Codeit_머신러닝
1.선형대수학

일차식이나 일차 함수를 공부하는 학문머신러닝을 할 때 데이터를 일차식에 사용하는 경우가 많으므로 머신러닝에는 선형대수학이 필수이다.행렬은 수를 직사각형의 형태로 나열한 것행(row) : 행렬의 가로줄열(column) : 행렬의 세로줄배열이나 리스트의 인덱스는 0부터 시
2.Machine Learning

머신러닝이란? Model : 서로 다른 변수들 사이에 존재하는 수학적 관계 머신러닝 : Data로부터 Model을 컴퓨터가 스스로 학습하여 사용하는 것 컴퓨터의 성능이 좋아지고 사용할 수 있는 data의 양이 많아지며 활용성이 증명되었기 때문에 최근 들어 머신러닝이 핫
3.미분
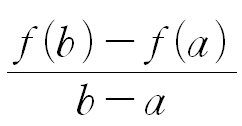
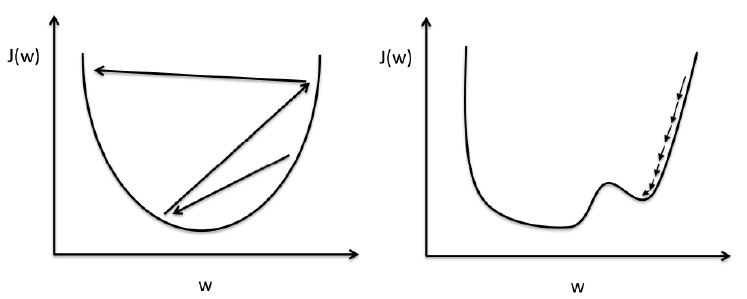
주어진 구간에서 평균적으로 함수가 단위당 변화한 양을 측정한 것어느 한 점에서의 접선의 기울기함수의 순간변화율을 구하는 방법x의 변화에 따른 순간 변화율을 계산극소점(local minimum) : 순간변화율이 음수 → 0 → 양수 가 되는 지점극대점(local maxi
4.선형회귀
선형 회귀(Linear Regression) 지도 학습 중 회귀에 해당한다. data에 가장 알맞는 선(최적선)을 찾는 것 단순하고 유용하며 다른 알고리즘의 기반이 된다. 목표 변수(target variable) : 맞추려고 하는 값 입력 변수(feature) : 맞추
5.다중 선형 회귀

기존 선형회귀는 X, Y가 하나씩 존재했지만, 다중 선형회귀는 여러개의 특성을 이용하여 종속변수를 예측한다.속성(feature) : 입력변수입력 변수가 여러개인 일차식→ 선형대수학의 벡터를 이용하여 가설함수를 표현다중 선형 회귀에서는 입력변수가 여러개이기 때문에 the
6.다항 회귀
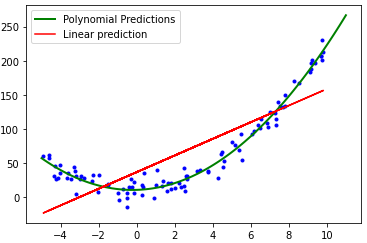
데이터에 잘 맞는 일차 함수나 직선을 구하는 게 아니라 다항식이나 곡선을 구해서 학습하는 것선형 회귀는 속성이 모두 독립적이기 대문에 변수들 사이 관계를 최종 예측 결과에 반영하지 못한다.이를 다항 회귀 문제로 만들면 속성들 사이에 있을 수 있는 복잡한 관계들을 프로그
7.로지스틱 회귀
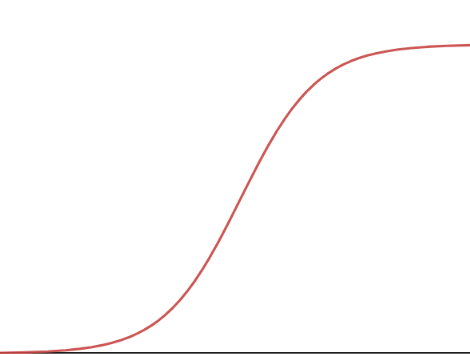
로지스틱 회귀(Logistic Regression) 선형회귀 분류는 예외적인 데이터에 민감하기 때문에 로지스틱 회귀를 주로 사용한다. 시그모이드 함수를 이용하여 주로 분류를 하는데 사용된다. > 분류를 하기 위해 사용되는 데 왜 로지스틱 '회귀'인가? 시그모이드 함수
8.데이터 전처리
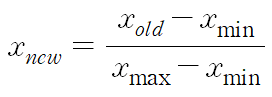
데이터를 그대로 사용하지 않고, 가공해서 모델을 학습시키는데 좀 더 좋은 형식으로 만들어주는 것머신러닝 모델에 사용할 입력 변수들의 크기를 조정하여 일정 범위 내에 떨어지도록 바꾸는 것경사 하강법을 사용하는 모든 알고리즘의 속도를 더 빠르게 할 수 있다.min-max-
9.정규화(Regularization)
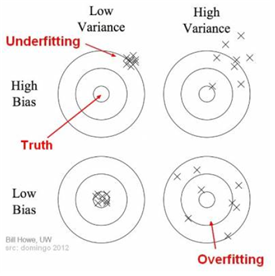
Bias : 지나치게 단순한 모델로 인한 error분산(Variance) : 데이터 셋 별로 모델이 얼마나 일관된 성능을 보여주는가 편향이 높은 모델은 너무 간단해서 주어진 데이터의 관계를 잘 학습하지 못한다.편향이 낮은 모델은 주어진 데이터의 관계를 잘 학습한다.ov
10.모델 평가와 하이퍼파라미터 고르기
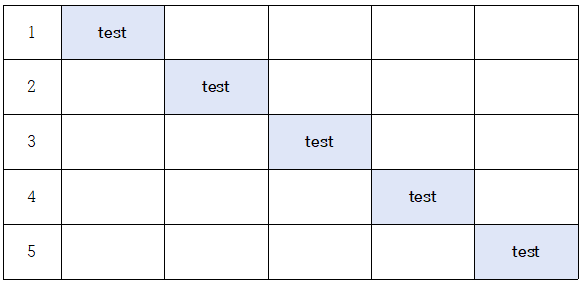
모델의 성능을 더 정확하게 평가할 수 있는 방법 중 하나모델이 운좋게 딱 test set에서만 성능이 좋거나 안좋게 나올 수 있어서 k겹 교차 검증을 사용한다.전체 데이터를 k개의 같은 사이즈로 나눈 뒤, 1개의 데이터셋을 test set으로, 나머지를 training
11.결정 트리와 앙상블 기법
결정 트리
12.랜덤 포레스트
하나의 모델을 쓰는 대신, 수많은 모델들을 만들고 이 모델들의 예측을 합쳐서 종합적인 예측을 하는 기법The Elements of Statistical Learning :"결정 트리는 이상적인 머신 러닝 모델이 되기 힘든 한가지 특징을 갖는다. 바로 부정확성이다" →
13.에다 부스트(Adaboost)
앙상블 기법 중 하나일부러 성능이 안 좋은 모델들을 사용한다.더 먼저 만든 모델들의 성능이, 뒤에 있는 모델이 사용할 데이터 셋을 바꾼다.모델들의 예측을 종합할 때, 성능이 좋은 모델의 예측을 더 반영한다.→ 성능이 안 좋은 약한 학습자들을 합쳐 성능을 극대화한다.ro