1. 최단 경로 탐색
알고리즘 이름 그대로 가장 짧은 거리를 찾는 알고리즘이다. 최단 경로를 탐색해야 하는 유형의 문제는 다양하게 주어지는데, 모든 지점에서 모든 지점으로의 최단 거리 구하기나 한 특정 지점에서 모든 지점으로의 최단거리 혹은, 어느 특정 지점에서 한 특정 지점으로의 최단거리 등등의 문제 유형들이 있다. 최단 경로 탐색 알고리즘은 BFS, 플로이드, 벨만-포드, 다익스트라가 대표적인데 이번에는 다익스트라에 대해서 살펴보겠다.
2. 그래프 가중치
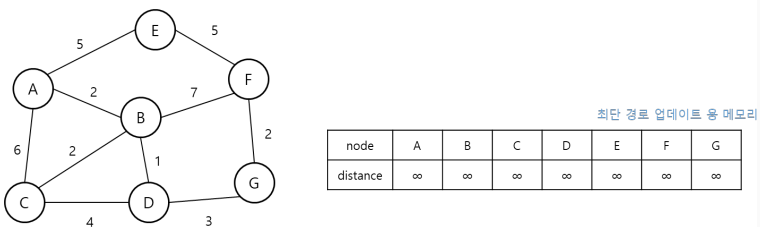
BFS 알고리즘은 넓이 우선 탐색으로 가장 가까운 거리부터 탐색하는 알고리즘인데, 다익스트라와 차이점은 바로 그래프에 가중치가 있느냐 없느냐의 차이에서 발생한다. 최단 거리 탐색 문제는 보통 그래프로 주어지는데, 아래의 그림과 같이 노드, 노드와 노드를 이어주는 간선, 그리고 한 노드에서 다른 노드로 이동하는 가중치가 주어진다면 다익스트라 알고리즘이라고 보면 된다. 그리고 가중치는 '음의 간선 가중치'가 없을 때 사용하다는 것도 특징이다. 그리고 아래의 그림은 방향성이 없는 '양방향' 그래프이며, 어느 노드에서 다른 노드로만 뻗어나가는 방향성으로 가리키는 '방향성' 그래프도 있다.
보통 노드와 간선만 주어지고 최단 거리나 최소 횟수 등의 문제가 주어진다면 BFS 알고리즘으로 해결하는 것이 보통이다.
3. 동작 원리
다익스트라는 우선 순위 큐인 heaq(힙) 자료구조를 사용한다. 입력되는 순서를 따지지 않고 입력된 데이터들 가운데에서 우선 순위가 높은 '가장 작은' 데이터값을 순서대로 반환한다. 그래서 방문하는 순서도 간선의 가중치가 작은 순서대로 출력된다. 그리고 한 노드에서 다른 노드로 이동할 때, 거리를 매번 업데이트하여 가장 작은 거리를 입력할 수 있는 체크 배열 크기의 리스트가 필요하다.
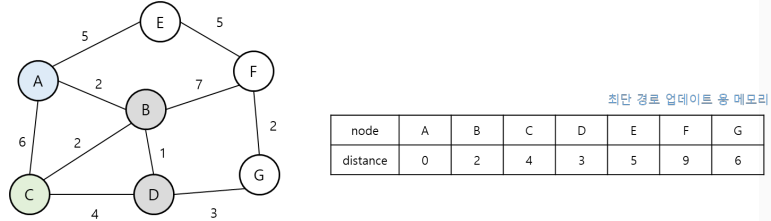
A노드부터 다른 모든 노드로 가는 최단 경로의 탐색 순서는 위와 같은데,
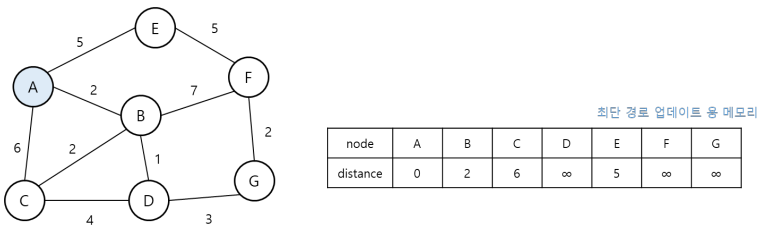
1. 출발 노드를 설정하고 최단 경로를 업데이트할 리스트를 '매우 큰 값(무한)'으로 초기화(더 작은 값으로 업데이트 하기 위해)한다.
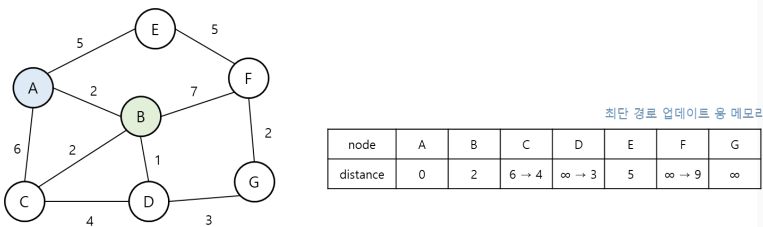
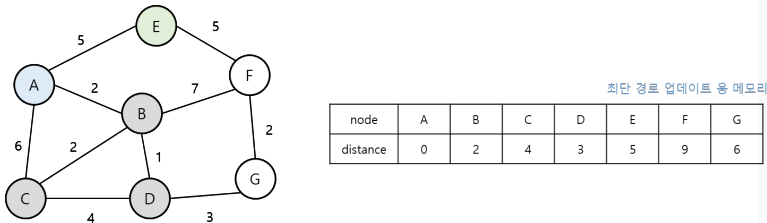
2. 현재 노드에서 다음 노드로 뻗어갈 때는 방문하지 않은 노드 중에서 힙 자료구조를 이용하여 거리가 가장 짧은 노드부터 방문한다.
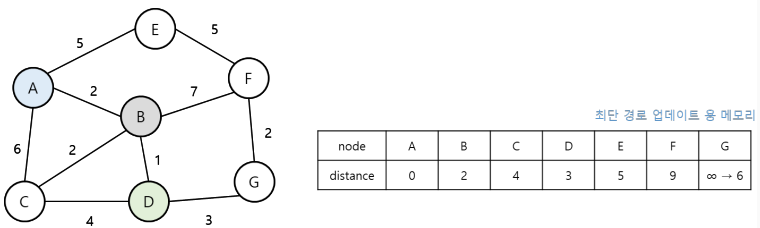
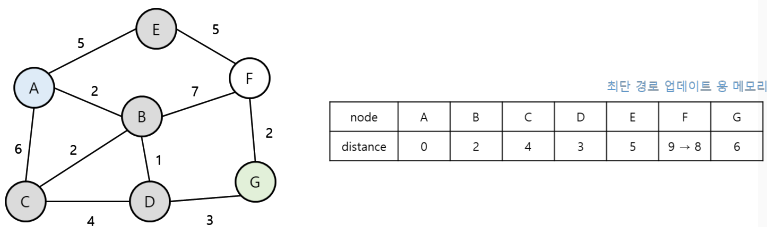
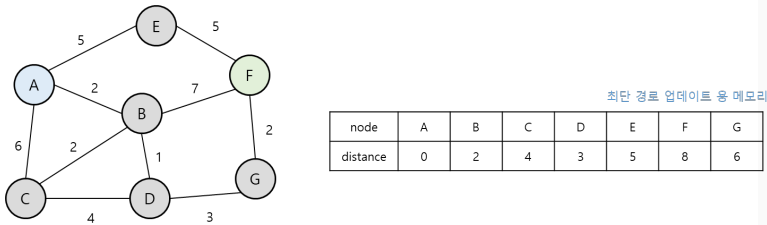
3. 현재 노드에서 다음 지점으로 뻗어갈 때마다, 해당 노드까지의 거리가 기존의 거리보다 짧다면 최단 거리 테이블을 더 짧은 거리의 데이터 값으로 업데이트 한다.
4. 위의 과정을 계속 반복한다.
현재 노드 중에서 가장 짧은 거리를 탐색 중 더 짧은 거리가 나온다면 갱신하며, 이 갱신된 거리가 가장 짧은 거리라고 판단하고 수행하는 점에서 그리디 알고리즘으로 볼 수도 있다.
4. 코드
import heapq def dijkstra(start, graph): n = len(graph) - 1 # 그래프(파이썬)는 0부터 시작하기에 1을 빼준다. dist = [1e9] * (n + 1) # n까지 포함, 거리는 무한(상대적으로 작은 값으로 업데이트 됨으로)으로 초기화 dist[start] = 0 # 시작지점 '1'의 거리를 0으로 초기화(자신에서 자신까지 거리는 0) heap = [] heapq.heappush(heap, (0, start)) # (비용, 노드) 시작값 입력 while heap: cost, node = heapq.heappop(heap) if dist[node] < cost: # 기존의 거리(dist)가 현재보다 작다면 업데이트 하지 않는다. continue for Nnoed, Ncost in graph[node]: # 현재 노드에서 방문할 수 있는 다음 노드 순회 new_cost = cost + Ncost # 현재까지 거리 + 현재->다음 노드 거리 if new_cost < dist[Nnoed]: # 현재 노드에서 다음 노드까지의 거리가, 기존의 거리보다 작다면 dist[Nnoed] = new_cost heapq.heappush(heap, (new_cost, Nnoed)) # 방문한 노드를 큐에 입력 return dist # 최종 업데이트 된 거리 if __name__ == '__main__': graph = [[] for _ in range(8)] inputG = [ (1, 2, 2), # 1 -> 2: 가중치 2, 2 -> 1: 가중치 2 (1, 3, 6), # 1 -> 3: 가중치 6, 3 -> 1: 가중치 6 (1, 5, 5), (2, 3, 2), (2, 6, 7), (2, 4, 1), (5, 6, 5), (6, 7, 2), (3, 4, 4), (4, 7, 3) ] for a, b, c in inputG: graph[a].append((b, c)) # 양방향 그래프: a -> b: c, b -> a: c graph[b].append((a, c)) for i in graph: print(i) start = 1 # 시작 노드 dist = dijkstra(start, graph) print('dist:', dist[1:]) # 그래프는 0부터 시작 출력: dist: [0, 2, 4, 3, 5, 8, 6]
