[미니 프로젝트] DL 3. 네트워크를 이용하여 3epoch 학습 Loss Graph 확인 및 결과 확인하기 (1) 모델 확인하기
[미니 프로젝트] Deep Learning
미니 프로젝트 3장
1. 내용
1) 진행내용
각 framework에서 기본으로 제공하는 모델을 사용하되, 마지막 레이어를 수정하는 방식으로 네트워크를 설계 해야한다.
이 때, 각 모델의 pretrained모델을 사용하여, 학습하였을 때와 아닌 경우를 비교하고, 각 모델에서 최초로 제안한 내용에 대해 비교하고, 기술, Model seed 고정의 전후를 비교하는 과정까지 진행하고자 한다.2) 기본 틀
모든 네트워크는 동일하게, tensorflow와 pytorch 두가지 툴을 통해서 진행, model seed 고정의 경우에는 keras에서 현재 발생한 문제를 해결하지 못해 일부 네트워크에 한해, model seed 고정 작업을 수행.
keras에서는 keras.applications에 있는 VGG16, ResNet50, EfficientNetB0, DenseNet121, NasNetMobile와 vit_keras의 VITB16 Network를 사용하였습니다.
Pytorch에서는 timm 라이브러리에 있는 네트워크들로 해당 네트워크들을 구성하여 사용하였습니다.
keras에서는 시드 고정을 할 때,# keras seed 고정 os.environ['PYTHONHASHSEED']='1' os.environ['TF_DETERMINISTIC_OPS']='1' np.random.seed(5148) random.seed(5148) tf.random.set_seed(5148)해당 코드를 이용하여, 프로그램 내부의 시드를 고정하려 하였으나, 이후 NasNet과 EfficientNet에서 DepthwiseConvolutionLayer에서 문제가 발생하여, model seed 고정 과정을 생략하였습니다.
Pytorch에서는#pytorch 시드 고정 def seed_everything(seed): torch.manual_seed(seed) #torch를 거치는 모든 난수들의 생성순서를 고정한다 torch.cuda.manual_seed(seed) #cuda를 사용하는 메소드들의 난수시드는 따로 고정해줘야한다 torch.cuda.manual_seed_all(seed) # if use multi-GPU torch.backends.cudnn.deterministic = True #딥러닝에 특화된 CuDNN의 난수시드도 고정 torch.backends.cudnn.benchmark = False np.random.seed(seed) #numpy를 사용할 경우 고정 random.seed(seed) #파이썬 자체 모듈 random 모듈의 시드 고정 seed_everything(5148)해당 코드는 정상적으로 모든 seed가 고정이 되었으며, 불가피하게 기존의 tensorflow대신 pytorch의 비중을 늘려 학습을 진행하였습니다.
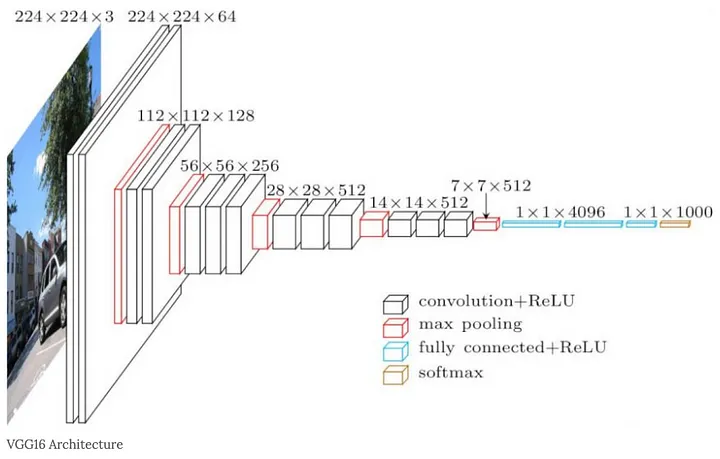
2. VGGNet - VGG 16(D)
1) VGG-16
3 3 Convolution 만으로 구성한 최초의 아키텍처로서 마지막의 레이어에만 Softmax활성화를 사용하고, 그 밖의 레이어는 모두 Lelu로 활성화 된다. 해당 구조는 다음과 같다.
위의 그림과 같이, convolution layer와 maxpooling layer를 통해서 지나는 간단한 구조를 가지고 있다.
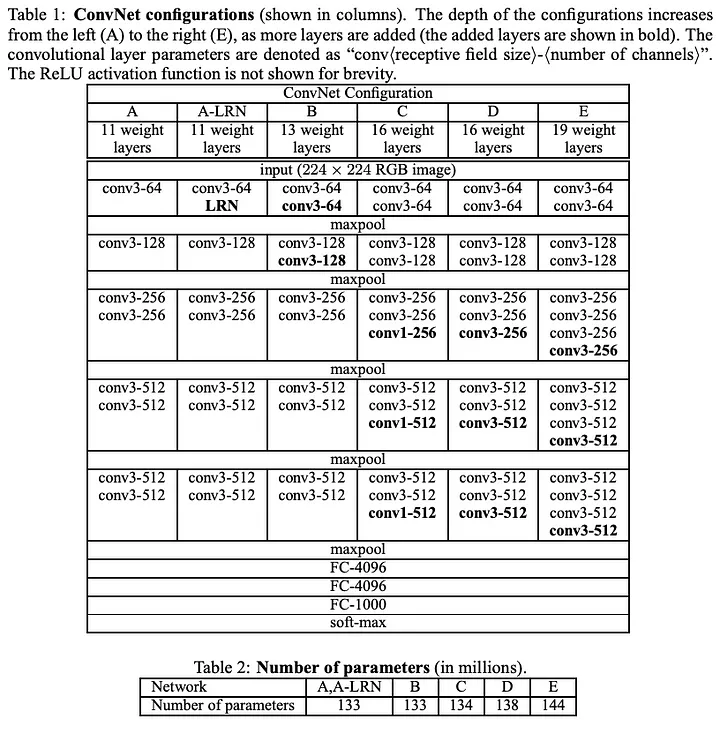
구조를 표로 나타내면 아래와 같이 나타난다.
해당 모델은 16 weight layer 중 D 모델로서, 깊이 면에서 알렉스 넷(AlexNet)보다 발전하여, 컴볼루션 레이어는 5개가 아니라 13개를 나타내고 있고, 컨볼루션만 사용함에도 불구하고, 정확도를 잃지 않았다고하는 데, Fully Convolution layer를 3개를 사용하면서, 가중치가 기하 급수적으로 증가하게 되는데, 이는입력과 출력을 곱한 만큼의 가중치를 가지므로 그 수가 매우 많은 편에 속한다.
2) 모델 정보
장점
- Convolution Layer와 maxpooling layer만을 쌓아 만들기 때문에 모델의 구성이 간단함.
- 모델이 정확도를 잃지 않고, 좀 더 깊은레이어를 통해, 세부적인 디테일을 감지할 수 있게 해줌.
- 모델의 평균내는 과정을 진행하지 않아, 채널에 있는 위치정보를 잃어버리지 않음. 이 때문에, 이미지에서 객체를 검출하거나 그 수를 셀때에는객체의 이미지상 위치가 중요하므로 좋은 네트워크로 작동할 수 있음
단점
- 모델의 Global Average Pooling 등 평균을 내는 과정을 진행하지 않아 파라미터 개수는 134,281,029개로 매우 많고, 따라서 모델의 용량이 크다.
- 모델에 학습시간이 다소 긴편에 속하고 (이후 상술할 CNN네트워크에 비해) 해당 네트워크는 출시한 지 오래 지났기 때문에, 다소 정확도가 부정확한 경향이 있음.
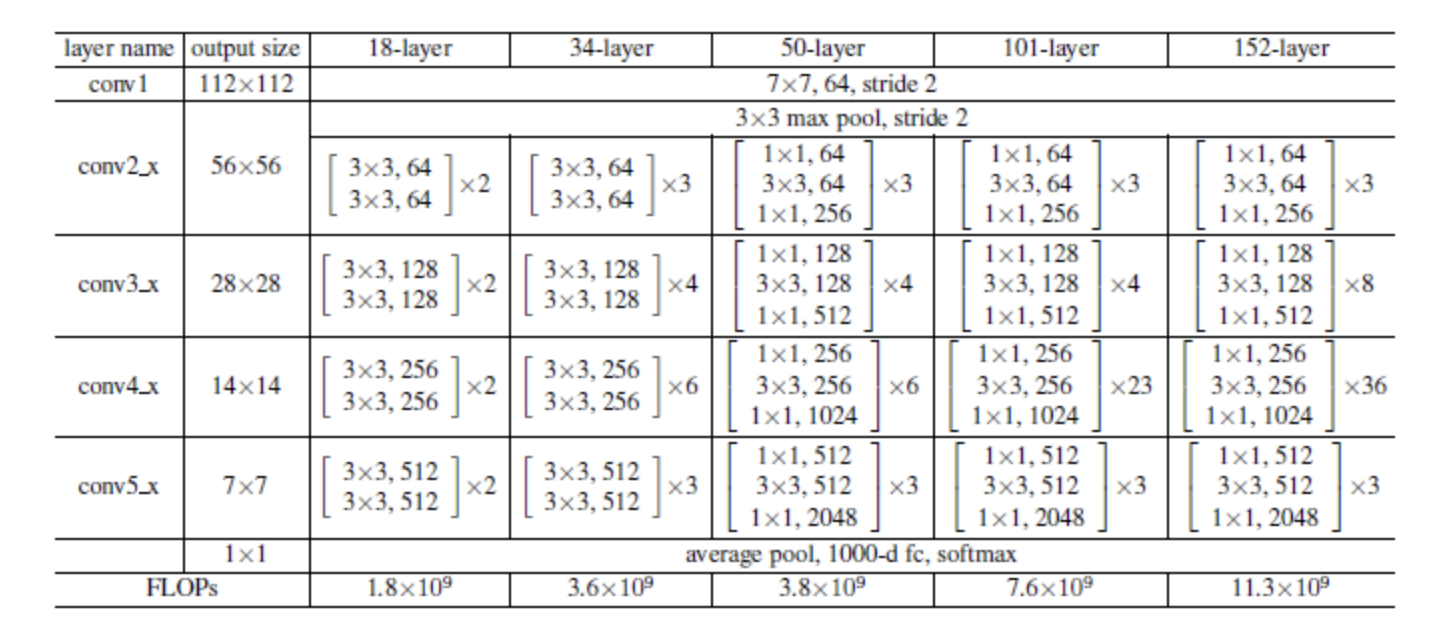
3. ResNet - ResNet 50Layer
1) ResNet 50Layer
기본적인 컨볼루션 신경망을 만들 때 컨볼루션 레이어와 풀링 레이어로도 충분하였지만, 연구자들이 예측 정확도를 높이고자 더 복잡한 빌딩 블록. 즉, 모듈(Module)을 고안했다. 해당 예시로, "인셉션 모듈(Inception modules)", "잔차 블록(residual blocks)", "역전된 잔차 병목(inverted residual bottlenecks)"등 을 조합하여, 완전한 컨볼루션 아키텍처를 만들어내었다. 또한 더 높은 수준의 빌딩 블록이 있으면 자동화된 알고리즘을 쉽게만들수 있으므로, 더 나은 아키텍처를 찾는데 도움이 되는 경우도 있다.
ResNet은 신경망을 깊게 만드는 추세를 따르되, 매우 깊은 신경망에서 공통적으로 발생하는 문제, 즉 경사가 소실하거나 폭발함에 따라 수렴이 잘 되지 않는 경향을 해결하였다. 신경망은 훈련 도중에 발생하는 오차(loss)를 관찰하고, 내부의 가중치를 조절함으로써 이를 최소화하려고 한다. 이 과정은 오차의 일계도함수(경사)에 따라 이루어 지는 데, 신경망에 레이어가 많으면 전체 레이어에 경사가 흩어지며, 신경망이 느리게 수렴하거나 아예 수렴하지 않는 문제가 있다고 시사했다.
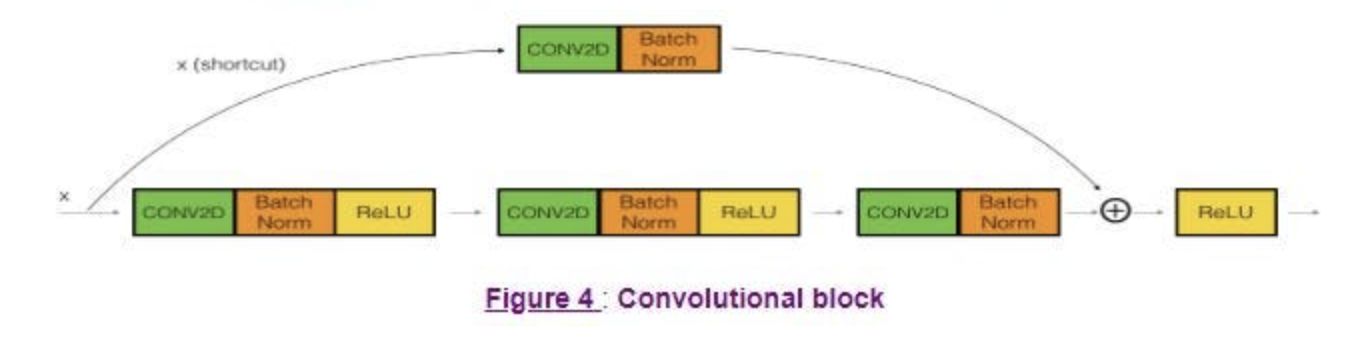
ResNet은 해당 문제를 Convolution Layer사이에 스킵연결(skip connection)을 추가함으로써 해결하려고 했다. 스킵연결은 신호를 있는 그대로 전달한 다음, 하나 이상의 컨볼루션 레이어에 의해 변환된 데이터와 재조합한다.
해당 그림에서 볼 수 있듯이, 블록의 출력은 Mainpath와 shortcut x의 출력의 합이다. 이 컨볼루션 mainpath의 출력을 , 블록 전체의 출력을 라고 할 때, 컨볼루션 경로는 원하는 출력과 입력의 차이 를 게산하도록 훈련된다. 이러한 "잔차(residual)"를 학습시키는 쪽이 더 쉽다고 주장한다.
또한 모든 컨볼루션 레이어는 배치 정규화와 Relu활성화를 사용한다. 이러한 아키텍처를 가진 네트워크는 매우 깊에 확장될 수 있다. 이름에서 알 수 있듯이, ResNet은 50, 100 또는 그 이상의 레이어가 일반적인데, 주어진 출력 오차에 대해서 어느 게층의 가중치를 조정해야하는 지를 여전히 파악할 수 있다.
2) 모델 정보
장점
- 모델의 잔차 연결이 실제로 네트워크를 얕게 만든다는 이야기가 있다.
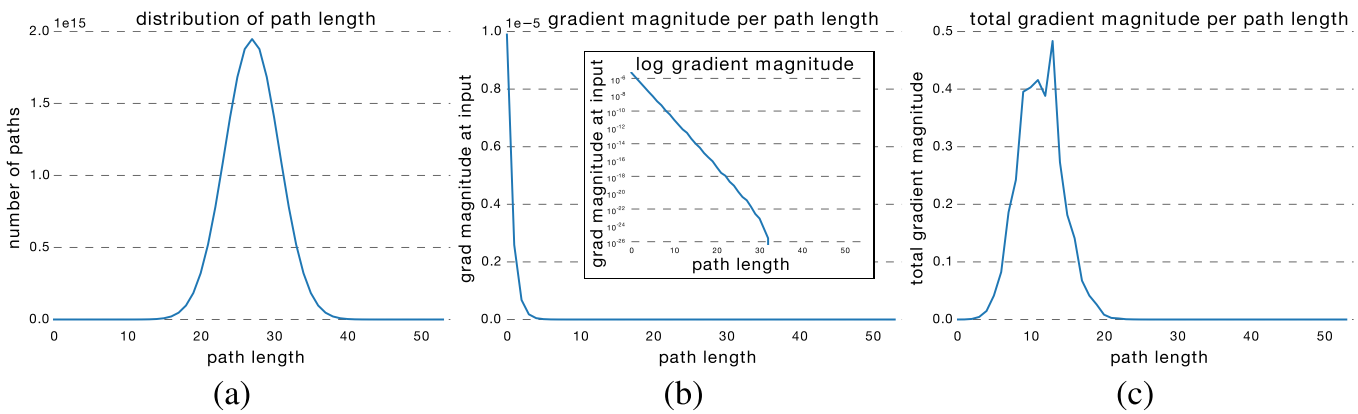
경사 최적화 단계에서, 경사는 크기가 감소할 수 있는 컨볼루션 레이어와, 변경되지 않은 상태로 유지되는 스킵연결을 통해 흐른다. <Residual Networks Behave Like Ensembles of Relatively Shallow Networks>라는 논문에서, ResNet 아키텍처의 경사 강도를 측정하였는데,
해당 결과를 도출하였다. 50 layer의 resnet 신경망에서 신호가 컨볼루션 레이어와 스킵 연결의 다양한 조합을 통해 어떻게 흐르는지 보여주는 데, 순회한 컨볼루션 레이어 수를 측정해서 나온 가장 가능성 높은 경로의 길이는 0에서 50사이로 예측하였으나, 훈련된 resnet은오히려 실제 유용한 0이아닌 경사를 제공하는경로는 12개 레이어를 가로지르는 경로보다 훨씬 짧다는 것을 밝혀내고, 이를 통해서 resnet은 분류 강점을 풀링하지만 실제로는 그다지 깊지 않기 때문에 여전히 효율적으로 수렴한다는 장점을 갖고 있다.
- 앞서 설명한 방법을 통해 학습을 진행하기 때문에, Optimal layer의 층수를 모르더라도, 적절한 layer층 수 이후의 weight를 0으로 만들어 학습이 진행되기 때문에, 구조적으로 Optimal layer보다 깊게 만들더라도 자동적으로 정확도는 유지된다.
- 모델의 설계 과정이 Convolution -> BatchNormalization -> Activation을 한묶음으로, 설계가 단순하고, VGGNetwork에 비해 Parameter의 수는 23,597,957개로 작아져 모델의 용량이 다소 작다.
단점
- VGGNetwork보다 깊으면서, Parameter의 수가 작은 부분은 사실이나, EfficientNet, DenseNet 등과 같은 네트워크에 비해서는 파라미터의 수가 많아 모델의 용량이 큰 편
- Global Average Pooling Layer를사용하기 때문에, 채널에 있는 위치 정보가 평균을 내는 과정에서 대부분 제거된다. 따라서, 객체를 검출하거나, 그 수를 셀 때 검출된 객체의 이미지상의 위치가 중요하므로 전역 평균 풀링은 부적당한 경향이 있다.
4. EfficientNet - EfficientNetB0
1) EfficientNetB0
MobileNet V2를 만들었던 팀은나중에 자동화된 신경 아키텍처 검색을 통해 아키텍처를 개선했는데, 역전된 잔차 병목을 검색 공간의 빌딩 블록으로 삼았다. 초기 연구결과가 MNasNet 논문에 요약이 되어있다. 해당 연구에서 가장 흥미로운 결과는 자동화된 알고리즘이 컨볼루션을 다시 도입했다는 것으로, 수동으로 구성된 모든 아키텍처가 의 컨볼루션으로 표준화 되어있었기 때문에, 필터 분해 가설에 따른 선택이 정당화 됐다는 점이 흥미롭다고 전해진다.
EfficientNet을 보면 MNasNet과 동일한 검색 공간 및 네트워크 아키텍처 검색알고리즘을 사용해 개발됐지만, 최적화 목표는 모바일 추론 레이턴시보다는 예측 정확도에 중점을 두었다. MobileNet V2의 역전된 잔차 병목이 다시 기본 빌딩 블록으로 바뀌었다는 특징을 가진다.
EfficientNet은 여러 신경망으로 이루어진 군(family)로, 그에 속하는 네트워크의 규모를 키우는 데 신경을 많이 썼다. 컨볼루션 아키텍처를 확장하는 방법은 다음 세가지이다.
- 레이어의 추가
- 레이어별 채널의 추가
- 입력 이미지의 해상도를 높임
위의 세가지 방법이 서로 영향을 준다는 점을 지적하며, "입력 이미지 크기가 커지면 네트워크의receptivef field를 키우기 위해 레이어가 더 많이 필요하고, 더 큰 이미지에서 더 미세한 패턴을 포착하기 위해 채널도 더 많이 필요하다."
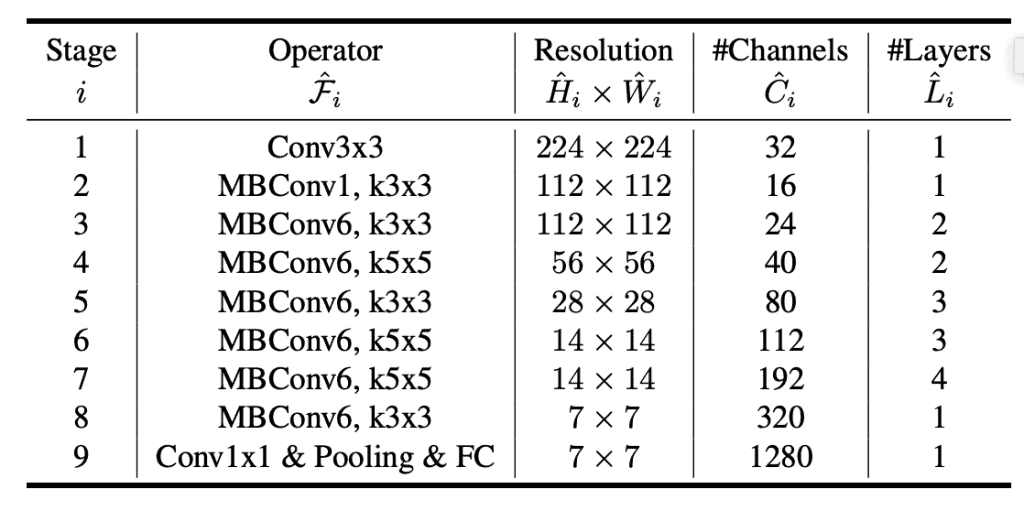
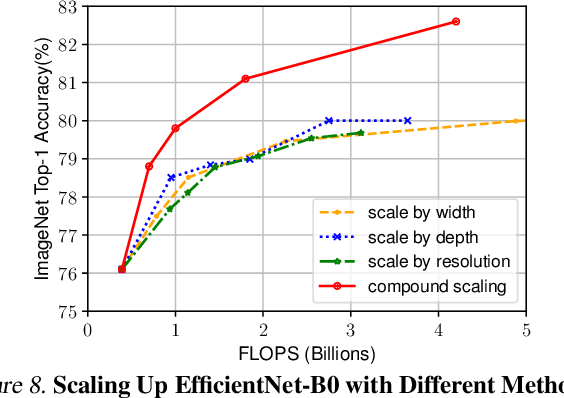
EfficientNetB0~B7 신경망군은 이전의 ResNet의 아키텍처처럼 하나의 축을 따라 확장하는 것이 아닌 세개의축을 모두에 따라 확장한다는 점에서 참신한 요소가 되었다. 해당 방식은 모든 가중치 수에 대해 최적의 성능 수준을 제공하고 있다.
아래는 베이스 라인의 EfficientNetB0 아키텍처를 나타낸다.
2) 모델 정보
장점
- 모델의 파라미터 개수가 4,055,976개로 매우 작은 편에 속하므로, 모바일에서 사용할 수 있을 정도로 모델의 용량이 작음
- compound scaling은 레이어, 채널 또는 이미지 해상도만으로 네트워크를 스케일링하는 것보다 효율적이라는 결론을 낸다.
- 과적합을 피하기 위해 드롭아웃을 사용하는 데, efficientnet에서는 탈락률을 네트워크의 크기에 따라 다르게 잡음으로 최대한 효율적인 방식을 사용
- Transfer Learning을 진행하였을 때 특정 데이터셋에서는 SOTA를 달성하지는 못하였지만, 대부분 근소한 차이를 보이며 연산량대비 정확도측면에서 매우 효율적인 모습을 보여줍니다.
단점
- EfficientNet은 Compound Scaling과 같은 여러 기법을 사용하므로 앞서 서술된 모델들에 비해 다소 구조가 복잡하고 이해하기 어려울 가능성이 있음
- EfficientNet은 대규모 데이터셋에서 훈련되어 일반적인 특징을 학습하지만, 작은 데이터셋은 과적합의 위험이 존재할 수 있음.
- EfficientNet은 학습 파라미터가 작지만 그에 비해 연산이 다소 시간이 걸리는 측면이 있음. 따라서 충분한 학습시간이 필요함. (그래도 위의 모델들에 비해서는 시간이 짧게 걸리기 때문에 큰 문제로 생각되진 않음)
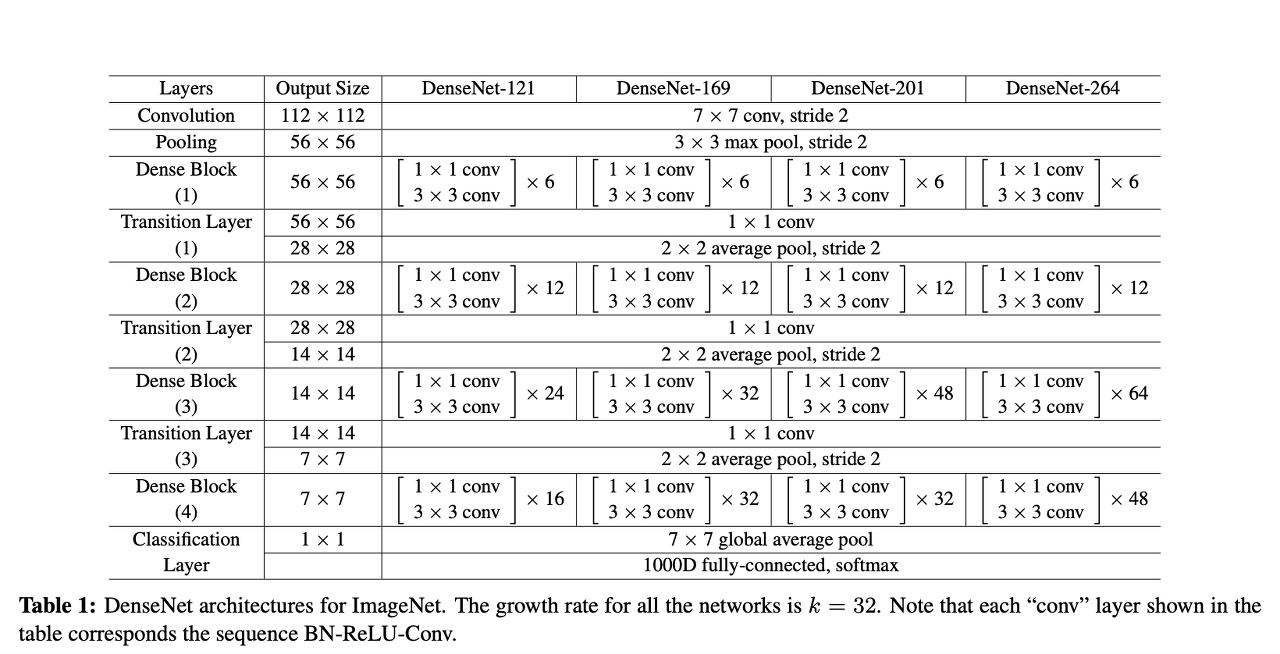
5. DenseNet - DenseNet 121
1) DenseNet 121
DenseNet 아키텍처는ResNet의 스킵연결 개념을 급진적으로 재해석합니다. DenseNet은 필요한 만큼 스킵연결을 만들면서 이전 레이어의 모든 출력을 컨볼루션 레이어에 먹일(feed)것을 제안했습니다.
이 때, 데이터는 resnet에서처럼 추가되는 것이 아니라 깊이 축(채널)을 따라 이어붙이기(concatenation)에 의해 결합합니다.
밀집 블록(Dense block)은 DenseNet의 기본 빌딩 블록으로, 밀집 블록에서 컨볼루션은쌍으로 그룹화되며 각 컨볼루션 쌍은 이전의 모든 컨볼루션 쌍의 출력을 입력으로 수신합니다. 이 때 밀집블록의 데이터는 채널별로 이어 붙여 결합되는데, 모든 컨볼루션은 Relu로 활성화되고 배치 정규화를 사용합니다. 채널별 이어 붙이기는 데이터의 높이와 너비 차원이 같은 때만 작동하므로 밀집블록의 컨볼루션은 모두 보폭이 1이며, 이러한 차원을 변경하지 않는 특징을 가지고 있습니다.
이전에 본 모든 출력을 이어 붙이면 채널 및 파라미터 수가 폭발적으로 증가할 것으로 예상하지만 실제로는 그렇지 않다. DenseNet은 학습 가능 파라미터의면에서 경제적인 특징을 띄는 데, 이 이유는 상대적으로 많은수의 채널을 가질 수 있는 모든 이어 붙여진 블록이 이를 적은수의 채널 K로 줄이는 컨볼루션을 통해 항상 먼저 공급되기 때문이다로 서술합니다.해당 과정때문에 채널 수는 밀집 블록의 컨볼루션 단계 수에 따라 선형적으로만 증가합니다.
2) 모델 정보
장점
- 각 레이어가 이전 모든 레이어와 연결되기 때문에, 모델 파라미터가 효과적으로 공유되어, 파라미터의 수가 7,042,629개로 layer 깊이에 비해 작은 편
- DenseNet은 각 컨볼루션 레이어가 이전에 계산된 모든 특징을 보기 때문에 얕은 컨볼루션을 사용할 수 있고, 특징의 재사용률을 높여 gradient 흐름을 강화하고 학습을 안정화 시킴
- 각 레이어에서 gradient가 직접적으로 전달되기 때문에, Gradient Vanishing 문제가 감소함.
단점
- 각 레이어에서 이전 레이어의 출력을 모두 연결하기 때문에, 메모리의 사용량이 증대됨. 특히 큰 모델이나, 큰 입력이미지의 경우에는 이가 더욱 부각되는 면이 있음.
- 높은 연결성으로 인해서 계산비용이 다소 증가하는 모습이 있음. 이는 추론 시간을 늘릴 수도 있음.
6. NasNet - MNasnet(mobile nasnet)
1) NasNet
최적의 연산 조합 검색을 자동화하는 것을 사용하는데, 가능한 연산 세트의 모든 경우의수를 무차별 대입(burute-force)하는 검색은 레이어를 조합하여 완전한 신경망을 만드는 방법이 너무 많은데다가, 각 조각에는 출력 채널의 수 또는 필터 크기 등의 하이퍼 파라미터가 많이 있기 때문에 사용하기 어렵다.
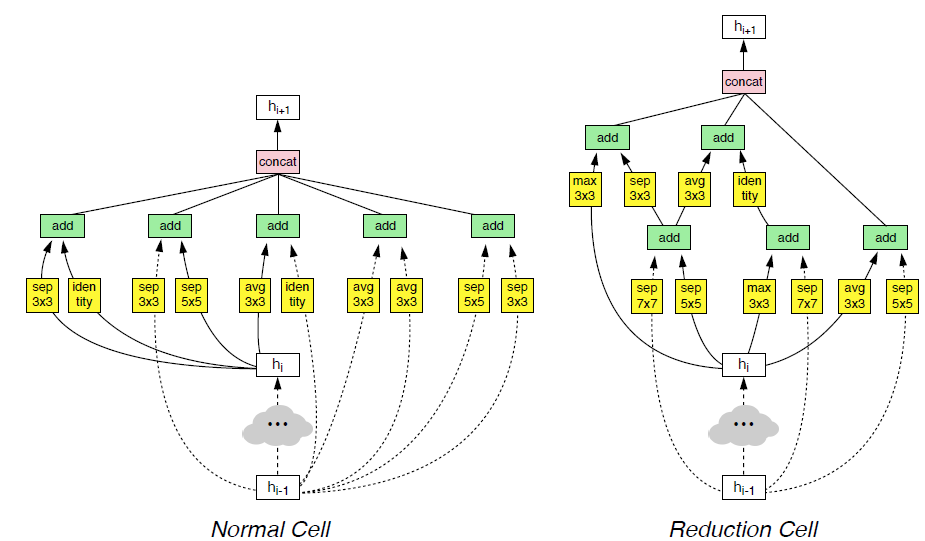
NASNet(Neural Architecture Search)는 두 가지 유형의 반복 모듈로 구성되어있다. 하나는 특징의 너비와 높이를 그대로 유지하는 "일반 셀(Normal Cell)", 다른 하나는 이를 반으로 나누는 "축소 셀(reduction cell)"이다. NASNet에서는 자동화된 알고리즘으로 기본 셀들(maxpooling,avgpooling,conv,concat,identity 등)의 구조를 설계하고, 적절한 파라미터로 셀을 쌓아서 컨볼루션 아키텍처를 수작업으로 조립한 뒤, 결과 네트워크를 훈련해어떤 모듈 설게가 가장 효과적인지 확인했다.
검색 알고리즘은무작위로 검색이 될 수도 있고, (신경망을 기반으로 하는 정교한 알고리즘)강화학습(reinforcement learning)이 될 수 있다.
해당 그림은 알고리즘이 발견한 가장 뒤어난 일반 셀과 축소 셀의 구조이다. 검색 공간은 직전 단계뿐만 아니라 그 전단게에서도 연결할 수 있어, DenseNet과 같이 더욱 조밀하게 연결된 아키텍처를 흉내낸다.
2) MNasNet
모바일에서도 사용할 수 있는 구조를 자동으로 찾는 네트워크, 최근에 나오는 CNN 모델들은 더 깊어지고 크기가 커지고 있고, Computational Cost증가, 속도 감소 등 제한된 자원의 Platform에서 사용하기 어렵기 때문에 효율적인 모델을 찾기 위해서 자동화된 Neural Architecture Search 접근법을 제시하였다.
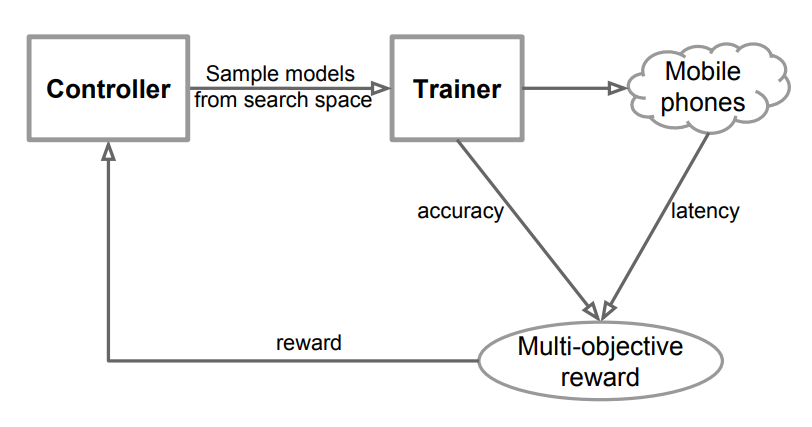
Accuracy와 Latency의 적절한 타협점을 갖는 모델을 찾는 Mobile NasNet을 제시하였고, Accuracy와 Latency 모두 목표로 한다고 해서, Multi-Objective Neural Architecture Search Approach라고 한다.Factorized Hierarchical Search Space
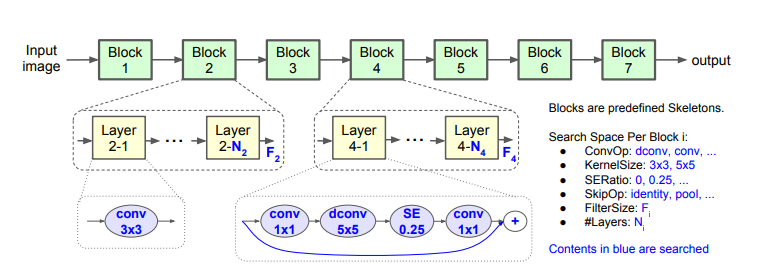
몇 개의 cell을 반복적으로 쌓는 구조는 다양성의 한게와 높은 Latency를 보이기 때문에, CNN모델을 Unique Block으로 제작하고, Operation과 Connection을 각각 찾아다른 Block에서 다른 Architecture를 가질 수 있도록 함. 이를 통해서 다양성을 증가 시키고, 다양성 증가를 통해 Computational Cost 감소 및 성능의 향상을 이룸.
Search Space Baseline 구조는 다음과 같음
CNN 모델을 미리 정의된 각각의 Block은 정해진 Layer 목록들을 가지며, Block별로 Operation과 Connection들이 결정이 되는 데, 모든 가능성을 열어놓고, Sub Space를 지정하는 것이 아닌, 논문 작성자의 노하우를 바탕으로 Sub Space 영역을 한정한다.Search Algorithm
위와 같은 구조로 Sample eval update Loop를 통해 학습을 진행한다.
Reinforcement Learning 강화학습을 통해 Multi-object Search Problem을 해결하였다.3) 모델 정보
장점
- MNASNet은 신경 아키텍처 검색(Neural Architecture Search)구조로 자동으로 아키텍처를 검색함으로써 효과적인 신경망을 찾는 데 유용합니다.
- Latency와 Accuracy를 두가지 목표를 한번에 해결하기 때문에 비용대비 정확도가 높은 편이다.
- 파라미터의 개수는 4,275,001개로 모델의 경량화를 이루고, 계산 및 메모리의 효율성을 증대하여 모바일 환경에서도 효율적으로 동작할 수 있도록 최적화가 되어있습니다.
단점
- 작은 데이터 셋에서는 성능에 제한이 있으며, 하이퍼파라미터에 성능이 의존하는 경향이 있고, 주로 모바일 기기에 최적화가 되어있어 일부 환경에서는 오히려 불리한 경우를 볼 수 있음.
- 모델의 크기를 줄이면서, 정확성이 NASNet에 비해 희생될 수 있음.
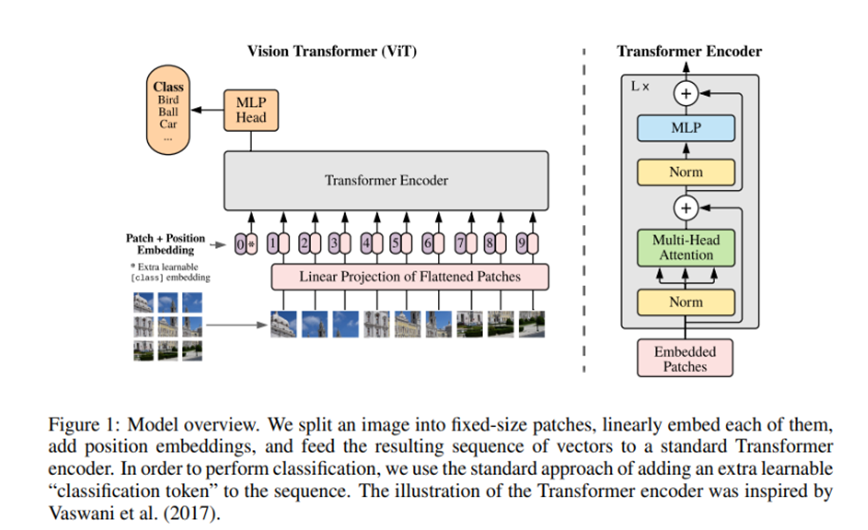
7. VIT (Vision Transformer) - VIT B16
1) VIT B16
앞서 모든 아키텍처들, 컴퓨터 비전을 위한 아키텍처들은 모두 컨볼루션 필터에 의존한다. 실제로 나이브한 조밀 신경망과 비교할 때 컨볼루션 필터는 이미지에서 정보를 추출하는 방법을 배우는 데 필요한 가중치의 수를 줄이는 데 효과적이지만, 데이터셋 크기가 계속 증가함에 따라 이러한 가중치의 감소가 더이상 필요하지 않은 경우가 있다. 따라서 자연어 처리를 위한 Tranformer 아키텍처를 제안한 비스와니는 "주의 집중(Attention)"의 개념에 집중하였다. 이는 본래에 모델에서 각 단어를 예측을 할 때, 텍스트 시퀀스 중 일부분에 집중함을 뜻하는 데, 예를 들어서, 불어 "ma chemise rouge"를 한국어 "내 빨간 셔츠"로 번역하는 모델을 생각해보면 트랜스 포머 모델은 번역문에 두번째로 올 단언인 "빨간"을 예측할 때, "rouge"라는 단어에 집중하는 법을 배운다. 이를 가능케 한 것은 위치 인코딩(positional encoding)이다. 입력 문장에 어떤 단어가 있는지 뿐만 아니라, 각 단어의 문장 내에서의 위치를 (ma,1),(chemise,2),(rouge,3)와 같이 나타낸다. 이렇게 트랜스포머 모델은 출력의 특정 단어를 예측할 때, 입력의 어느 단어에 집중해야 할지를 훈련 데이터 셋으로 학습한다.
ViT(Vision Transformer)모델은 트랜스포머의 개념을 이미지 작업에 적용한다.
문장이 단어들로 이루어 지는 것처럼, 이미지는 정사각형 조각(patch)들로 이루어지는 것을 볼 수 있다. 이렇게 입력 이미지를 여러개의 조각으로 잘게 나누고, patch의 픽셀값과 이미지 내에서의 위치(position)을 이어 붙임으로써 encoding을 진행한다. 이때 조각의 위치는 조각이 몇 번째인지를 나타내는 범주형 변수이다. 학습 가능임베딩을 사용하여, 관련 콘텐츠가 있는 조각 간의 거리가 얼마나 가까운지 관계를 포착한다.
이 후 조각 표현들은 여러개의 트랜스포머 블록을 거치는 데, 각 블록은 Attention Head로 구성된다.
훈련 루프 자체는 모든 컨볼루션 네트워크 아키텍처의 루프와 비슷하다. 또한, VIT아키텍처는 컨볼루션망 모델보다 훨씬 더 많은 데이터를 요하므로, VIT모델을 대량의 데이터로 사전훈련된 뒤에 더 작은 데이터 셋으로 파인 튜닝할 것을 권한다. 현재로서는 비교적 작은 데이터셋에 대해 특별히 유망하지는 않지만, 트랜스포머 아키텍처를 이미지에 적용하는 아이디어는 상당히 참신함에는 변함 없다.2) 모델 정보
장점
- 패치들을 한번에 취급해서 전역적인 이미지 정보를 학습하기 때문에, 전체적인 이미지정보를 파악하는 데, 매우 효과적입니다.
- Base 16모델의 경우는 16크기로, 32는 32크기로 고정된 크기의 패치로 나누어 처리하므로 입력 이이미지의 크기에 상대적으로 불변하게 작동을 하게 됩니다. 이 때문에, 입력 크기가 달라지더라도 모델이 효과적으로 작동할 수 있습니다.
- 컨볼루션 연산을 사용하지 않고, 그저 트랜스포머 레이어만을 사용하는 구조를 가지고 있기 때문에, 모델의 구조가 상대적으로 간결하게 되어있습니다.
- 모델이 기존의 CNN모델들 보다 간단하게 확장이 가능하기 때문에, 입력 이미지가 커도 패치크기만을 조절하여도 되고, 추가적인 레이어를 쌓는 것도 Base모델이 아닌 Large모델이나, Huge모델등을 사용하는 것으로 비교적 간단하게 확장이 가능합니다.
단점
- 전역적인 이미지 정보를 학습하기 때문에 오히려 단점은 지역적인 정보에 대해 상당히 불리한 경우가 있습니다. 게다가 패치의 경계선에 중요한 정보가 있는 경우 더욱 학습에 불리해지는 경향이 있습니다.
- 두번째로 이미지를 작은 패치로 나누고, 토큰으로 변환하여 처리하는 과정에서, 이미지의 크기가 크거나 패치의 수가 많아질수록 모델의 계산비용이 기존의 CNN 기반의 모델에 비해 많이 드는 단점이 있습니다. 파라미터의 개수는 85,802,501개로 VGGNet을 제외하면 가장 많은 파라미터를 보유하고 있습니다.
- CNN기반들에 비해 데이터 셋이 부족한 경우에 학습 속도가 더욱 느려질 수 있습니다. 다시 말하면 Pretrained 모델이 아닌 경우에는 데이터의 패턴을 학습하는 데 더욱 많은 epoch이 필요할 수 있습니다.