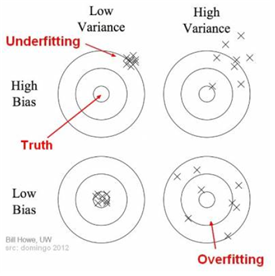
편향(Bias)과 분산(Variance)
-
편향(Bias) : 지나치게 단순한 모델로 인한 error
-
분산(Variance) : 데이터 셋 별로 모델이 얼마나 일관된 성능을 보여주는가
-
편향이 높은 모델은 너무 간단해서 주어진 데이터의 관계를 잘 학습하지 못한다.
-
편향이 낮은 모델은 주어진 데이터의 관계를 잘 학습한다.
Bias-Variance Trade-off
- overfitting(과대적합) : train data에 너무 잘 맞춰져서 실제로 사용할 때(일반화) 문제가 생길 가능성이 높다.
- train set에서는 점수가 매우 좋았는데, test set에서는 점수가 매우 안 좋아지는 경우
- underfitting(과소적합) : train set, test set의 점수가 모두 낮거나 train set보다 test set의 점수가 높은 경우
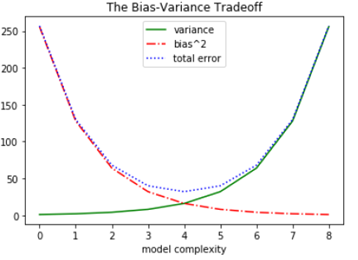
- overfitting, underfitting은 Bias(편향)과 Variance(분산)의 trade-off로 볼 수 있다.
- 과소적합과 과대적합의 적당항 밸런스를 찾아내야한다.
정규화(Regularization)
-
모델의 과대적합을 방지해주는 방법 중 하나
-
가설 함수의 세타값들이 너무 커지는 것을 방지하여 과대적합을 예방하는 방법
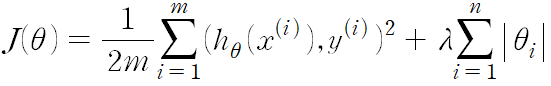
-
새로운 기준 : training data에 대한 오차도 작고, 세타 값들도 작아야지 좋은 가설 함수다
왜 세타0은 들어가지 않는가?
- 과적합과 상관이 없는 항이기 때문
-
람다 → 세타의 값에 대한 패널티
L1, L2 정규화
1. L1 정규화 - Lasso Regression, Lasso 모델
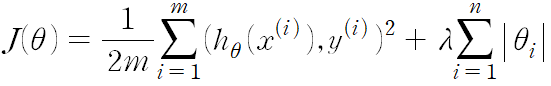
- 모델에 중요하지 않다고 생각되는 속성을 아예 없앤다. 즉, 여러 세타의 값들을 0으로 만든다.
- feature의 수가 많아서 개수를 줄이고 싶을 때 사용된다.
2. L2 정규화 - Ridge Regression, Ridge 모델
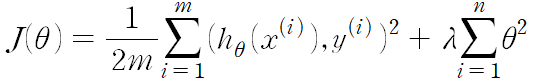
- 세타 값들을 0으로 만들기보다는 조금씩 줄여준다.
- feature를 굳이 줄일 필요가 없을 때 사용한다.
본 포스트는 코드잇 강의를 공부하며 정리한 내용입니다! 자세한 설명은 "코드잇 머신러닝 강의를 참고해주세요!

안녕하세요 :) Data/AI 공부 중인 한국외대 컴퓨터공학부 조권휘입니다.