본 포스팅은 김성범 교수님의 유튜브 강좌, 강필성 교수님의 유튜브 강좌, Kicarus 티스토리를 참고했습니다.
Boosting 개요
- 여러 개의 learning 모델을 순차적으로 구축하여 최종적으로 합침(Ensemble)
- 여기서 사용하는 learning 모델은 매우 단순한 모델: 정확도가 0.5보다 살짝 높음
- 순차적 → 모델 구축에 순서를 고려함
- 각 단계에서 새로운 base learner를 학습하여 이전 단계의 base learner의 단점을 보와
- 단계를 거치면서 모델이 점차 강해짐
Boosting 알고리즘 종류
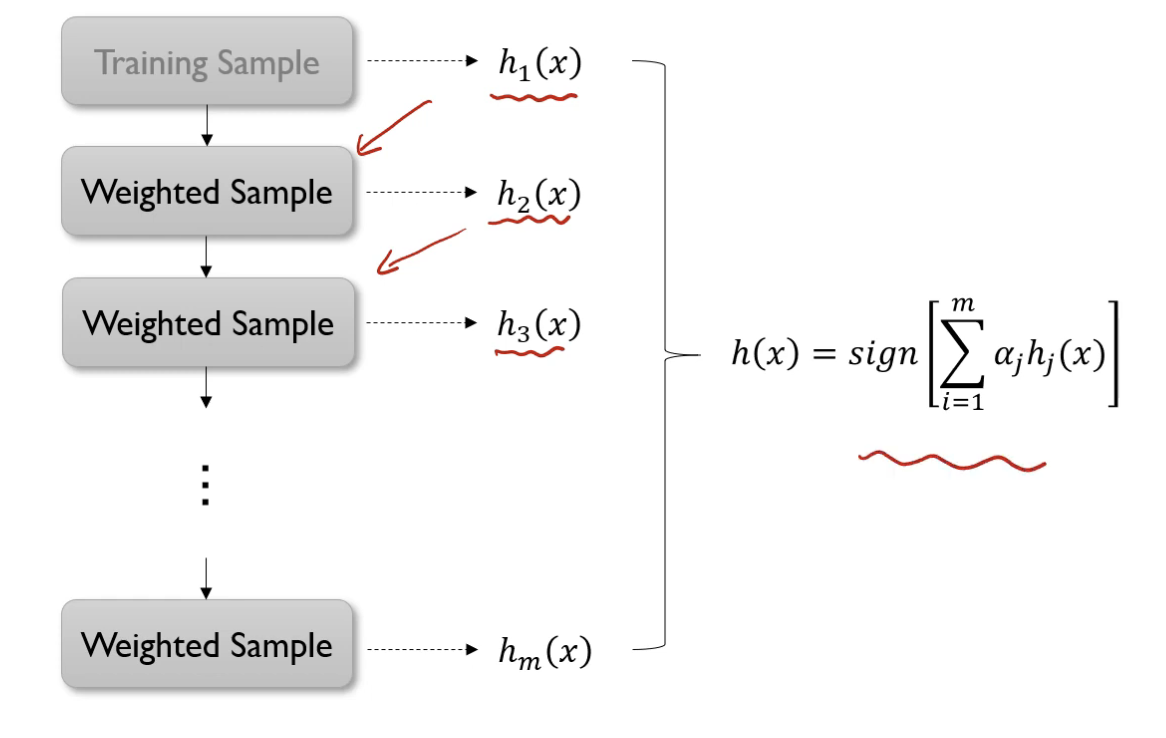
Adaptive Boosting(AdaBoost)
- 각 단계의 새로운 Base Learner를 학습하여 이전 단계의 Base Learner의 단점을 보완
- Training Error가 큰 관측츠의 선택 확률(가중치)을 높이고, Training Error가 작은 관측치의 선택 확률을 낮춤 → 오분류한 관측치에 보다 집중
- 앞 단계에서 조정된 확률(가중치)을 기반으로 다음 단계에거 사용될 Training Dataset을 구성
- 첫 단계로 돌아감(Recursive)
- 각 모델의 성능 지표를 가중치로 하여 결합(Ensemble)
pseudo code
for i = 1 to n:
W_i = 1 / n
for j = 1 to m: # m: classifier의 개수
L_j = 0
for i = 1 to n:
if y_i != h_j(x)
L_j += W_i
a_j = log((1 - L_j) / L_j)
for i = 1 to n
W_i = W_i * exp(a_j * I(y_i != h_j(x)))
h(x) = sign(sum(a_j * h_j(x)))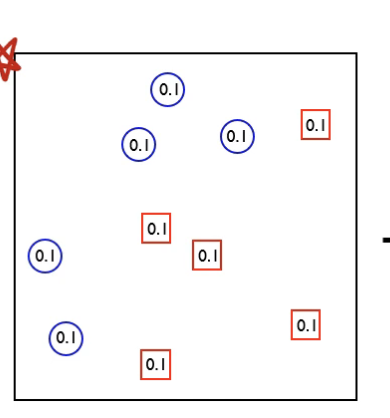
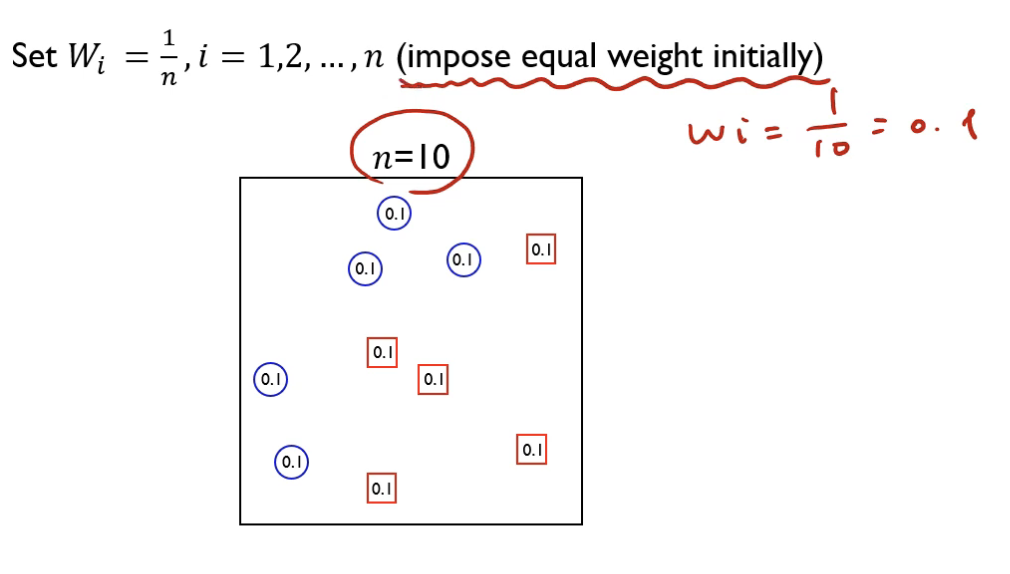
초기 가중치는 0.1이 된다 (1/10)

3개를 오분류 했으므로 Loss function 값이 다음과 같이 된다.
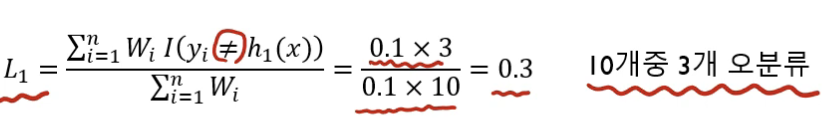
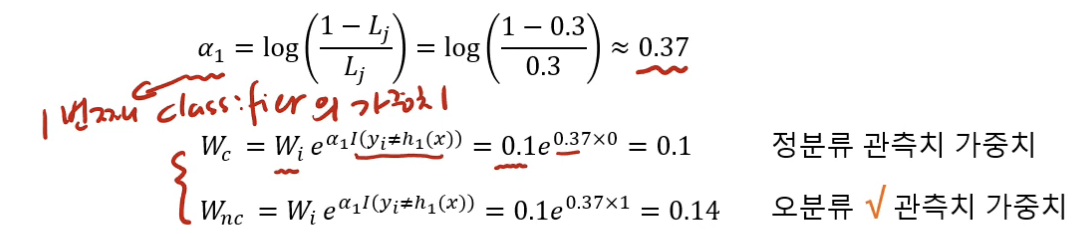
이때 값은 최종 모델을 결정할 때 모델 h_i의 가중치가 된다.
따라서 다음과 같이 업데이트 된다.

이러한 동작을 m번 반복한다.
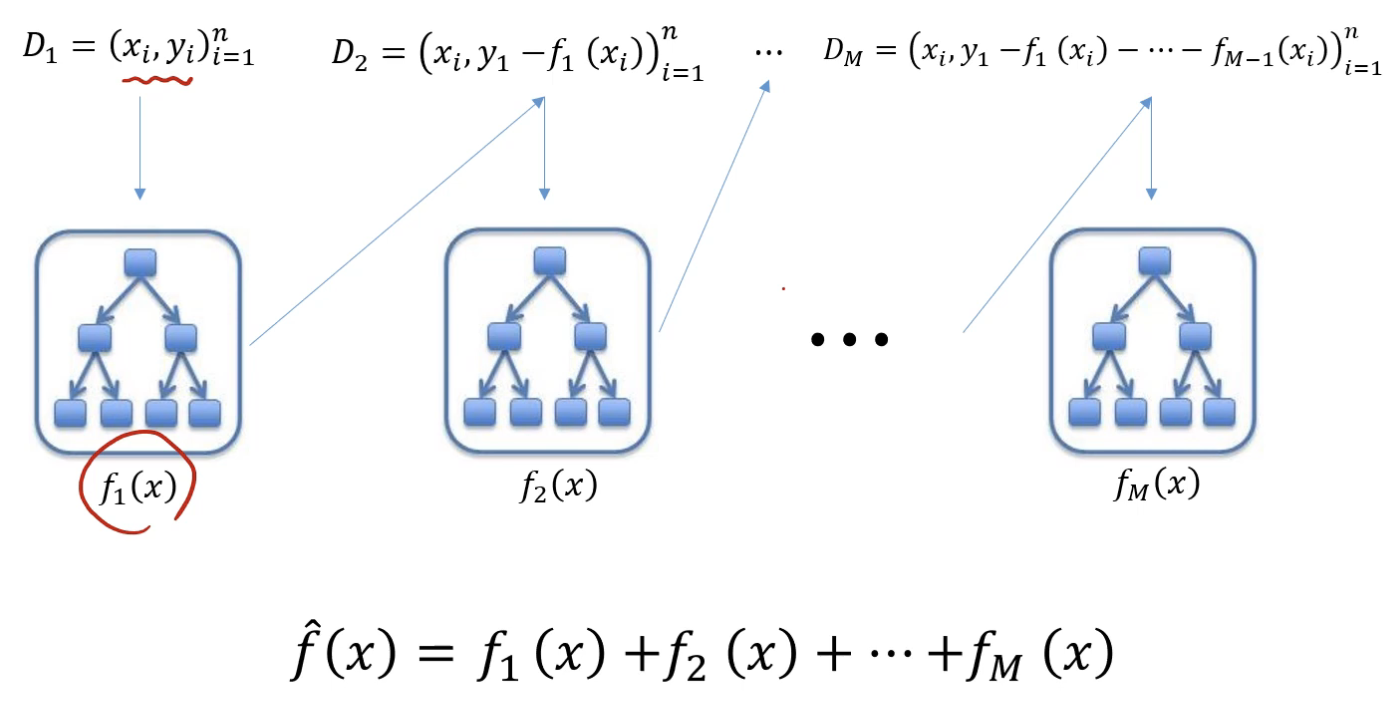
Gradient Boosting Machine(GBM)
- Gradient Boosting = Boosting with Gradient decent
- 첫 번째 단계의 모델 tree 1을 통해 Y를 예측하고, Residual(y - y_hat)을 다시 두 번째 단계 모델 tree 2를 통해 예측하면서 점차 residual을 작아지게 하는 방식

점과 선의 차이가 residual이다.
Gradient: 현재 Euclidean Distance가 Loss function이므로 residual = negative gradient

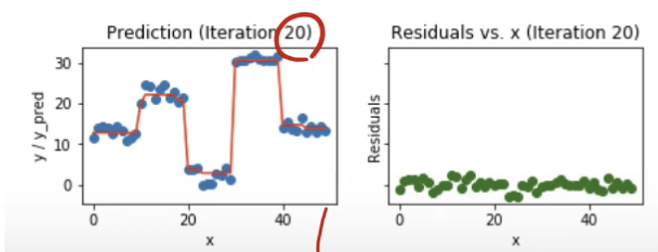
실제 데이터는 파란 점, 현재 모델은 빨간 선, residual 값은 초록 선이다.

Extreme Gradient Boosting (XGBoost)
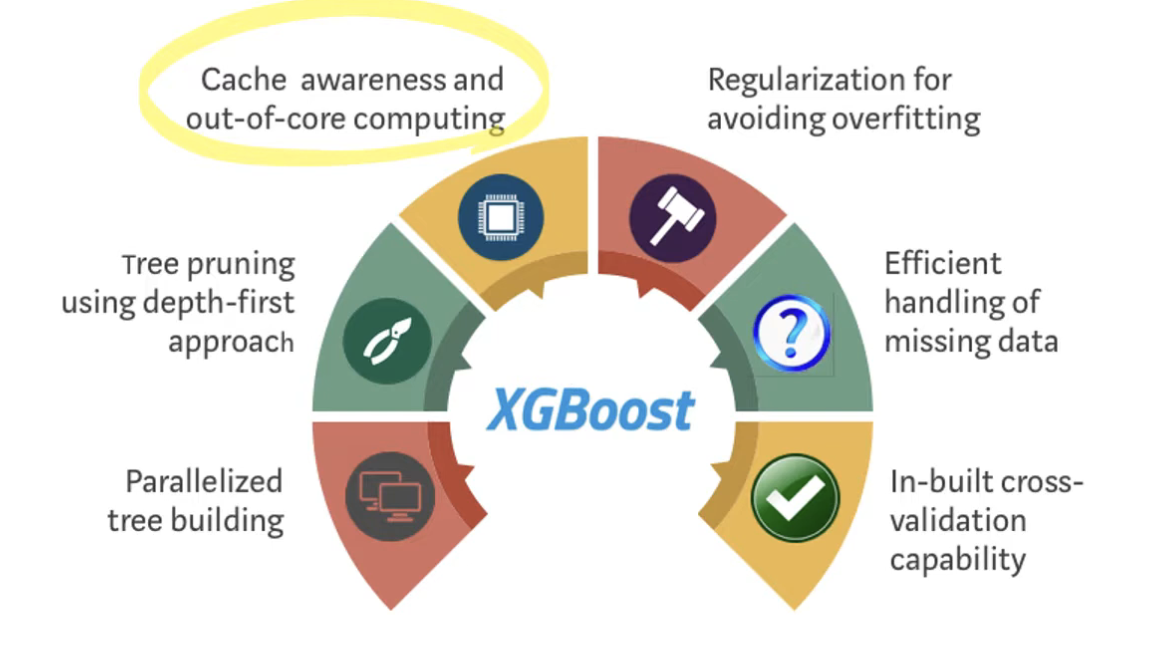
- 앙상블 학습을 진행하는 과정에서 이전 iteration에서 잘 학습하지 못한 부분에 가중치를 두고 학습하는 방식
- 손실 함수가 최대한 감소하도록 하는 split point를 찾는 것이 XGBoost의 목표
Split Finding Algorithm
Basic exact greedy algorithm
모든 데이터셋을 탐색하여 최적의 split point를 찾는다.
- pros: 모든 경우의 수를 다 탐색하므로 optimal split을 반드시 찾음
- cons: 데이터가 전부 메모리에 들어가지 않음, 병렬처리 불가
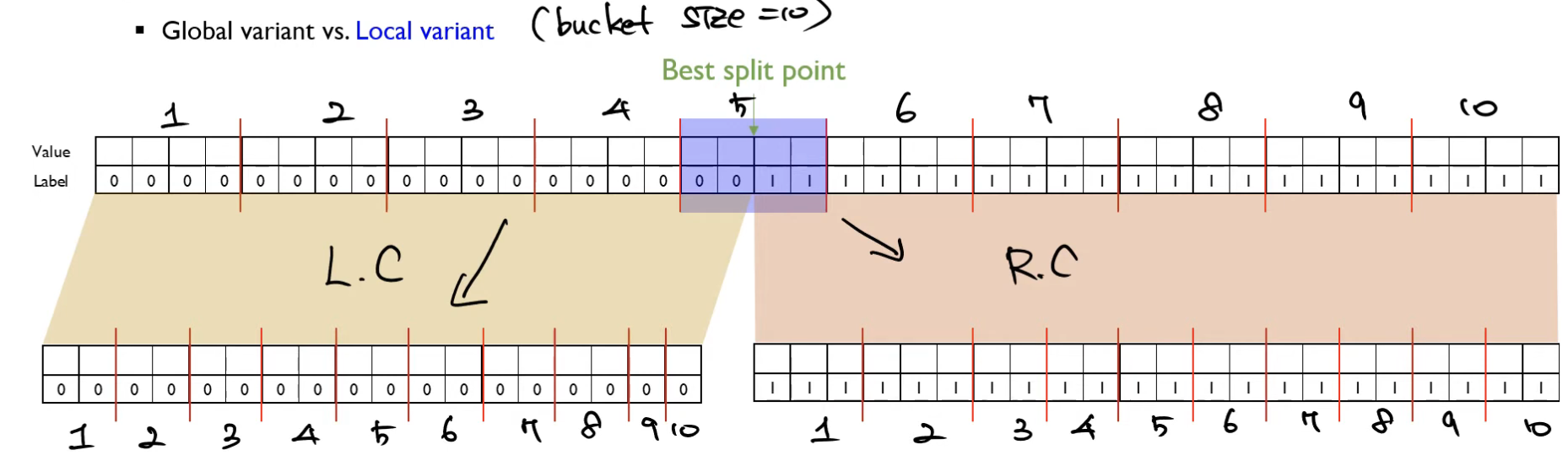
Approximate algorithm
1. 데이터 정렬 뒤 분할(분할될 데이터셋을 bucket이라 함)
2. bucket 별로 split point를 찾음

빨간 선이 bucket 분할이다. exact greedy algorithm은 모든 value-label 쌍을 전부 사용하여 gradient를 계산한다.
위 그림에서 bucket 별로 병렬 처리를 한다면, exact greedy는 39회 연산, approximation은 3회 연산으로 처리 가능하다.
Global Variant
한 번에 모든 Split point 후보군을 제시

Local Variant
매 iteration마다 Split point 후보군을 제시
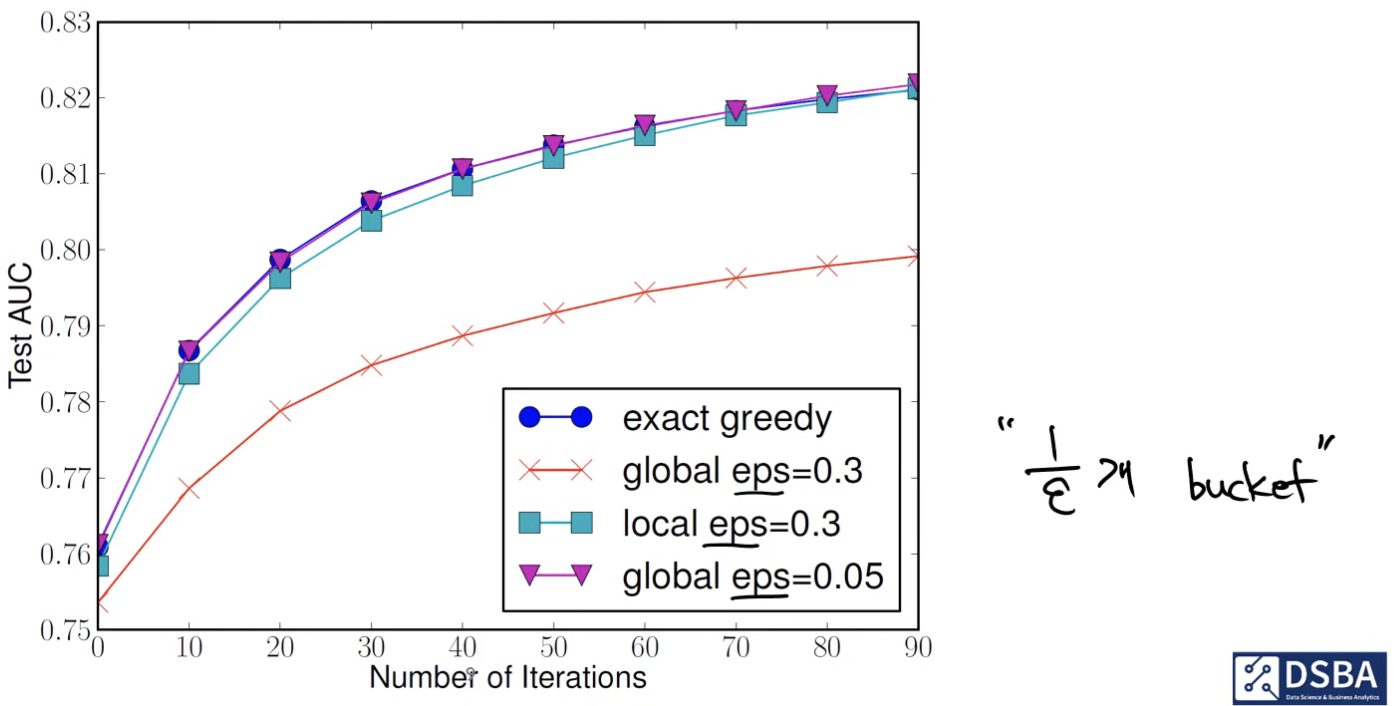
global eps << local eps 이어야 된다.
Sparsity-Aware Split Finding
- 결측치가 들어간 데이터셋에도 학습이 가능함
- default direction을 직접 찾아서 결측치일 경우 default direction으로 보낸다.
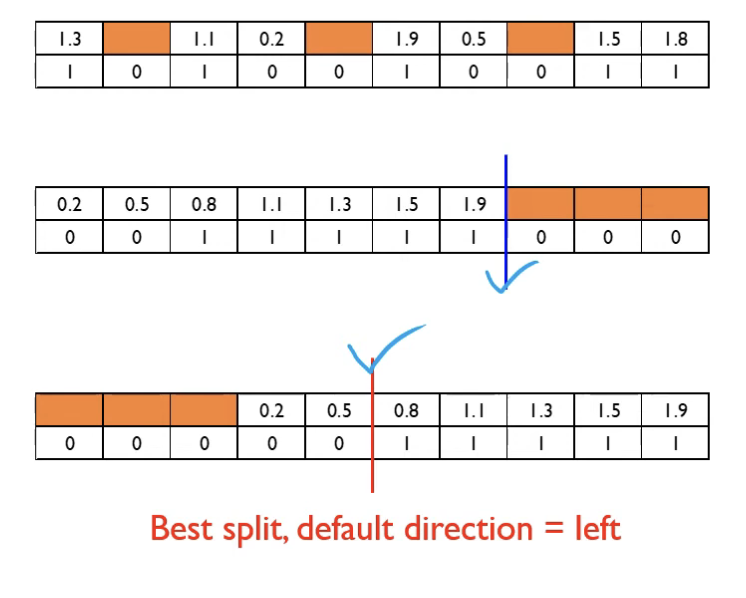
Efficient Computing
- XGBoost에서 가장 많은 시간이 소요되는 것 → 정렬
- 데이터를 컬럼 방향으로 저장하고 정렬 시 인덱스 변화하여 정렬
Cache-aware access
- 데이터를 'Block'으로 저장하고 사전 배열 → Gradient 통계치를 행 인덱스로 가져와야하므로 Cache miss가 자주 발생할 수 있음 → Cache-aware prefetch algorithm 사용
- 각 스레드 내 내부 버퍼 할당 → Gradient 통계를 mini batch 방식으로 가져옴 → 누적 계산
Out-of-core Computation
- 데이터가 메인 메모리에 전부 들어가지 않을 경우 디스크 공간을 활용하는 out-of-core 계산 기능 제공
- 블록 압축: 디스크에서 메모리까지 데이터 전송 속도 감소
- Sharding: 여러 디스크에 데이터를 분산시켜 IO throughput 증가
Light Gradient Boosting Machine(LightGBM)
-
모든 feature로 동작함 → Exclusive Feature Bundling(EFB)
feature space가 sparse할 경우 거의 exclusive이다.(one-hot encoding) → bundling 해도 퍼포먼스 저하 X -
모든 데이터 객체로 동작함 → Gradient-based One Side Sampling(GOSS)
gradient가 크면 중요도도 커진다 → 크면 keep, 작으면 randomly drop
Gradient-based One Side Sampling

a와 b를 어떻게 설정하는지에 따라 성능이 다름
Exclusive Feature Bundling

특징을 뽑아서 하나의 변수로 표현

vertex를 feature, edge를 feature 간 conflict라고 보면 서로 이웃하지 않은 모든 feature를 하나의 bundle로 묶는다.(cut-off가 conflict의 threshold 값)
CatBoost
- 카테고리형 데이터 자동 처리
- 순서 기반 부스팅(order-based boosting) → 과적합(overfitting)을 줄이고 예측 성능 개선
- Target Statistic(TS):

Greedy TS
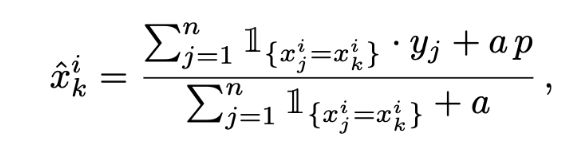
a, p: 데이터의 노이즈를 줄이기 위한 파라미터
- 가 Target value인 로부터 산출됨 → target leakage
- train-test 데이터 분포에 따른 오류 발생 가능
- conditional shift → Property 1. 이를 방지하기 위해 train, test의 TS 평균 값이 같아야 한다
Holdout TS
conditional shift를 방지하기 위해 train 데이터를 두개로 나누어 각각 TS 계산과 학습에 이용 → 학습 데이터 양 줄어듦 → Property 2. 모든 학습 데이터를 TS 계산과 학습에 사용해야 한다.
Leave-one-out TS
하나의 데이터를 제외하고 TS 계산
Ordered TS
- 데이터셋에 random permutation 값 부여
- k번째 데이터의 TS: k-1번까지의 TS만 사용 → Property 1, 2 둘 다 만족, CatBoost에서도 해당 TS를 사용함
Prediction Shift
- 정의: target value를 활용하여 생기는 target leakage → 입력 데이터셋과 출력 값의 분포 차이와 overfitting 발생하는 현상
- 해결하기 위해서는 매 스텝마다 다른 데이터셋(independent samples)를 활용해야 함 → 트리를 구성하는 매 스텝마다 임의의 permutation으로 샘플링하여 independent sample 구성
Ordered Boosting
- permutation 값에 따라 gradient 계산
- 이전 스텝 트리 leaf에 gradient 평균 할당하면서 permutation 순서에 따라 leaf value 할당
- 사전에 계산된 gradient와 새로 할당된 leaf value 사이에 cosine similarity 계산 후 가장 작은 부분에서 split point 생성
- 1 ~ 3 과정 반복
CatBoost는 Oblivious Decision Tree(ODT) 형태 트리 사용(좌우 대칭) → overfitting 방지, 테스팅 소요 시간 감소
