알고리즘
1.[코테] 알고리즘 투 포인터(two pointers), 이진 탐색, 슬라이딩 윈도우

파이썬에서는 일렬로 늘어서 있는 형태인 선형 배열(Linear Array)로 리스트를 주로 사용하는데, 이 리스트를 순차적으로 두 개의 지점(index)을 이용하여 해결해 나가는 방법을 투 포인터 알고리즘이라고 한다. 명확하게 같은 알고리즘은 아니지만 활용 방법이 이진
2.[코테] 알고리즘 그리디와 에라토스테네스의 체

1. 그리디(Greedy) 영문 greedy는 '탐욕스러운', '욕심 많은'이라고 번역이 되는데, 말 그대로 단순하고 탐욕적이며 근시안적으로 여러가지 해법 중 가장 좋은 방법만 선택하는 것을 그리디 알고리즘이라고 한다. 그 순간에 최적인 것만 선택하여 진행하며 그 선택
3.[코테] 알고리즘 에라토스테네스의 체

1. 에라토스테네스의 체 출처:위키백과 출처:위키백과 > 고대 그래스 수학자 에라토스테네스가 발견한 에라토스테네스의 체는 소수를 찾는 방법이다. 위의 그림을 보며 진행순서를 보자. >#### 1. 주어진 n까지의 모든 약수는 대칭을 이룬다는 것을 활용한다. 예를 통
4.[코테] 알고리즘 탐색 1 DFS(Deep_First_Search)와 순열(Permutation)
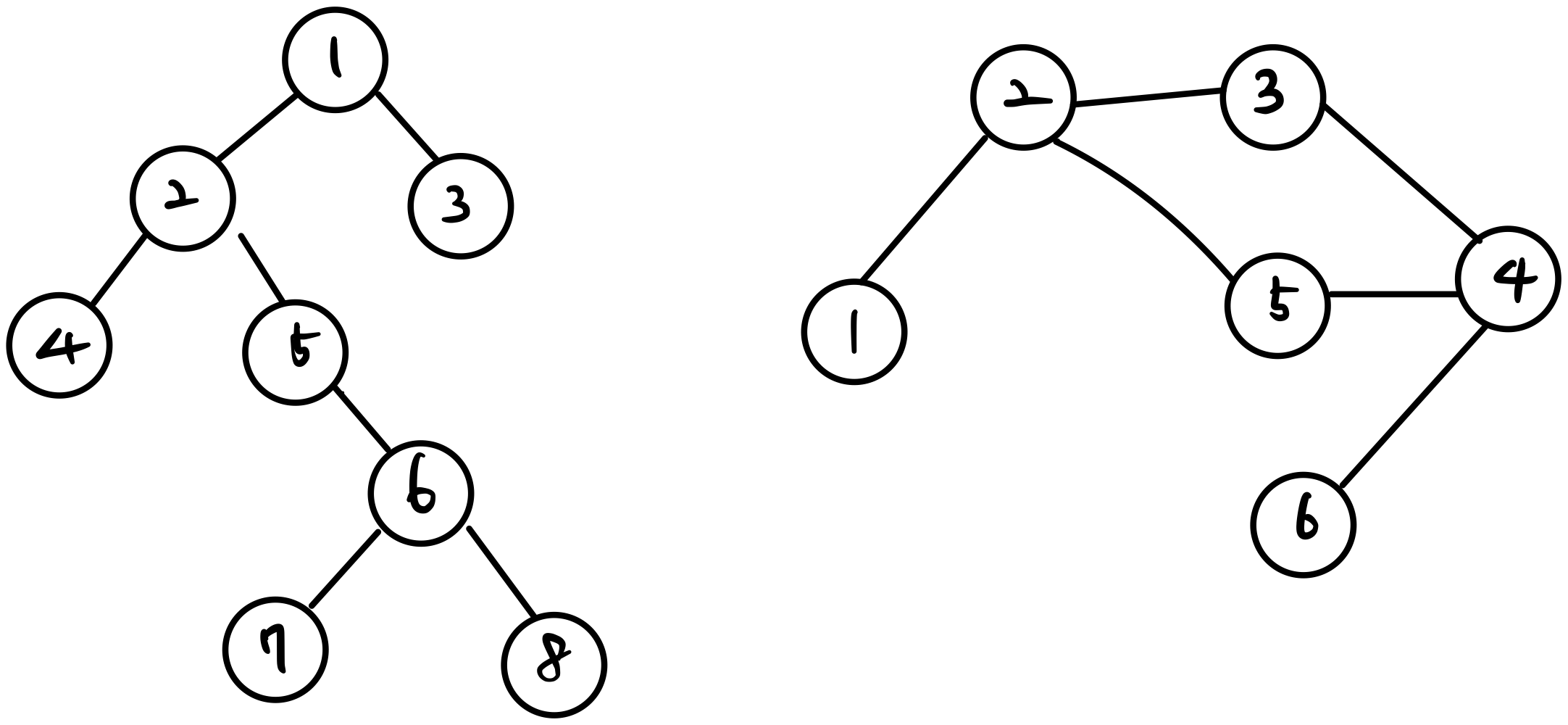
탐색은 많은 데이터들 가운데 원하는 데이터를 찾아가는 과정이다. 특히 트리 구조 및 그래프 구조의 안에서 탐색을 해야 할 경우 대표적으로 DFS와 BFS가 있는데, 우선 재귀를 이용한 DFS의 활용에 대해 먼저 살펴보겠다. DFS를 이해하기 위해 선행적으로 스택과 재귀
5.[코테] 알고리즘 탐색 2 DFS(Deep_First_Search)와 중복순열
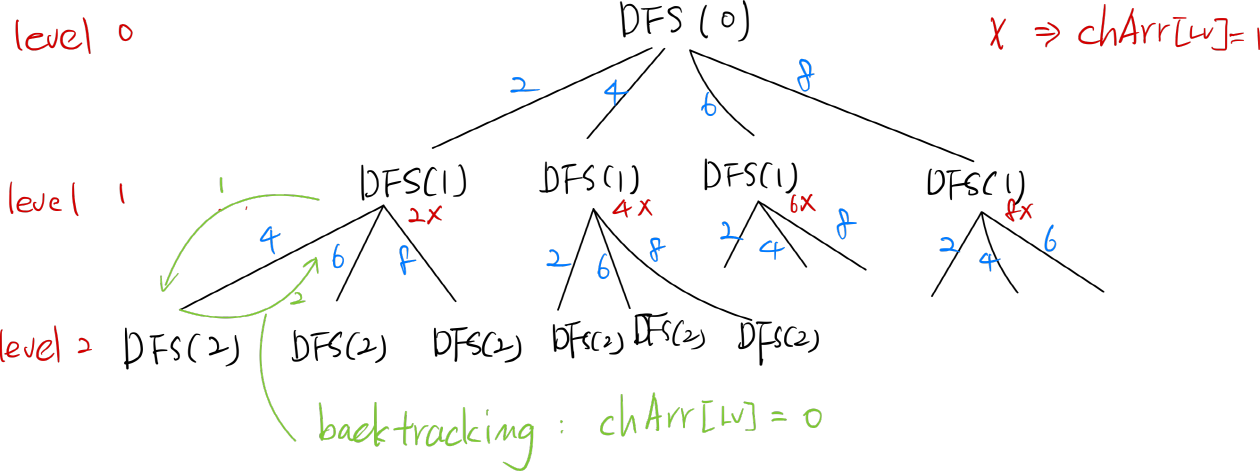
탐색은 많은 데이터들 가운데 원하는 데이터를 찾아가는 과정이다.DFS는 깊이 우선 탐색이라 불리며 그래프에서 깊은 부분을 우선적으로 탐색하여 출력하는 알고리즘이다. 마지막 노드까지 내려가면 더 이상 깊이 탐색할 것이 없기에 마지막 노드를 출력하거나 체크한 후에 부모 노
6.[코테] 알고리즘 탐색 3 DFS(Deep_First_Search)와 조합(Combination)
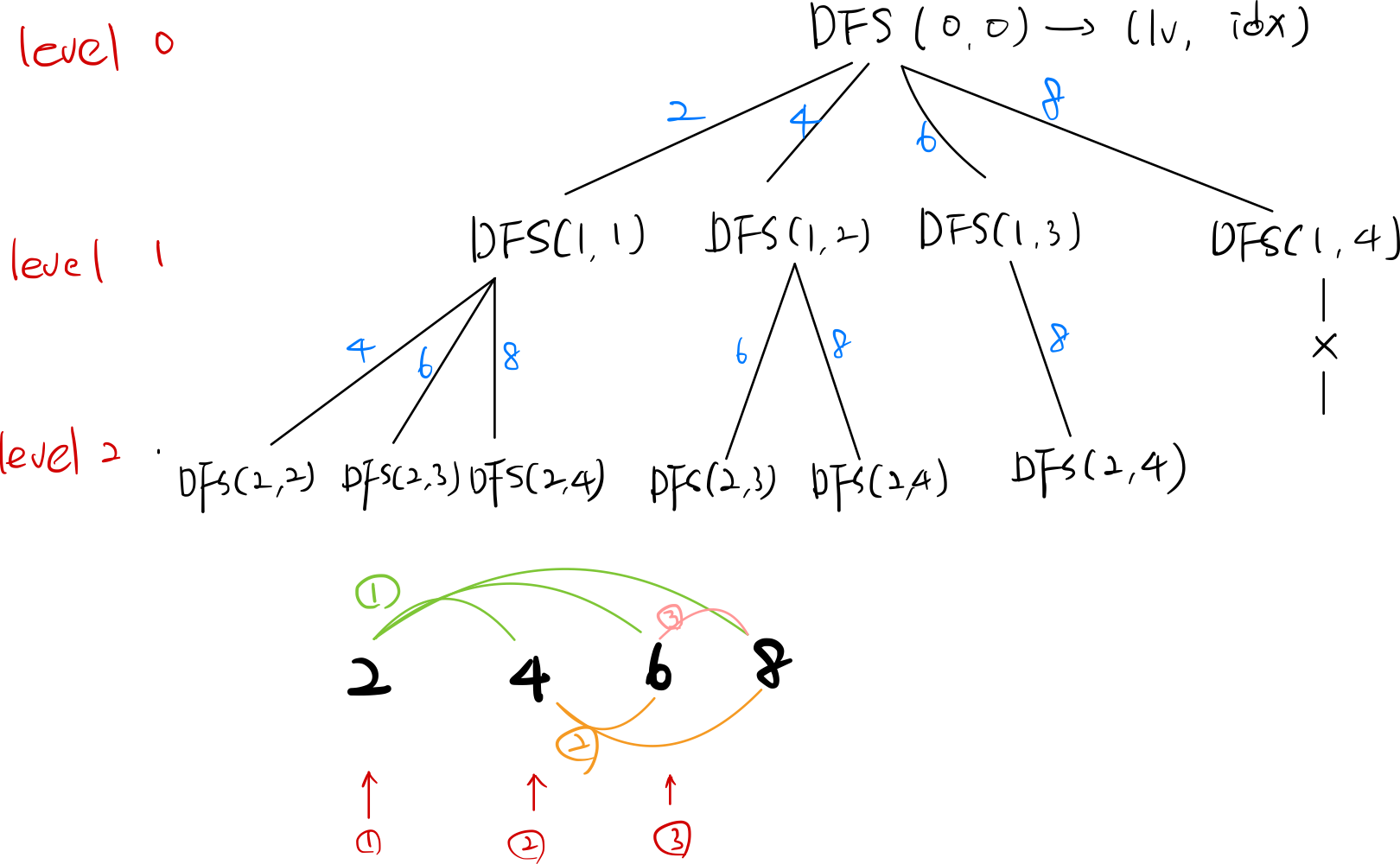
탐색은 많은 데이터들 가운데 원하는 데이터를 찾아가는 과정이다.DFS는 깊이 우선 탐색이라 불리며 그래프에서 깊은 부분을 우선적으로 탐색하여 출력하는 알고리즘이다. 마지막 노드까지 내려가면 더 이상 깊이 탐색할 것이 없기에 마지막 노드를 출력하거나 체크한 후에 부모 노
7.[코테] 알고리즘 탐색 4 DFS(Deep_First_Search)와 부분집합
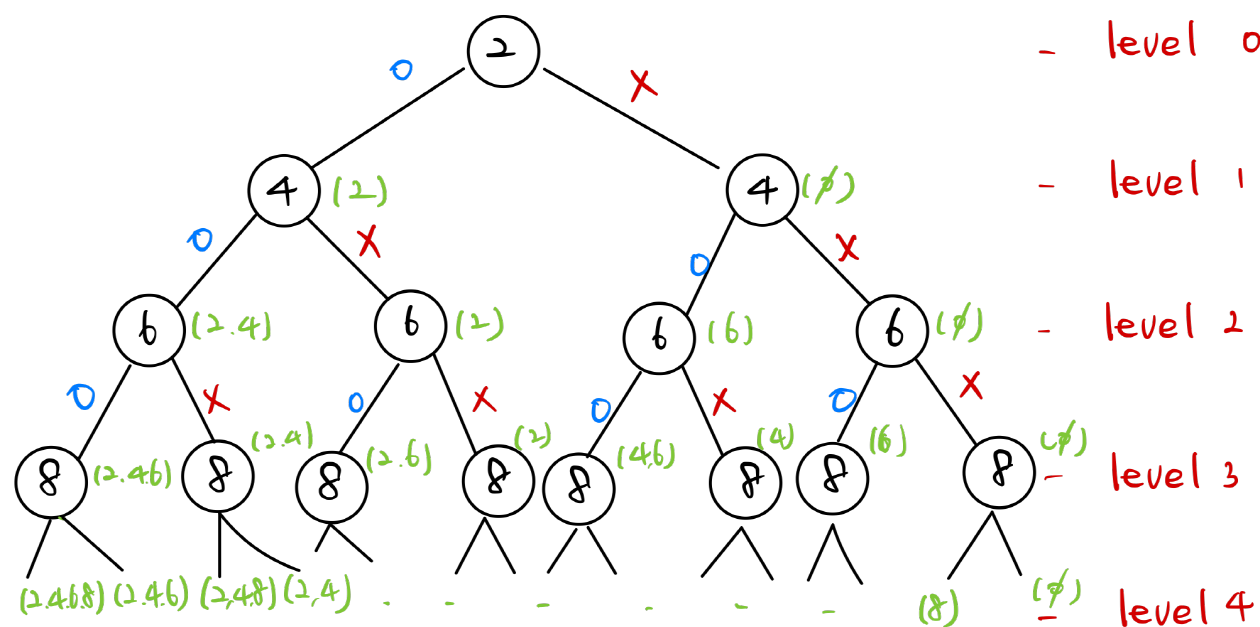
탐색은 많은 데이터들 가운데 원하는 데이터를 찾아가는 과정이다.DFS는 깊이 우선 탐색이라 불리며 그래프에서 깊은 부분을 우선적으로 탐색하여 출력하는 알고리즘이다. 마지막 노드까지 내려가면 더 이상 깊이 탐색할 것이 없기에 마지막 노드를 출력하거나 체크한 후에 부모 노
8.[코테] 알고리즘 탐색 5 BFS(Breadth_First_Search: 넓이 우선 탐색)
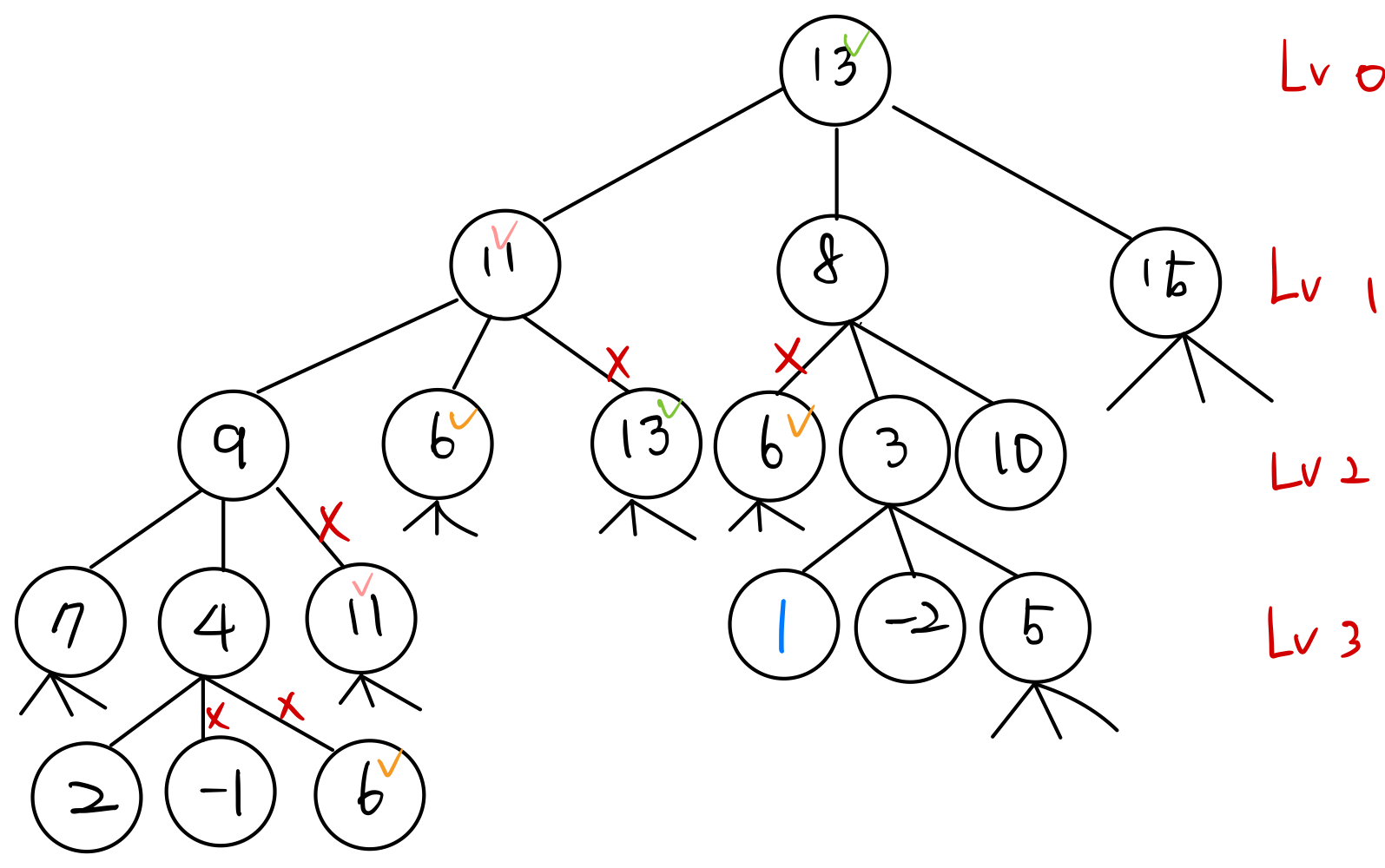
1. 탐색(Search) >탐색은 많은 데이터들 가운데 원하는 데이터를 찾아가는 과정이다. 2. BFS > BFS는 넓이 우선 탐색이라고 불리며 그래프에서 가장 가까운 곳부터 탐색하여 출력 혹은 연산하는 알고리즘이다. BFS를 구현하기 위해서 선입선출 방식인 '큐'
9.[코테] 알고리즘 탐색 5-1 BFS(Breadth_First_Search: 넓이 우선 탐색) 구현

탐색은 많은 데이터들 가운데 원하는 데이터를 찾아가는 과정이다.BFS는 넓이 우선 탐색이라고 불리며 그래프에서 가장 가까운 곳부터 탐색하여 출력 혹은 연산하는 알고리즘이다. BFS를 구현하기 위해서 선입선출 방식인 '큐' 자료구조를 사용하는 것이 일반적이다. 가장 가
10.[코테] 알고리즘 다익스트라(Dijkstra) 최단 경로 알고리즘
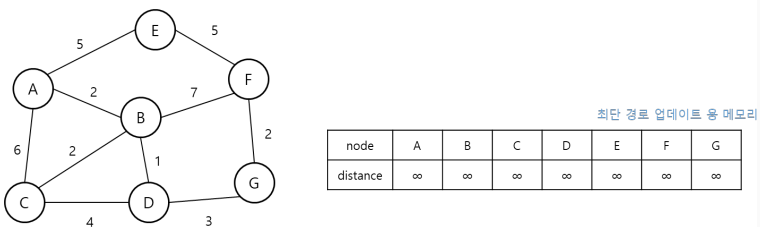
알고리즘 이름 그대로 가장 짧은 거리를 찾는 알고리즘이다. 최단 경로를 탐색해야 하는 유형의 문제는 다양하게 주어지는데, 모든 지점에서 모든 지점으로의 최단 거리 구하기나 한 특정 지점에서 모든 지점으로의 최단거리 혹은, 어느 특정 지점에서 한 특정 지점으로의 최단거리
11.[코테] 알고리즘 DP(다이나믹 프로그래밍) 플로이드 워셜(최단 경로) 알고리즘

1. 최단 경로 탐색 알고리즘 이름 그대로 가장 짧은 거리를 찾는 알고리즘이다. 최단 경로를 탐색해야 하는 유형의 문제는 다양하게 주어지는데, 모든 지점에서 모든 지점으로의 최단 거리 구하기나 한 특정 지점에서 모든 지점으로의 최단거리 혹은, 어느 특정 지점에서 한 특
12.[코테] 알고리즘 다이나믹 프로그래밍(DP:Dynamic Programming)와 피보나치 수열
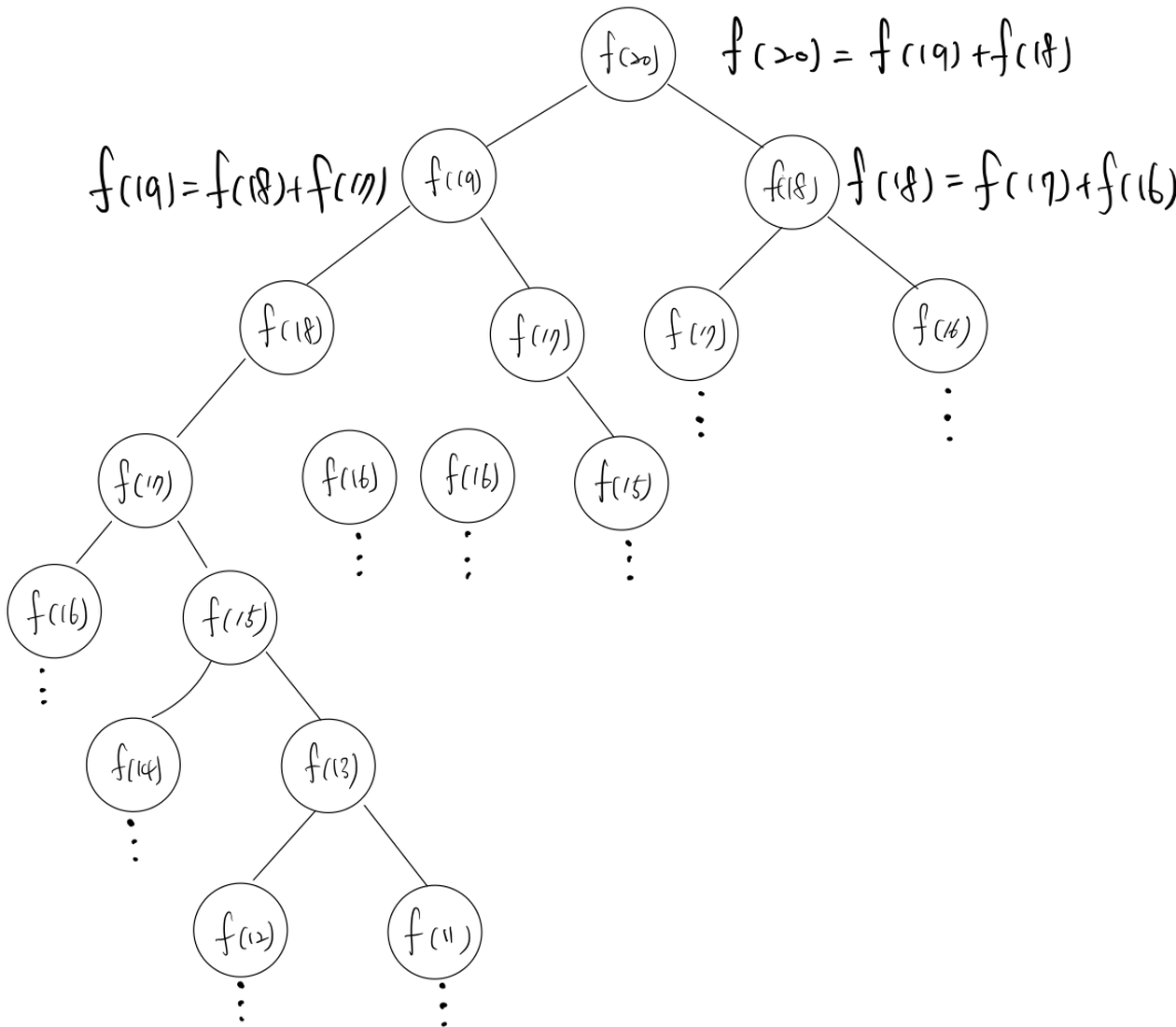
문제를 해결하기 위해 많은 시간, 혹은 많은 공간이 필요한 경우가 나타난다. 이러한 제약된 조건 속에서 문제를 효율적으로 해결하기 위해서는 그에 걸맞는 효율적인 알고리즘이 필요하다. 보통 일반적인 방법으로 문제를 해결할 경우, 매우 많은 연산 횟수 혹은 매우 큰 배열이
13.[코테] 알고리즘 DP. Knapsack(냅색) 알고리즘

배낭(Knapsack) 혹은 가방 문제는 부분집합들 중 문제에서 제시하는 조건에 가장 알맞은(최적화) 부분집합을 찾는 문제다.여기에선 그리디로 해결할 수 있는 'Fractional Knapsack Problem'처럼 짐을 쪼개는 문제가 아닌, 가방에 담을 수 있는 짐은