- 머신러닝과 딥러닝의 차이점은 무엇인가요?
- 머신러닝은 딥러닝의 상위 개념, 머신러닝은 데이터와 정답(레이블)을 통해 규칙을 찾는 모델인 반면, 딥러닝은 인공신경망 층이 쌓인 머신러닝 모델
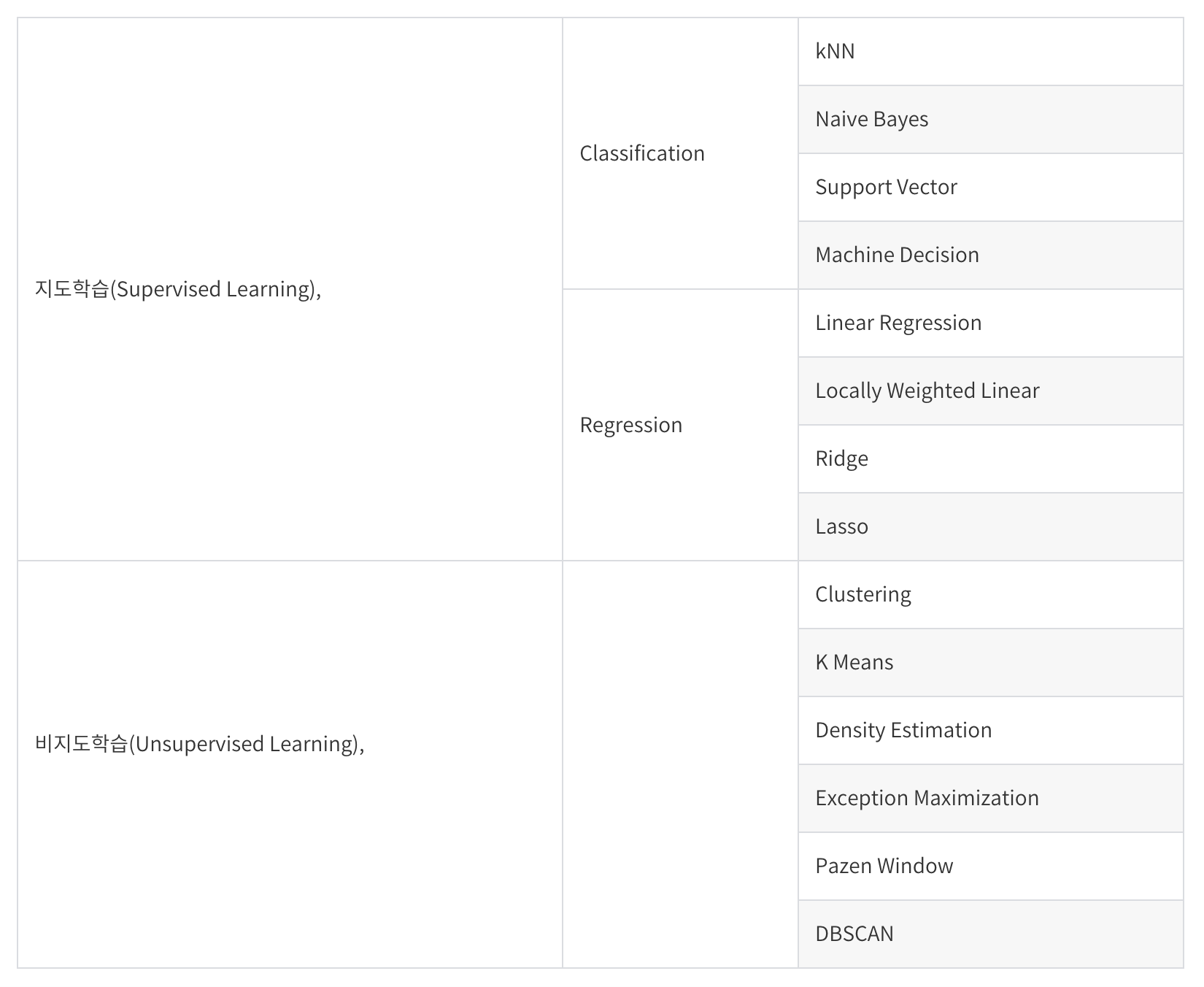
- 지도학습과 비지도학습의 차이점은 무엇인가요?
- 둘 다 데이터셋을 활용하여 학습함. 지도학습은 정답 라벨이 있는 반면, 비지도학습은 정답 라벨이 없음
- 과적합(Overfitting)이란 무엇이며, 어떻게 방지할 수 있나요?
- 정의: 모델이 훈련 데이터에 너무 잘 맞춰져 있어(loss function의 값이 낮아) 테스트 데이터 혹은 새로운 데이터에 일반화 성능이 떨어지는 현상
- Cross Validation, Drop-out, Early Stopping, Ensemble이 과적합을 방지하는 방법이다.
- 교차 검증(Cross-validation)이란 무엇이고 왜 사용하나요?
- 정의: validation set을 활용하여 모델을 학습하고 검증하는 방법
- 고정된 test set으로 모델 검증을 반복하면 test set에 과적합된다. 따라서 train set을 train + validation으로 분할하고 validation set을 바꿔가며 검증하는 방법이다.
- 정밀도(Precision)와 재현율(Recall)의 차이점은 무엇인가요?

- Precision: → 분류를 참으로 했는데 실제 참인 비율
- Recall: → 실제 참 중, 모델이 참으로 예측한 비율
- 랜덤 포레스트(Random Forest)와 그래디언트 부스팅(Gradient Boosting)의 차이점은 무엇인가요?
- Decision Tree: 분류 문제에서 입력 데이터에 대해 각 분기 별로 질문을 통해 데이터를 분류하는 트리 구조의 모델.
- Random Forest: Bagging(Bootstrap AGgergation, 각기 다른 Decision Tree를 취합하여 학습)을 활용한 Decision Tree
- Gradient Boosting: Boosting, 즉 이전 샘플의 결과로 가중치를 업데이트하여 다음 샘플의 결과를 반영하는 모델
- SVM(Support Vector Machine)이란 무엇이며, 어떻게 작동하나요?
- 정의: 데이터의 Margin을 최대로 가지는 Hyper-plane을 찾는 모델.
- kernel space, c, gamma 값을 통해 Hyper-plane을 찾아서 동작함
- 차원의 저주(Curse of Dimensionality)란 무엇이며, 어떻게 해결할 수 있나요?
- 정의: 학습 데이터 수가 데이터 차원 수보다 적을 때 발생, 모델 학습 정확도가 떨어진다.
- 데이터 차원을 축소하여 모델을 학습한다.
- ROC 곡선과 AUC는 무엇을 의미하나요?
- ROC(Receiver Operating Characteristic): x축은 FP 비율, y축은 TP 비율일 때 다양한 threshold 값에 따른 모델의 예측치를 나타낸 값이다. 왼쪽위 (0, 1)에 가까울 수록 성능이 좋다.
- AUC(Area Under the Curve): ROC 곡선의 적분 값이다.
- 결정 트리(Decision Tree)의 작동 원리는 무엇인가요?
- 6번 질문 참고
- K-최근접 이웃(K-NN) 알고리즘이란 무엇이며, 어떻게 작동하나요?
- 정의: 타겟 샘플을 k개의 인접한 데이터와 비교해 분류하는 알고리즘
- Euclidean 거리를 사용하기 때문에 데이터 정규화를 해준다.
- 특성 선택(Feature Selection)과 특성 추출(Feature Extraction)의 차이는 무엇인가요?
- Feature Selection: 기존 Feature의 부분을 사용함. Feature vector의 크기가 감소하기 때문에 모델 성능이 좋아진다.
- Feature Extraction: 기존 Feature를 활용하여 새로운 Feature를 생성함.
- 배치 학습(Batch Learning)과 온라인 학습(Online Learning)의 차이점은 무엇인가요?
- Batch Learning: 데이터를 전부 활용하여 학습하는 방식, 리소스를 많이 소모함
- Online Learning: 데이터를 mini-batch 단위로 나눠 순차적으로 학습하는 방식, 나쁜 데이터가 주어진다면 점차적으로 성능 감소 → 모니터링 필요
- 손실 함수(Loss Function)란 무엇이며, 왜 중요한가요?
- 정의: 실제 데이터와 모델 추정치의 차이를 나타낸 함수.
- 모델은 손실 함수를 최소화하는 방향으로 가중치를 업데이트하며 학습이 이루어진다.
- 경사하강법(Gradient Descent)이란 무엇이며, 어떻게 작동하나요?
- 정의: 1차 근삿값 발견용 최적화 알고리즘
- 시작점에서 음의 기울기 방향으로 방향 업데이트
- 학습률(Learning Rate)의 역할은 무엇인가요?
- Learning Rate는 학습 속도를 결정하는 수치이다. 너무 작을 경우에는 학습 속도가 느려지고 너무 클 경우에는 학습 도중에 발산할 가능성이 있다.
- 하이퍼파라미터(Hyperparameter)와 파라미터의 차이점은 무엇인가요?
- 파라미터는 데이터에 의해서 결정되는 값. 평균, 표준편차 등이 있음.
- 하이퍼파라미터는 사용자가 결정하는 값. learning rate도 하이퍼파라미터의 한 종류임
- 정규화(Regularization)란 무엇이며, 왜 사용하나요?
- 데이터 분포를 0~1로 일정하게 맞춰 모델 학습 용이를 위함
- 평가 지표(Evaluation Metrics) 중 정확도(Accuracy)만이 항상 좋은 지표는 아닌 이유는 무엇인가요?
- 데이터 불균형, 특정 클래스가 중요한 경우에 정확한 모델 성능을 반영하지 못할 수 있음
- 성능 지표의 다양성을 위함
- 데이터 전처리(Data Preprocessing)에서 수행하는 주요 작업은 무엇인가요?
- 데이터 수집 → 데이터 정제 → 데이터 통합 → 데이터 축소 → 데이터 변환
- 이상치(Outlier)를 처리하는 방법에는 어떤 것들이 있나요?
- 통계적 방법: Z-Score, IQR(Interquartile Range) → 정규 분포를 따르는 데이터
- 시각적 방법: 데이터 분포를 시각화하여 outlier 처리
- 머신러닝 기반: Regression Decision Tree 기반 Isolation Forest, DBSCAN(Density-Based Spatial Clustering of Applications with Noise)
- 피처 스케일링(Feature Scaling)의 목적은 무엇이며, 어떤 방법을 사용할 수 있나요?
- 클래스의 단위를 무시하거나, 특정 클래스 편향을 방지하기 위함
- 분산이 1, 평균이 0인 가우시안 분포로 만드는 standardization, 0~1 사이 값을 만드는 normalization이 있음
- PCA(주성분 분석)란 무엇이며, 언제 사용하나요?
- 고차원 데이터의 차원을 축소하여 핵심적인 특성을 추출하는 기법으로 데이터 정규화 → 공분산 행렬 계산 → 고유값 및 고유벡터 계산 → 주성분 선택 → 차원 축소 순으로 진행된다.
- RNN(Recurrent Neural Network)과 CNN(Convolutional Neural Network)의 차이점은 무엇인가요?
- RNN: 현재 출력 결과가 이전 time step에 영향을 받음
- CNN: window(filter)를 통한 convolution 연산과 pooling 연산으로 구성
- LSTM(Long Short-Term Memory)이란 무엇이며, 어떻게 작동하나요?
- RNN이 긴 기간의 의존성을 완전히 다룰 수 없기 때문에 input/output gate, forget gate를 사용하여 현재 파라미터를 얼마나 버릴 지 결정한다.
- 데이터 불균형(Data Imbalance)을 처리하는 방법은 무엇인가요?
- Under Sampling, Over Sampling, Data Augmentation
- Random Under Sampling, Tomek link, Condensed Nearest Neighbour, Edited Nearest Neighbours
- Random Over Sampling, Adaptive Synthetic Sampling(ADASYN), SMOTE
- 앙상블 학습(Ensemble Learning)이란 무엇이며, 어떤 장점이 있나요?
- 분류 문제에서 여러 개의 개별 모델을 조합해서 최적의 모델로 일반화하는 방법. Bagging, Voting, Boosting, Stacking이 있다. Decision Tree의 오버피팅을 방지한다.
- 학습 곡선(Learning Curve)을 해석하는 방법은 무엇인가요?
- 모델의 정확도가 전체적으로 증가하고 있는지, 손실 함수 값이 전체적으로 감소하고 있는지 확인
- 데이터 세트를 훈련, 검증, 테스트 세트로 분할하는 이유는 무엇인가요?
- 학습에서 오버피팅을 방지하기 위함
- 모델의 복잡도와 일반화 사이의 관계를 설명해주세요.
- 복잡도: 데이터의 패턴이나 관계의 복잡성 의미로 파라미터 수, 레이어 수, 뉴런 수로 결정 → 과적합 위험
- 일반화: 새로운 데이터에 대해서 잘 작동하는 능력
- 머신러닝 프로젝트에서 데이터 리킹(Data Leaking)이란 무엇이며, 어떻게 방지할 수 있나요?
- training 데이터 외의 정보가 모델에 사용될 때 발생, cross validation 내부에서 데이터 준비 수행
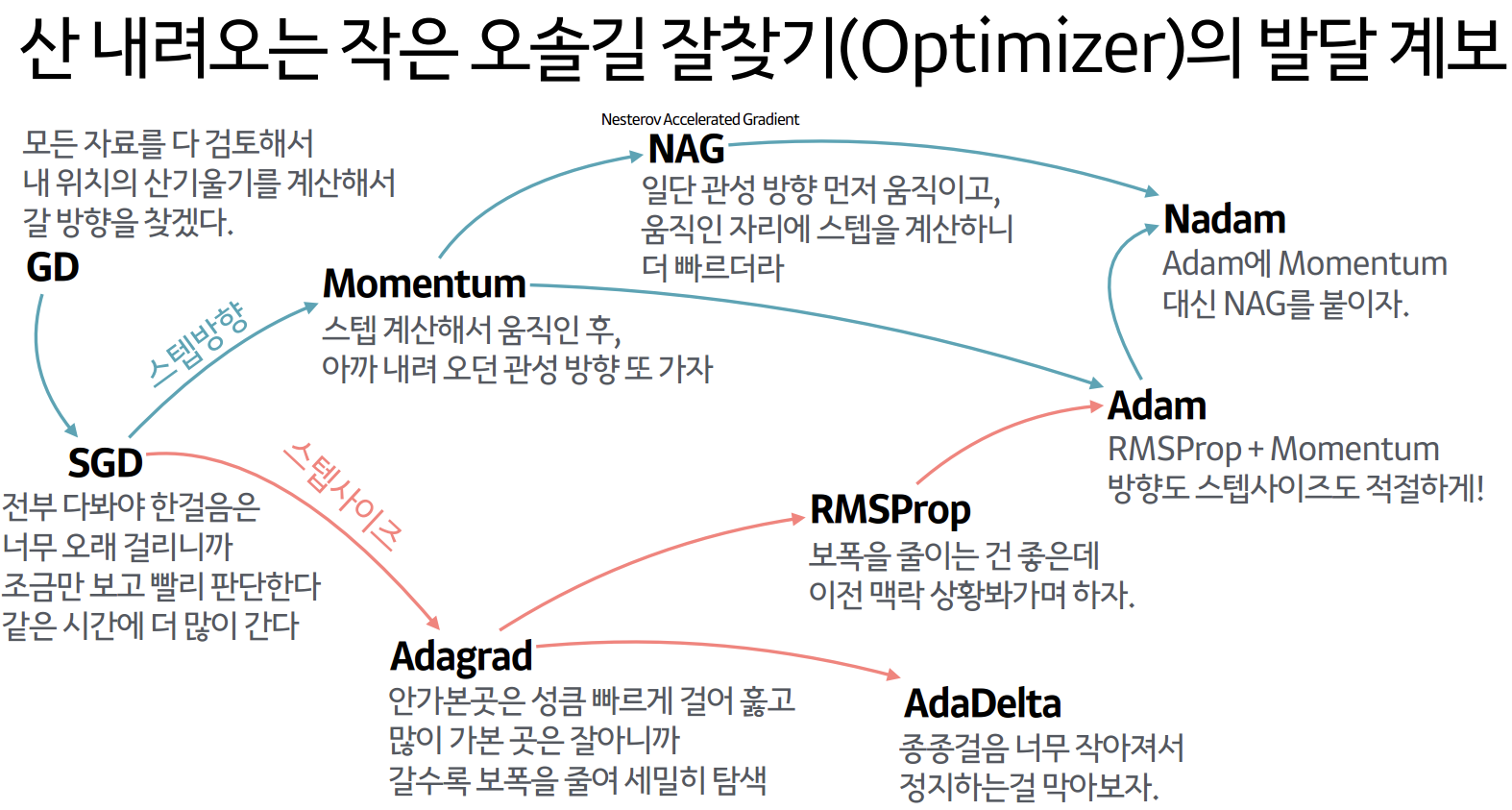
- 머신러닝에서 사용되는 다양한 최적화 알고리즘에는 어떤 것들이 있나요?
- 텍스트 데이터를 처리하기 위한 전처리 단계에는 어떤 것들이 있나요?
- 형태소 분리 → 불용어 처리 → 동의어 mapping → dictionary 생성 → 인코딩
- 자연어 처리(NLP)에서 언어 모델(Language Model)의 역할은 무엇인가요?
- 문장 시퀀스를 확률적으로 분석
- 문맥 이해
- 텍스트 생성
- 기계 번역
- 강화학습(Reinforcement Learning)의 기본 원리는 무엇인가요?
- 어떤 환경 안에서 정의된 에이전트가 현재 상태를 인식하여, 선택 가능한 행동들 중 보상을 최대화하는 행동 혹은 행동 순서를 선택하는 방법
- Exploration & Exploitation: 에이전트는 환경을 탐색하면서 새로운 행동 시도와 주어진 정보 기반 최적의 행동 선택 사이에 균형을 맞춰야함
- Reward Signal: 행동의 결과로 보상을 받음. 에이전트 행동의 판단 기준
- Policy Update: 받은 보상을 기반으로 정책(행동의 집합)을 개선
- State Value Function, Q-Value Function: 현재 상태에서 다음 상태를 기대하는 함수와 현재 상태에서 다음 상태와 동작을 기대하는 함수로 다음 행동 추론
- 에이전트(Agent), 환경(Environment), 보상(Reward)의 관계를 설명해주세요.
- 강화학습에서 사용되는 개념, 강화학습의 정의는 35에 있음
-
몬테 카를로(Monte Carlo) 방법과 TD(Temporal Difference) 학습의 차이점은 무엇인가요?
MC
에피소드(시작부터 종료까지 일련의 상태와 행동)별 학습
보상의 총합 기반 → 초기 추정치가 매우 변동적임TD
각 시간 별로 바로 학습 가능 → 실시간 학습 가능
현재 상태의 추정 가치와 다음 상태의 추정 가치의 시간차 오류 사용 학습 -
Q-러닝(Q-Learning)과 SARSA의 차이점은 무엇인가요?
- Q-Learning(off-policy): 에이전트가 현재의 정책과 관계없이 학습할 수 있음 → exploration 중에 다양한 행동, 학습 과정은 최적의 행동
- SARSA(on-policy, State, Action, Reward, State, Action):
- 강화학습에서 탐험(Exploration)과 활용(Exploitation)의 균형을 맞추는 방법은 무엇인가요?
- -greedy: 대부분의 시간 동안 최적의 행동 선택 → 작은 확률 으로 무작위 행동 선택. 값이 시간에 따라 변화하기도 함
- Upper Confidence Bound: 확신이 낮은 행동을 시도해 정보를 얻고 시간이 지나고 더 확실한 행동으로 집중
- Thompson Sampling: 각 행동의 보상 분포 추정 업데이트 → 샘플링으로 그 시점의 최적의 행동 결정
- Softmax Selection: 각 행동의 가치 기반 확률적으로 행동 선택, Temperature parameter로 exploration과 exploitation을 조절 가능
- 전이 학습(Transfer Learning)이란 무엇이며, 어떤 경우에 유용한가요?
- 이미 학습된 모델을 다른 관련 task에 적용하는 방법
- 훈련 데이터가 부족할 때, 학습 시간 단축과 모델 성능을 기대할 수 있다.
- 멀티 태스킹(Multi-tasking)과 메타 학습(Meta-learning)의 차이점은 무엇인가요?
- 멀티 태스킹: 하나의 모델에서 다른 작업을 동시에 진행함 → 모델 일반화를 높이고 각 작업 성능을 효율적으로 올릴 수 있음
- 메타 학습: 학습을 학습하는 방법 → 모델이 다양한 task를 효율적으로 학습하는 법을 배우는 것, 새로운 task에 빠르게 적응할 수 있음
- 머신러닝 모델의 성능을 평가할 때 사용할 수 있는 다양한 기법들은 무엇인가요?
- Confusion Matrix, ROC/AUC, Cross Validation, Mean-Absolute-Error/Mean-Squared-Error
- 데이터 증강(Data Augmentation)이란 무엇이며, 어떻게 사용할 수 있나요?
- 기존 데이터셋을 변형/확장하여 데이터 양을 늘리는 기법 → 모델 일반화 능력 향상
- 회전, 반전, 스케일 조정
-
머신러닝 모델을 프로덕션 환경에 배포하기 전에 고려해야 할 사항은 무엇인가요?
- 모델 성능 평가:
정확도:
다양한 데이터셋 (훈련, 검증, 테스트)에서 모델 정확도를 측정하고 비교합니다.
정확도 지표 (예: AUC, RMSE)를 사용하여 모델 성능을 정량화합니다.
안정성:
모델 드리프트 (성능 변화)를 모니터링하고 감지합니다.
모델 재학습 및 버전 관리를 통해 안정성을 유지합니다.
재현성:
동일한 데이터셋과 설정으로 모델 학습 시 동일한 결과를 얻을 수 있도록 테스트합니다.
랜덤 시드 고정, 모델 저장 및 로딩 기능 활용 - 모델 배포 환경 구축:
모델 서빙:
Flask, TensorFlow Serving, KServe 등을 활용하여 모델 예측 API를 구축합니다.
모델 서빙 환경 (하드웨어, 소프트웨어)을 프로덕션 환경과 동일하게 구성합니다.
모니터링:
Prometheus, Grafana 등을 활용하여 모델 성능, 데이터 분포, 시스템 상태 등을 모니터링합니다.
이상 감지 알림 시스템을 구축하여 문제 발생 시 신속하게 대응합니다.
자동화:
Jenkins, GitLab CI/CD, GitHub Actions 등을 활용하여 모델 학습, 배포, 테스트 과정을 자동화합니다.
지속적인 통합/배포 (CI/CD) 파이프라인을 구축하여 배포 프로세스를 효율화합니다. - 모델 관리:
버전 관리:
Git, GitHub, GitLab 등을 활용하여 모델 코드, 데이터, 설정 등을 버전 관리합니다.
모델 버전 추적, 비교, 롤백 기능을 활용하여 모델 관리를 효율화합니다.
모델 설명:
모델 카드, 설명 문서 등을 작성하여 모델 작동 방식, 예측 결과 해석 등을 명확하게 설명합니다.
모델 설명 툴 (ModelCard, SHAP) 활용 - 모델 보안:
암호화:
모델 코드, 데이터, 설정 등을 암호화하여 보호합니다.
암호화 라이브러리 (PyNaCl, OpenSSL) 활용
접근 제어:
모델 API에 대한 접근 권한을 제어합니다.
역할 기반 접근 제어 (RBAC) 시스템 활용 - 추가 고려 사항:
모델 설명:
ModelCard, SHAP 등을 활용하여 모델 작동 방식, 예측 결과 해석 등을 설명합니다.
모델 모니터링:
Prometheus, Grafana 등을 활용하여 모델 성능, 데이터 분포 변화 등을 지속적으로 모니터링합니다.
모델 재학습:
새로운 데이터가 확보되거나 모델 성능이 저하될 경우 모델 재학습을 진행합니다.
모델 버전 관리 시스템 활용
- 모델 성능 평가:
-
모델의 추론 속도(Inference Speed)를 개선하기 위한 방법에는 어떤 것들이 있나요?
- 모델 경량화: Pruning, Quantization
- 모델 아키텍쳐 최적화: 더 빠른 추론을 위해 고안된 아키텍쳐 사용(MobileNets, EfficientNets)
- 병렬 처리: GPU/TPU 등 하드웨어 가속기 사용
- 모델 서빙 최적화: Batch 처리, 멀티 스레딩
- 머신러닝 모델의 윤리적 고려사항에는 어떤 것들이 있나요?
- 모델 결정 과정과 데이터를 명확하게 이해할 수 있어야 함
- 학습 데이터의 다양성과 편향 고려
- 예측 가능한 결과를 도출해야 함
- AI와 머신러닝에서의 바이어스(Bias)와 공정성(Fairness)의 중요성은 무엇인가요?
- 데이터가 특정 그룹에 긍정/부정적으로 쏠리지 않고 데이터를 도출해야 한다.
- 페더레이티드 러닝(Federated Learning)이란 무엇이며, 어떤 장점이 있나요?
- 데이터를 중앙 서버로 전송하지 않고 로컬에서 모델을 학습시키는 분산 학습 기술
- 모델의 업데이트만 중앙 서버로 전송하여 전체 모델 개선
- 데이터 프라이버시/보안 향상, 네트워크 대역폭 감소, 엣지 컴퓨팅 환경에서 AI 사용 가능
- GAN(Generative Adversarial Networks)의 기본 원리는 무엇이며, 어떤 용도로 사용할 수 있나요?
- Generator와 Discriminiator 네트워크로 구성
- Generator: 실제 데이터와 유사한 데이터를 생성하려고 함
- Disciminator: 받은 데이터가 실제인지 생성된 것인지 판별함
- 두 네트워크에 경쟁으로 점점 더 실제와 유사한 데이터를 생성하게 됨
- 이미지 생성/변환, Data Augmentation 등
- 최근 머신러닝 분야에서 주목받는 연구 주제나 기술 트렌드는 무엇인가요?
- LLM, (이미지, 음악, 텍스트)생성 모델, 강화 학습, XAI, AGI

Someday, the dream will come true