장 확률을 가지는 steam과 ice를 도출하는 작업이 GloVe
- Non-neural
사전 학습된 단어 임베딩 모델은 현대 NLP 시스템의 필수 요소임 → 초기화된 상태에서 학습된 임베딩보다 더 나은 성능
- 인용 연구 Turian et al. (2010): 사전 학습된 임베딩(예: Word2Vec, GloVe)이 초기화된 임베딩보다 성능이 우수함을 실험적으로 입증
좌→우 방향 언어 모델링 객체가 사용됨 → 단어 임베딩 벡터 사전 학습 위함, 단어 주변 문맥에서 올바른 단어를 식별
- 인용 연구 Mikolov et al. (2013): Word2Vec의 Skip-Gram 모델 → 단어 주변 문맥 단어 예측
이런 임베딩 학습 방법론은 문장/문단 단위 임베딩 표현으로 확장됨
- 인용 연구
- Kiros et al. (2015): Skip-Thought 모델은 문장을 임베딩하고, 주변 문장을 예측
- Logeswaran and Lee (2018): Quick-Thought 모델은 문맥 관계를 학습하기 위해 문장을 임베딩
- Le and Mikolov (2014): Paragraph Vector 모델은 문단의 의미를 유지하는 고정 벡터 표현
문장 표현을 학습하기 위해 이전 연구들은 문장 예측 랭킹을 목표로 했음 → 이전 표현을 기반으로 다음 문장의 단어를 생성 or 입력 데이터를 일부 손상시킨 후 이를 복원
- 인용 연구
- Jernite et al. (2017): 랭킹 → 텍스트 요약과 문맥 관계 학습
- Logeswaran and Lee (2018): Quick-Thoughts → 후보 문장 랭킹하여 문장 관계 학습
- Kiros et al. (2015): Skip-Thought → 이전 문장 기반 다음 문장 생성 → 의미적 유사성 학습
- Hill et al. (2016): denoising autoencoder로 문장 임베딩 학습
ELMo와 기반 연구는 기존 단어 임베딩 연구를 보완
좌→우, 우→좌 언어 모델에서 문맥 정보를 추출함
ELMo 임베딩을 기존의 텍스트 특화 구조 모델에 통합하니 여러 벤치마크 SOTA 찍음 → QA, 감정분석, NER
- 인용 연구
- Question answering (Rajpurkar et al., 2016): SQuAD 데이터셋에서 QA 작업 성능 개선
- Sentiment analysis (Socher et al., 2013): Stanford Sentiment Treebank에서 성능 향상
- Named entity recognition (Tjong Kim Sang and De Meulder, 2003): CoNLL 2003 데이터셋에서 NER 작업 정확도 개선
Melamud et al. (2016) 연구에서 문맥에 따라 변하는 단어 표현 학습을 제안 → LSTM을 사용해서 주어진 문맥에서 특정 단어를 예측할 때, 양방향 문맥 모두 활용. 하지만 근본적으로 양방향 모델은 아니다
Cloze task를 활용한 텍스트 생성 모델 개선 연구인 Fedus et al. (2018)에서 cloze task가 텍스트 생성 모델에서 robustness를 개선함
2.2 Unsupervised Fine-tuning Approaches
feature 기반 접근 방식처럼 비지도 파인 튜닝 접근 방식도 레이블 없는 텍스트에서 임베딩된 파라미터를 사전 학습하는 연구로 시작
- 인용 연구 Collobert and Weston, 2008: CNN 모델을 NLP에 적용
최근으로 오면 문맥적 토큰 표현을 나타내는 문장/문서 임베딩 레이블 없는 텍스트를 사전 학습함, 지도 학습이 필요한 작업을 위해 파인 튜닝됨
- 인용 연구
- Dai and Le (2015): RNN으로 문서 수준의 표현 연구
- Howard and Ruder (2018): ULMFit(Unsupervised Language Model Fine-tuning)을 제안해 사전 학습된 언어 모델 효과 입증
- Radford et al. (2018): OpenAI GPT를 제안 → 단방향 트랜스포머로 사전 학습 + 파인 튜닝 결합
새로 학습할 파라미터가 적다는 장점
이런 사전 학습의 장점으로 OpenAI GPT가 GLUE 벤치마크로 구성된 많은 문장 레벨 테스크에서 SOTA 달성
- 인용 연구
- Radford et al. (2018): GPT
- Wang et al. (2018a): GLUE
좌→우 언어 모델링과 auto-encoder는 그러한 모델을 사전 학습하기 위해 사용됨
- 인용 연구
- Howard and Ruder (2018): ULMFit → 사전 학습 후 미세 조정하여 NLP 테스크 여러 곳에 사용
- Radford et al. (2018): GPT
- Dai and Le (2015): 문서 수준의 표현을 학습하기 위해 auto-encoder 사용함
2.3 Transfer Learning from Supervised Data
대규모 데이터셋으로 학습된 supervised 작업에서도 전이 학습이 효율적이였음 → NLI, 기계 번역
- 인용 연구
- NLI (Conneau et al., 2017): SentEval 프레임워크 → NLI 작업이 전이 학습의 기초롤 사용될 수 있음
- 기계 번역 (McCann et al., 2017): 기계 번역 모델 중간 레이어에서 생성된 표현인 CoVe를 다른 NLP 작업으로 전이 가능함을 보임
비전 연구도 큰 사전 학습 모델에서 전이 학습하는게 중요하다는 것을 입증함 → ImageNet으로 사전 학습된 모델을 파인 튜닝
- 인용 연구
- Deng et al. (2019): ImageNet 데이터셋
- Yosinski et al. (2014): 사전 학습 모델이 새로운 작업에 어떻게 적응할 수 있는지 분석. 특정 레이어가 일반적인 특징을 학습함을 밝힘
3. BERT
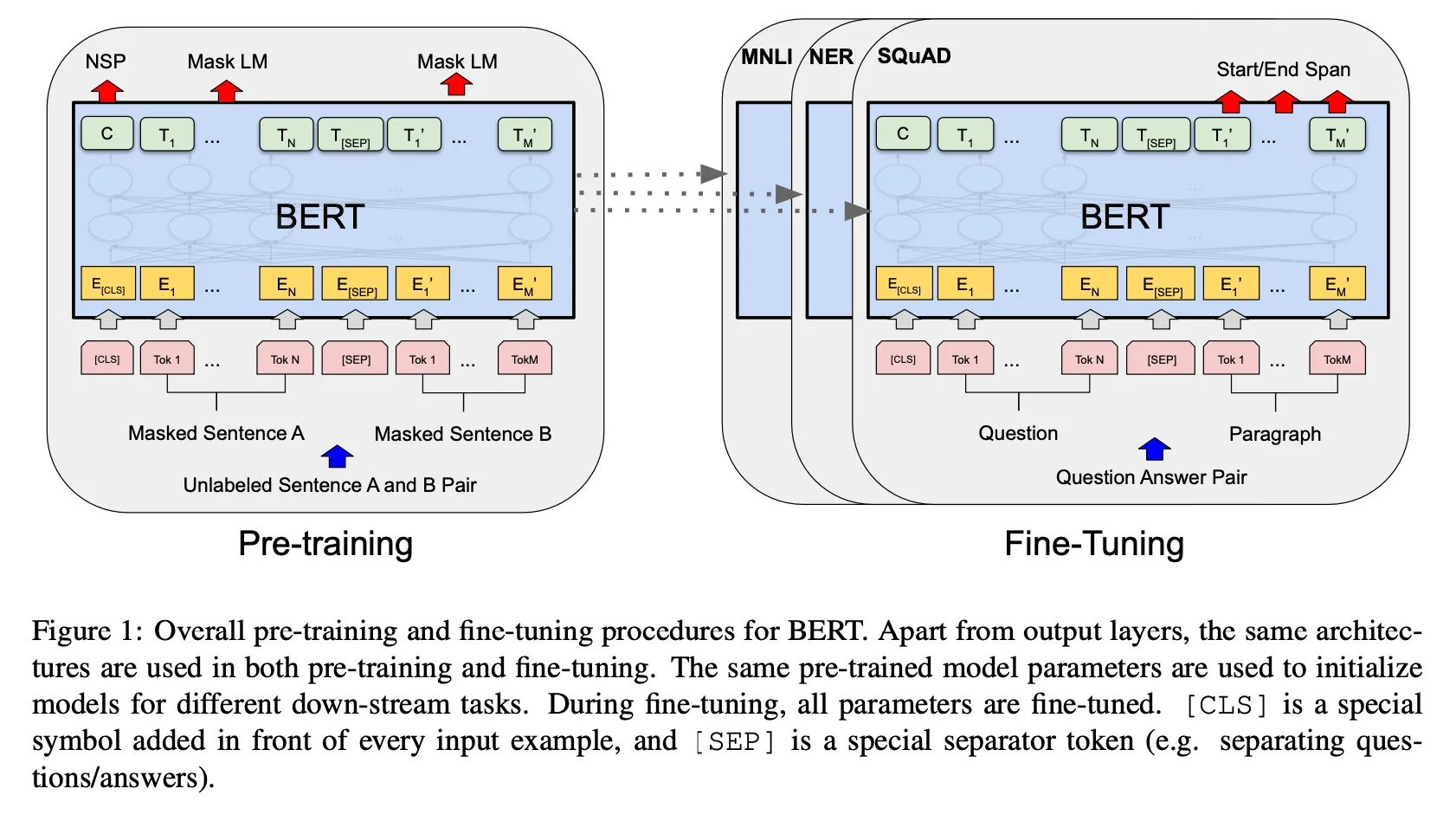
pre-training + fine-tuning 구성
pre-training: 모델이 레이블 없는 데이터 학습 → MLM, NSP 등 수행
fine-tuning: pre-training에서 학습한 가중치를 초기값으로 사용, 특정 작업에 파라미터가 파인 튜닝됨
같은 값으로 초기화된 파라미터로 시작하지만 각 세부 작업에 따라 분리됨
Figure 1: QA를 예시로 둠
BERT는 다른 작업이지만 통합된 구조
파인 튜닝 구조와 세부 작업 구조에서 차이가 거의 없음
Model Architecture
BERT 구조는 다층, 양방향 트랜스포머 구조 → 근본인 tensor2tensor 기반
논문에서: 트랜스포머 구조 니네 알지? 설명 생략하고 BERT가 왜 짱짱맨인지 중점적으로 알려줄게
층의 개수(number of layers): , 은닉 상태(hidden state): , 셀프 어텐션 헤드 개수:
BERTBASE (L=12, H=768, A=12, Total Parameters=110M) → GPT랑 비교하기 위해 똑같은 모델 크기 선택함. GPT는 단방향인데 BERT는 양방향임
BERTLARGE (L=24, H=1024, A=16, Total Parameters=340M)
양방향 트랜스포머: Transformer Encoder, 단방향 트랜스포머: Transformer Decoder
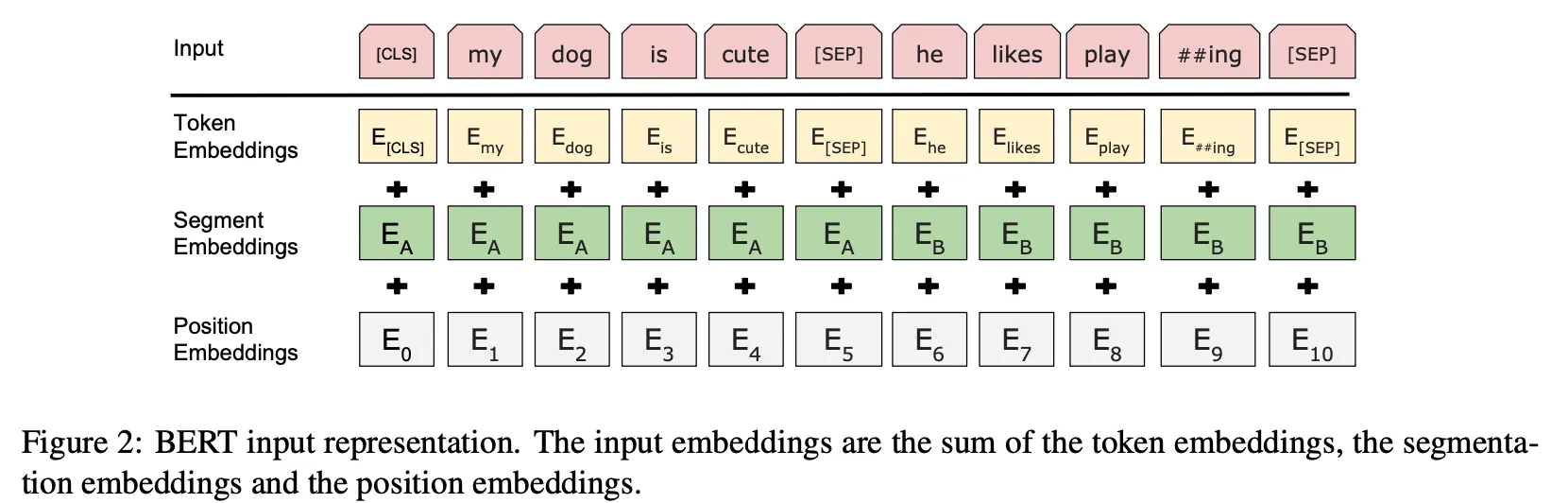
Input/Output Representations
다양한 NLP 작업을 처리하기 위해 입력 표현에서 문장 간의 모호성을 제거함. 단일 문장 혹은 문장 쌍에 대해.
문장은 언어학적 정의가 아닌 연속된 텍스트 조각임
시퀀스는 BERT가 처리하는 입력 토큰의 순서를 의미 → 한 문장일 수도 있고 혹은 두 문장이 하나로 묶여있을 수도 있음
30000개 토큰 어휘로 WordPiece 임베딩함
모든 시퀀스의 첫 토큰은 [CLS]임
마지막 [CLS] 토큰에 해당하는 hidden state → 분류 작업을 위해 전체 입력 시퀀스를 요약함
문장 쌍은 하나의 시퀀스로 묶임
[SEP]으로 문장 쌍 안에서 문장을 구분함
각 토큰이 문장 A, B 어디에 속하는지 표시하는 학습 임베딩 추가 (Segment Embedding이라고도 함)
입력 표현 = 토큰 임베딩 + 세그먼트 임베딩 + 포지션 임베딩
Figure 1에서
3.1 Pre-training BERT
Task #1: Masked LM
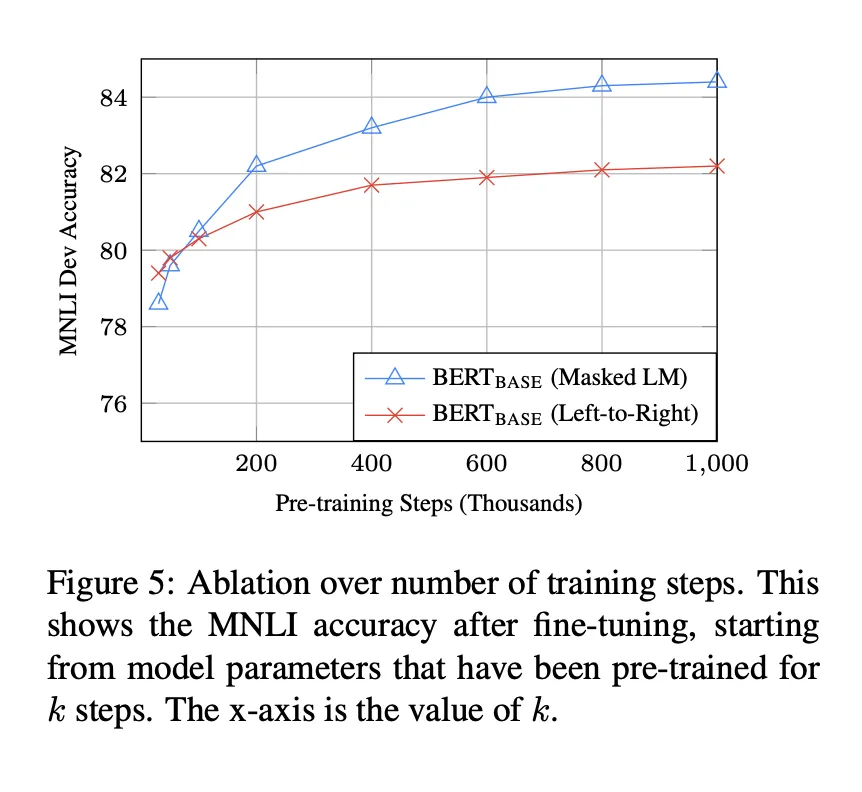
직관적으로 좌→우 단일 모델 혹은 얕은 좌→우, 우→좌 결합 모델보다 깊은 양방향 결합이 좋음
전통적인 조건부 모델(GPT, RNN 기반 모델)은 방향성에 제한이 있음 →
양방향 모델은 목표 단어를 학습할 때, 해당 단어를 문맥 내에서 간접적으로 참조하게 됨 → 쉽게 추측 가능
모델이 너무 쉽게 목표 단어를 예측해 다층으로 구성된 문맥에서 학습이 무의미해짐
깊은 양방향 표현을 학습하기 위해서 입력 토큰을 랜덤하게 마스킹하고 마스킹 된 토큰을 예측하도록 함 → MLM, Cloze task 참고함
MLM 마지막 은닉 벡터 → 소프트맥스 층으로 전달
각 시퀀스의 15% 랜덤 마스킹
전체 입력을 재구성하는 denoising auto-encoder와 대비해서, BERT는 마스킹된 단어만 예측함
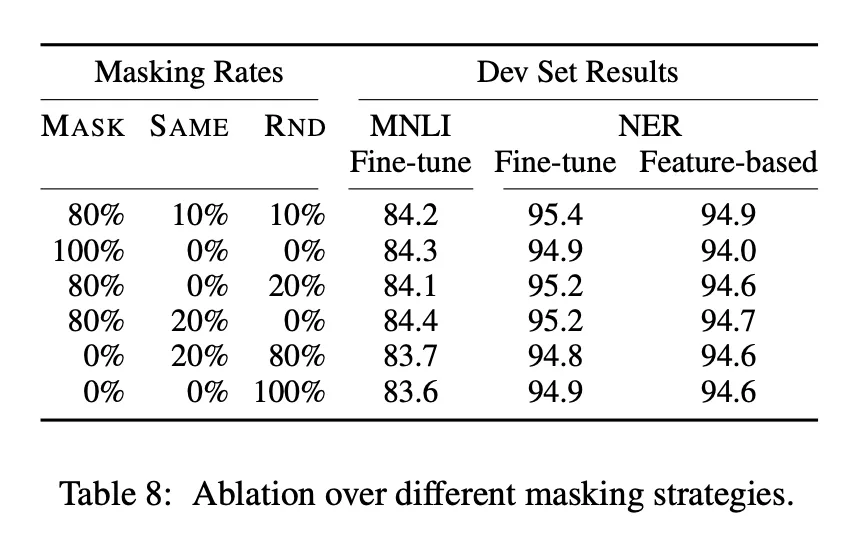
이런 마스킹은 양방향 사전 학습 모델을 얻을 수 있지만, 파인 튜닝에서는 [MASK] 토큰이 없으므로 맞지 않음 → 항상 마스킹된 단어를 [MASK] 토큰으로 대체하지는 않음
마스킹 확률 15% → 마스킹 대상으로 선택된 경우
- 80%는 [MASK]로 대체
- 10%는 무작위 토큰으로 대체
- 10%는 그대로 둠

토큰은 크로스 엔트로피 함수로 원래 토큰을 예측함
Task #2: Next Sentence Prediction
QA나 NLI 같은 작업은 언어 모델이 직접 다루지 못하는 두 문장 사이 관계를 이해하는 걸 기반으로 한다.
단일 언어 코퍼스에서 간단하게 생성할 수 있는 이진화된 NSP를 학습 → 문장 간 관계를 학습
절반은 실제 다음에 오는 문장, 나머지 절반은 무작위로 선택된 문장
[CLS] 토큰의 최종 은닉 벡터 C는 NSP에 사용됨 → NSP 이외에는 파인 튜닝 필요
QA와 NLI에 효과적 → NSP 정확도 97~98% 달성
NSP는 표현 학습과 유사함
- 인용 연구
- Jernite et al. (2017): 문장 관계를 학습하기 위해 후보 문장의 순위를 매기는 방식을 사용한 연구
- Logeswaran and Lee (2018): 다음 문장을 예측하는 방식으로 문장 간 관계를 학습하는 모델 제안. 문장 임베딩 생성
이전 연구는 문장 임베딩만 다운스트림 작업에 활용함. BERT는 사전 학습된 전체 모델을 다운스트림 작업에 활용함
Pre-training Data
BERT 사전 학습 괒어은 이전 사전 학습 연구를 거시적으로 따름
사전 학습 코퍼스는 BooksCorpus (800M 단어, 소설과 같은 문학 텍스트가 포함되어 풍부한 문맥 학습이 가능함), English Wikipedia (2500M 단어)
위키피디아에서는 리스트, 테이블, 헤더를 제외한 텍스트 문단만 사용함
Billion Word Benchmark와 같이 문장이 무작위로 배열되어 있는 데이터셋이 아닌, 긴 연속적인 텍스트 시퀀스를 추출하기 위해 document-level corpus를 사용하는 것이 필수
3.2 Fine-tuning BERT
다운스트림 작업에 따라 입출력 구성을 변경 → 파인 튜닝이 단순해짐. 트랜스포머 내 셀프 어텐션이 BERT를 다양한 다운스트림을 모델링하기 때문
두 개의 텍스트를 처리하는 작업: 이전까지 양방향 크로스 어텐션에 적용하기 전에 따로 텍스트 쌍을 인코딩하는 패턴이 흔했음
BERT는 독립 인코딩 + 크로스 어텐션을 합쳐서 셀프 어텐션을 사용함 → 셀프 어텐션을 활용하여 텍스트 쌍을 결합 → 두 문장 간 양방향 크로스 어텐션을 효과적으로 포함함
간단하게 테스크에 맞는 BERT에 입출력을 끼워넣고, 모든 파라미터를 파인 튜닝함
입력에서 두 문장은 4가지 사항에서 유사함
- 패러프레이징에서 문장 쌍
- 가설-검증 쌍
- 질의 응답 쌍
- 텍스트 분류, 시퀀스 태깅에서 단일 문장: text-
출력에서 시퀀스 태깅, NER과 같은 토큰 단위 작업을 위해 토큰 표현이 출력 계층으로 들어감. [CLS] 표현은 entailment(함의라는 뜻. 두 문장 간 논리적 관계를 예측), 감정 분류와 같은 분류 작업을 위해 출력 계층으로 들어감
파인 튜닝 비용 상대적으로 비쌈
동일한 조건에서 클라우드 TPU를 사용해서 1시간, 혹은 GPU 몇 시간으로 실험 재현 가능 → BERT SQuAD 모델의 경우 1개 클라우드 TPU로 30분 학습해서 F1 스코어 91.0% 달성
- Appendix A.5
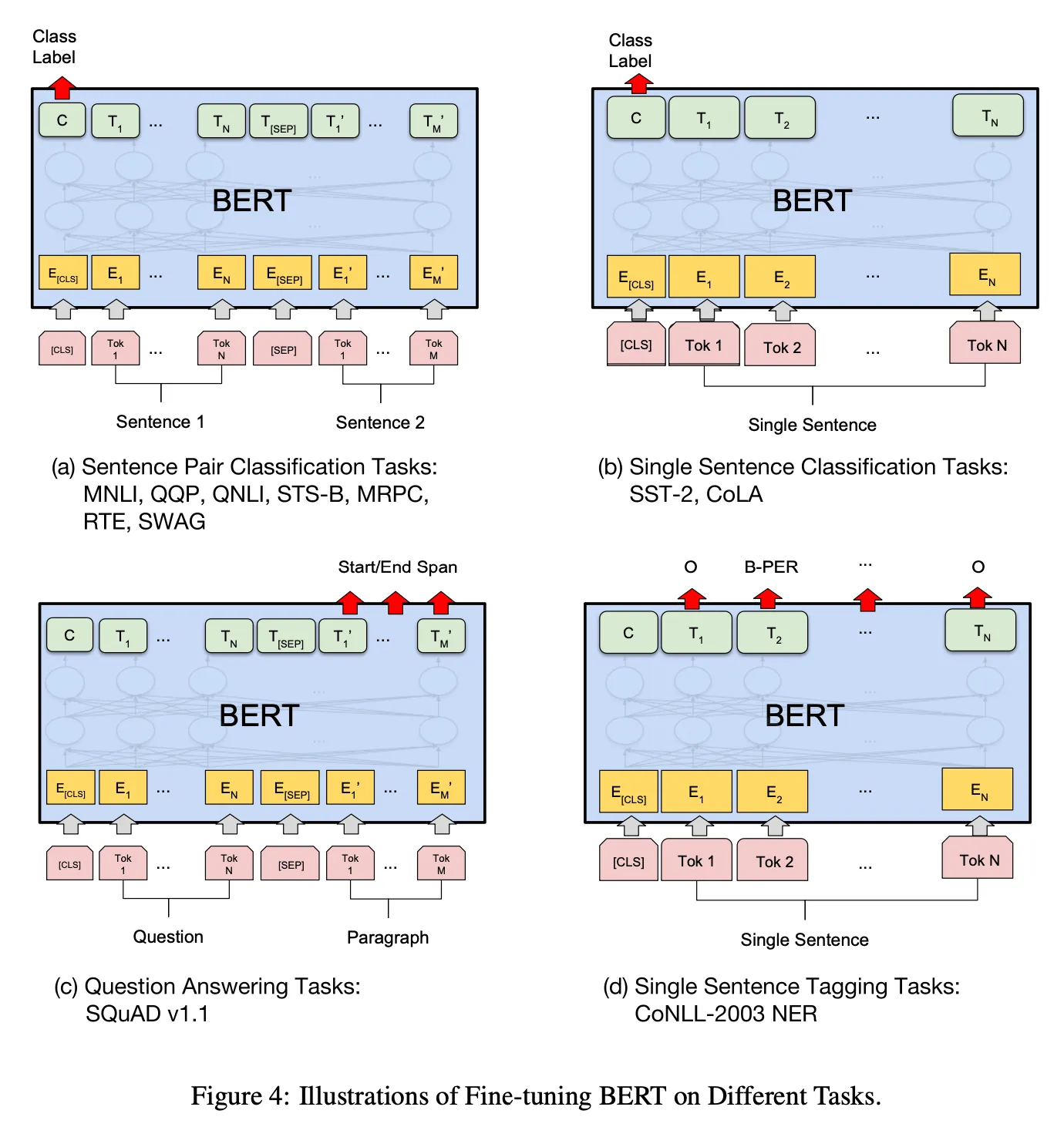 a, b: 문장 단위. a: 두 문장 관계 예측, b: 단일 문장 레이블 예측 c, d: c: 토큰 단위. c: 입력으로 질문+문서 → 시작~끝 토큰 예측, d: 단일 문장 입력 → 토큰에 레이블 할당
a, b: 문장 단위. a: 두 문장 관계 예측, b: 단일 문장 레이블 예측 c, d: c: 토큰 단위. c: 입력으로 질문+문서 → 시작~끝 토큰 예측, d: 단일 문장 입력 → 토큰에 레이블 할당
4. Experiments
4.1 GLUE
GLUE 벤치마크는 다양한 자연어 이해 테스크 모음임
- Appendix B.1
- MNLI: 다양한 장르 문서에서 수집된 문장 쌍 → 두 문장 사이의 관계: Entailment 포함/Contradiction 모순/Neutral 중립
- QQP: Quora 플랫폼에서 수집된 질문 쌍 데이터 → 두 질문이 의미적으로 동등한지 여부. 이진 분류
- QNLI: SQuAD의 변형 버전. 질문-문장 간의 관계. 이진 분류
- SST-2: 영화 리뷰에서 추출된 문장. 해당 리뷰 문장이 긍정/부정 여부인지 판별. 이진 분류
- CoLA: 단일 문장 분류 작업. 문법적으로 올바른지 예측. 이진 분류
- STS-B: 뉴스 헤드라인 및 기타 출처에서 추출된 두 문장이 의미적으로 얼마나 유사한지 1~5 사이 연속된 점수로 나타냄. 회귀
- MRPC: 온라인 뉴스 소스에서 자동으로 추출된 문장 쌍에서 의미적으로 동등한지 여부. 이진 분류
- RTE: MNLI와 유사하지만 학습 데이터가 훨씬 적음. 문장 쌍 간 논리적 관계를 예측. 이진 분류
- WNLI: 소규모 자연어추론 데이터셋 → 데이터셋 구성에 문제점이 존재함. 따라서 제외함.
GLUE 다운스트림 작업에 맞게 파인 튜닝하기 위해서 BERT의 입력 구조를 [CLS], [SEP] 토큰을 사용한 형태로 맞춤. [CLS] 토큰에 해당되는 은 시퀀스의 축약 표현.
파인 튜닝에서 새로 학습되는 파라미터는 분류 레이어의 가중치임
일반적인 분류 로스 사용:
배치 사이즈 32, 전체 데이터셋(모든 GLUE 테스크)에 대해 3 에폭
검증 데이터셋에서 학습률을 5e-5, 4e-5, 3e-5, 2e-5 중에서 선택함
BERTLARGE에서 작은 데이터셋으로 파인 튜닝하면 불안정하다는 사실을 발견 → 사전 학습 체크포인트 랜덤하게 시작: 파인 튜닝 데이터를 섞고, 분류 레이어 초기화를 다르게 둠
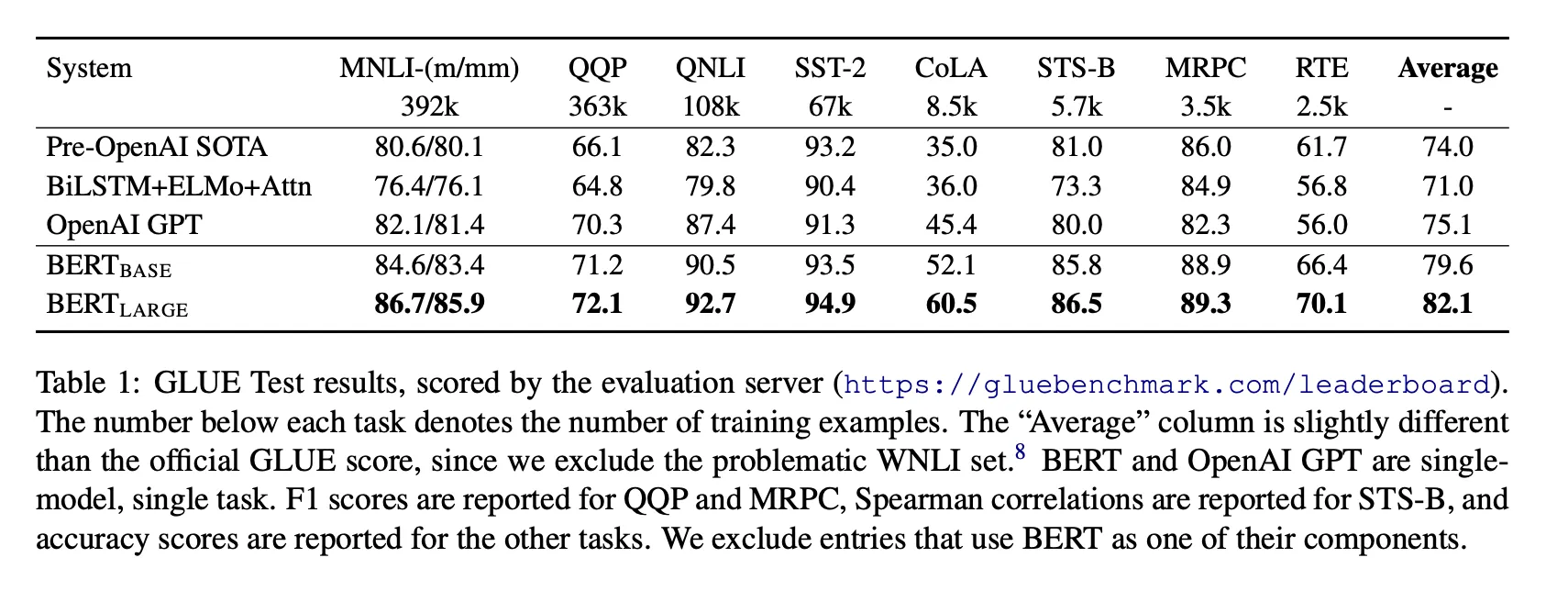
BERTBASE: 평균 정확도 4.5% 향상, BERTLARGE: 7.0% 향상
BERT, GPT 둘 다 트랜스포머 사용하지만 BERT는 양방향, GPT는 왼쪽 문맥만 참고함
BERT는 가장 널리 알려저 있는 GLUE인 MNLI에서 4.6% 향상
공식 GLUE 리더보드에서는 BERT가 80.5를 달성해 72.8을 달성한 GPT를 제침ㅋㅋ
BERTLARGE가 아주 작은 데이터로 학습되어도 BERTBASE 이김
4.2 SQuAD v1.1
일반 대중의 참여로 구성된 100k개의 질문-응답 쌍
답변이 포함된 위키피디아 문서 + 질문에서 답변 위치를 찾아냄
질문은 Segment A에 임베딩. 문서는 B에 임베딩.
파인 튜닝에서 시작 벡터 끝 벡터 만 도입함
단어 가 답변의 시작일 확률 는 와 의 내적을 소프트맥스 취함
답변의 끝도 비슷한 공식
후보 답변 범위의 점수는 로 정의됨. 그 중 인 최대 점수
학습 목표는 시작 ~ 끝 위치의 로그 확률의 합
에폭 3, 학습률 5e-5, 배치 크기 32
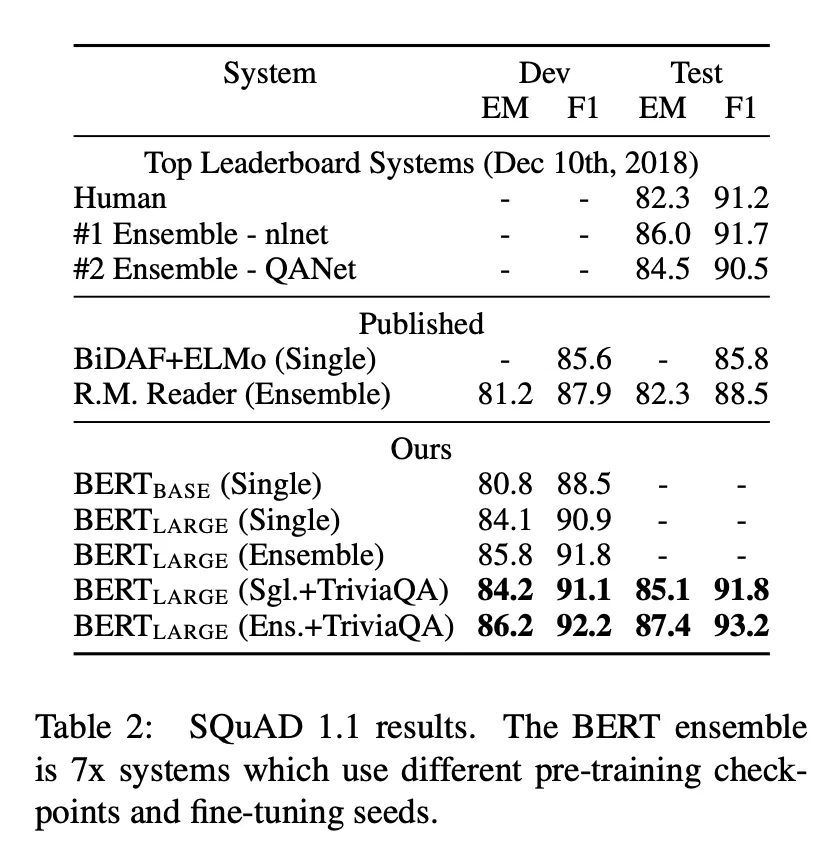
공개적으로 발표된 최신 연구 모델이 리더보드 상위 → 세부 구현이나 설명이 공개되지 않음. 공개된 데이터를 자유롭게 사용할 수 있음
그래서 SQuAD 데이터셋으로 파인 튜닝하기 전에 TriviaQA 데이터셋으로 적절하게 증강함
우리 최고 점수는 앙상블로 1.5 F1이고, 단일로는 1.3 F1임
TriviaQA 데이터셋 증강 없이 0.1~0.4로 미세한 점수. 그러나 우리가 짱
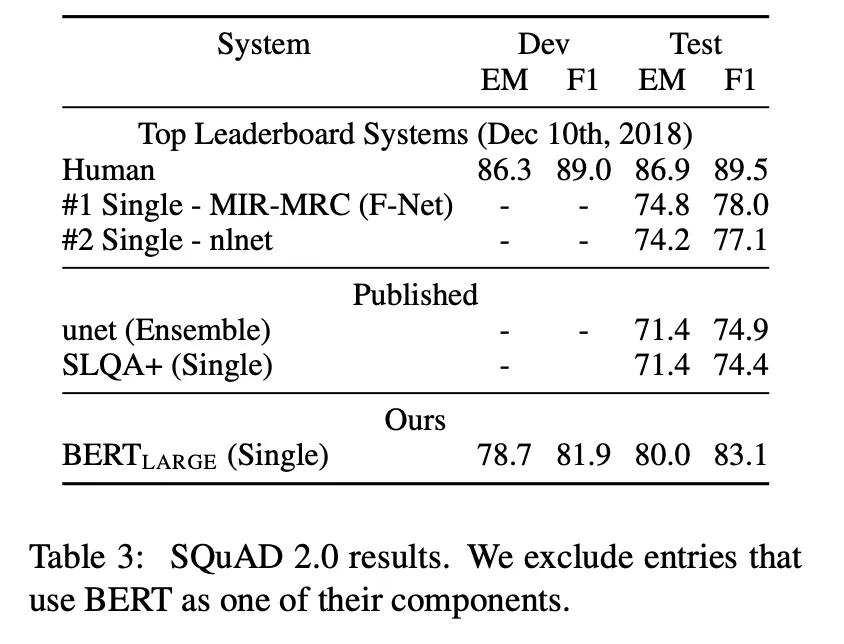
4.3 SQuAD v2.0
SQuAD 2.0은 1.1의 문제 정의 확장: 문서에 정답이 존재하지 않을 수 있음 → 현실성 높임
정답이 존재하지 않는 질문은 [CLS] 토큰을 시작과 끝 위치로 처리
확률 분포에 [CLS] 토큰 포함
정답 없음 점수
정답이 있는 경우:
정답이 있는 경우 로 설정함. 는 Null/Non-null 판단 기준. 검증 데이터셋에서 F1 점수가 최대화되는 값으로 설정.
TriviaQA 데이터셋 활용 X. 2 에폭, 5e-5 학습률, 48 배치 사이즈로 학습함.
F1 스코어 5.1 향상
4.3 SWAG
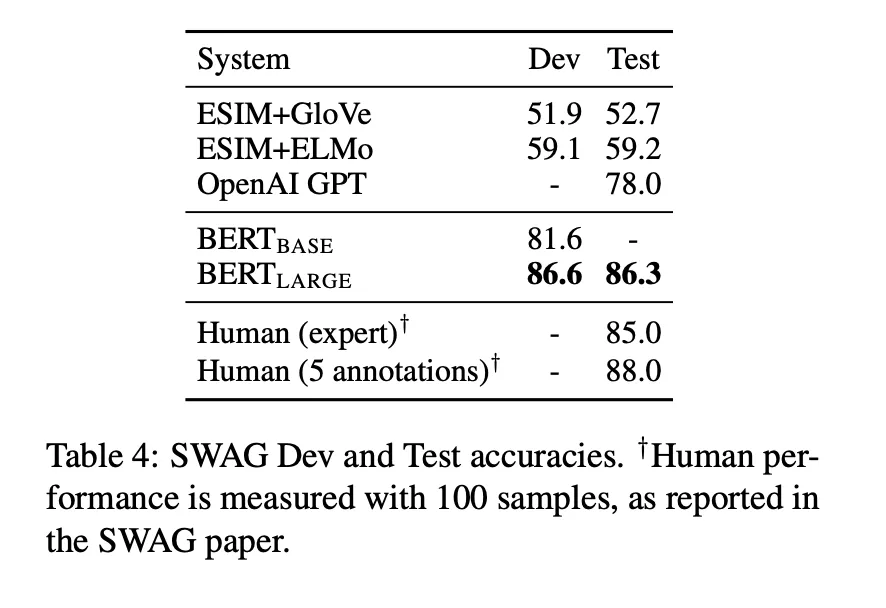
SWAG: Situations With Adversarial Generations → 113k 문장 쌍 포함. 상황 기반 상식 추론
입력으로 주어진 문장에 가장 그럴듯한 문장을 4개의 선택지 중에서 선택
네 개의 선택지를 모두 입력으로 사용함. 입력 문장 + 선택지 4개 문장
입력 [SEP] 선택지 1 [SEP] 선택지 2 …
테스크에 특화하기 위해 C 벡터를 내적으로 곱하고 소프트맥스로 normalize한 파라미터만 도입
3 에폭, 2e-5 학습률, 16 배치 사이즈
5. Ablation Studies
5.1 Effect of Pre-training Tasks
하이퍼파라미터, 사전 학습, 파인 튜닝 전부 고정
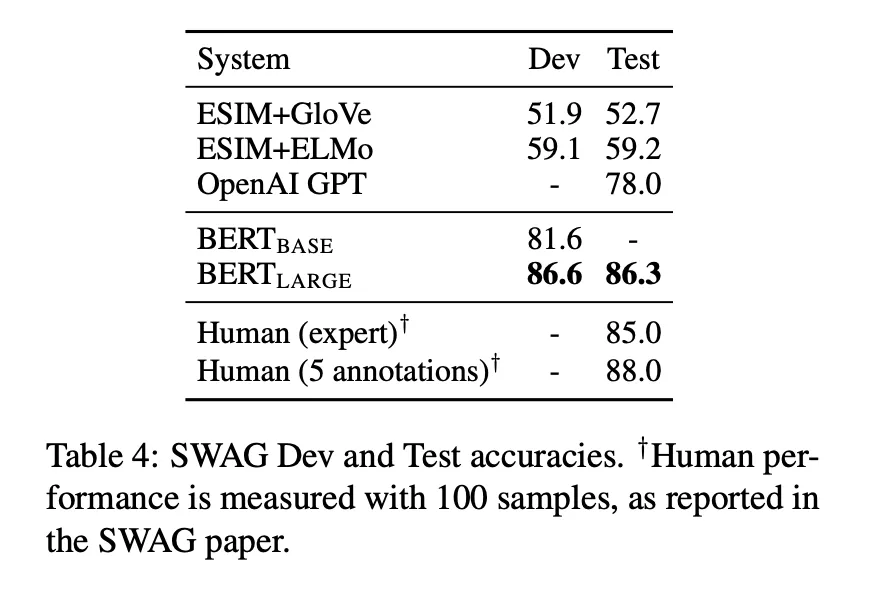
No NSP
MLM만 사용하여 학습된 양방향 모델
LTR & No NSP
왼쪽만 학습하는 모델 + NSP 제외함. 다운스트림 작업에서도 일관성을 유지하기 위해 파인 튜닝에서도 적용함
GPT와 유사하지만, 더 적은 데이터셋을 학습함. 그리고 [CLS], [SEP]을 사용한 고유한 입력 방식. 테스크 통합된 아키텍쳐
QNLI, MNLI, SQuAD 1.1에서 NSP를 제거하면 성능 악화
단방향 모델 → 모든 작업에서 별로. 특히 MRPC, SQuAD에서 더 별로
SQuAD에서 직관적으로 생각하면 토큰 레벨 은닉 상태가 오른쪽 문맥이 없으니, 토큰 예측에서 성능 악화됨
BiLSTM 가중치를 랜덤으로 초기화해 시작 → 조금 개선됐으나, 사전 학습된 양방향 모델보다는 별로임
ELMo가 한 것처럼 양방향 은닉 벡터를 결합할 수도 있음. 그러나
- 2배 더 비쌈
- RTL 모델은 질문이 포함된 문장 앞쪽 정보를 반영하지 못하므로 QA와 같은 작업에 별로
- 깊은 양방향 모델은 모든 층에서 양방향 문맥을 사용할 수 있지만, 은닉 벡터 결합은 단순 결합이므로 별로
5.2 Effect of Model Size
레이어 수, 은닉 상태 크기, 어텐션 헤드를 다르게 하면서 실험함 → 이전에 명시한 하이퍼파라미터는 그대로
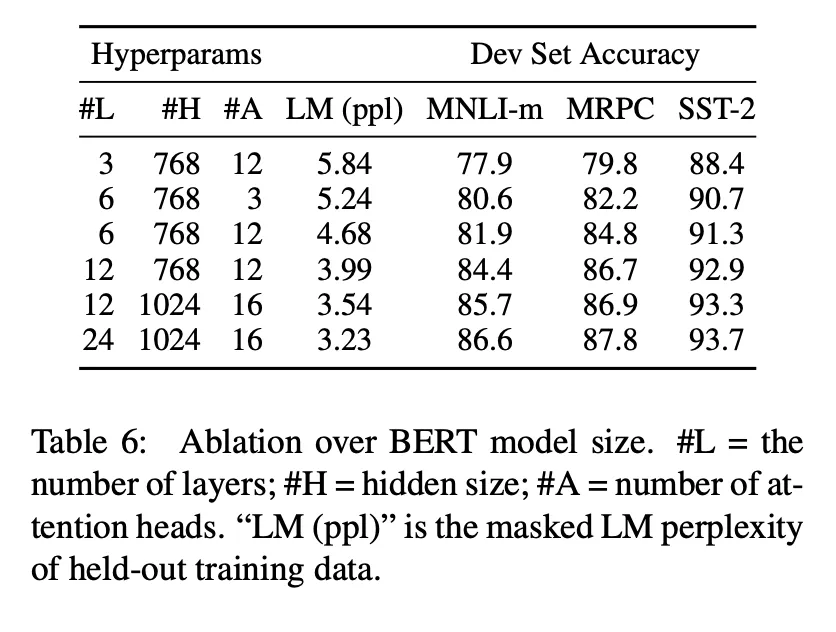
검증 데이터셋에서 평균 정확도를 기준으로 성능 평가. 파인 튜닝에서 5회 랜덤 재시작
모델 크기가 클 수록 모든 데이터셋에서 성능이 확실히 개선됨
3600개 레이블링 된 훈련 데이터인 MRPC에서도, 성능 향상. BERT의 사전 학습 목표와 많이 다름에도 불구하고
기존에 제시된 모델은 이미 상당히 큼. BERT는 모델 크기만 늘려도 성능 향상 달성함
모델이 커지면 성능 향상되는 건 널리 알려짐 → 기계 번역, 언어 모델링: 데이터 크기와 모델 표현력에 크게 의존함 → LM ppl
모델 크기 확장 효과를 명확히 입증한 최초의 연구. 소규모 데이터셋 테스크에서도 큰 성능 개선을 가져옴 → 사전 학습이 충분히 수행했을 때만. 일반화된 표현을 학습하면 작은 테스크에서도 효율적인 성능.
ELMo는 Bi-LM 레이어 수 늘렸을 때 안 그랬지?ㅋㅋ
contextual representation 연구에서는 은닉 벡터 차원을 200 → 600으로 늘렸을 때는 성능 향상 됐지만, 1000으로 확장했을 때는 성능 개선 X → 모델 크기과 성능 간 상관관계가 한계
위 두 가지 연구 모두 feature 기반 접근
5.3 Feature-based Approach with BERT
지금까지 전부 파인 튜닝 결과였음 → 사전 학습 모델에 단순한 분류 레이어만 추가했음. 모든 파라미터는 다운스트림 작업에 따라 동시에 업데이트함
사전 학습에서 추출된 고정된 features는 특징 기반 접근에서 확실한 이점
- 모든 테스크가 트랜스포머 인코더 구조에서 쉽게 표현되지 않음 → 테스크 특화된 추가 모델 구조가 필요함
- 좀 더 값 싼 모델이 한 번만 계산된 특징 벡터 위에서 학습함
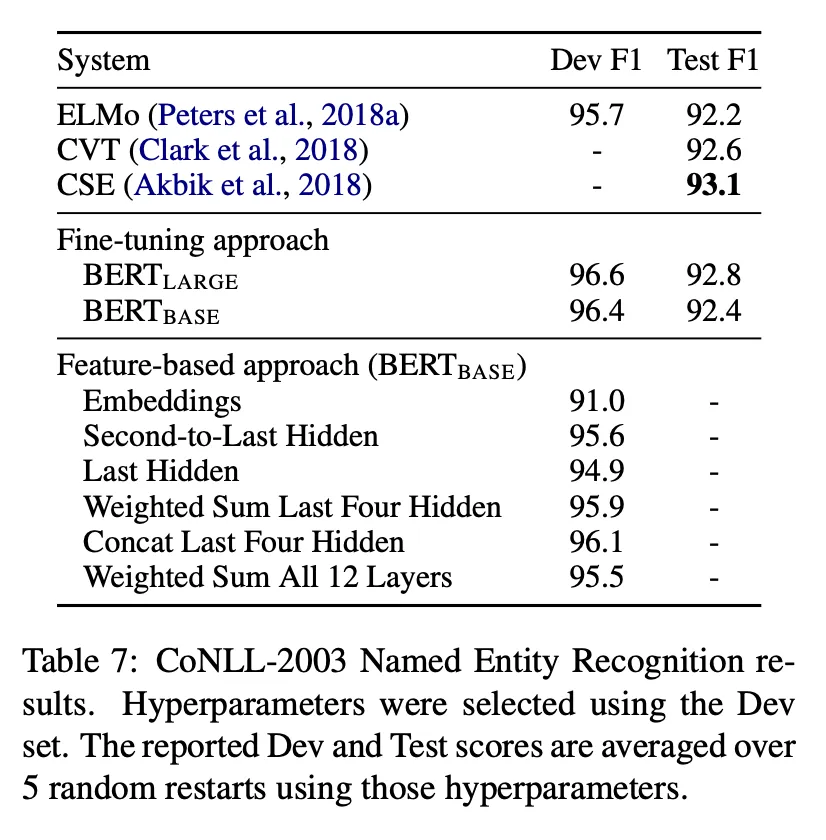
파인 튜닝과 고정된 특징 기반 접근 방법 비교함 → CoNLL 2003 NER 작업에서
대소문자 구분하는 WordPiece 토크나이저 활용, 가능한 최대한의 문서 문맥을 입력에 넣음
NER 테스크의 표준 접근법을 따름. 태깅 작업으로 변환. CRF(Conditional Random Field) 레이어 사용 X. 단순 분류기만 사용
첫 번째 서브토큰의 은닉 벡터를 활용해 NER 레이블 예측 → NER 분류기 입력으로 사용
파인 튜닝 접근 방법과 비교하기 위해서 최상 1개 이상 레이어를 조합한 테스크 별 모델만 학습. 파인 튜닝 없이
문맥적 임베딩은 양방향 LSTM을 2층으로 쌓음. 분류기 이전 768개 은닉 차원 크기.
BERTLARGE는 SOTA 접근법과 비슷하거나 그 이상
최상위 4개 레이어 출력을 연결한 Feature-based 방식 1황은 파인 튜닝과 0.3 F1 점수만 뒤쳐짐 → 너 가능성 있어
6. Conclusion
최근 입증된 성능 개선에서 풍부한 비지도 사전 학습은 많은 언어 이해 시스템에서 필수임. 전이 학습으로.
전이 학습 → 깊은 양방향 구조에서 적은 리소스
우리는 단방향 모델의 장점을 깊은 양방향 구조로 일반화했음 → 다양한 NLP 테스크에서 적용할 수 있음을 입증함
further readings
- Conditional Random Field란?
