1. 탐색(Search)
탐색은 많은 데이터들 가운데 원하는 데이터를 찾아가는 과정이다.
2. DFS
DFS는 깊이 우선 탐색이라 불리며 그래프에서 깊은 부분을 우선적으로 탐색하여 출력하는 알고리즘이다. 마지막 노드까지 내려가면 더 이상 깊이 탐색할 것이 없기에 마지막 노드를 출력하거나 체크한 후에 부모 노드로 다시 올라가고(Backtracking) 다른 자식 노드로 뻗어간다. 그래프는 아래와 같이 노드(Node)와 노드들 사이를 이어주는 간선(Edge)으로 이루어져있다.
그래프는 트리의 형식일 수도 있고 무작위 연결된(양방향 연결 혹은 방향 연결) 형식이 수도 있다.
알고리즘 문제의 형식마다 적용해야 하는 방법은 천차만별이지만 대표적으로 4가지를 염두해두고 DFS를 사용하는데, 순열, 중복순열, 조합, 부분집합을 구하는 방식으로 문제를 풀어나간다. 이번 챕터는 중복순열이며 각각의 방식에 따라 어떻게 DFS가 이용되는지 알아보자.
3. 중복순열
서로 다른 n개의 원소에서 r개를 중복은 없게 그리고 순서를 따져가며 나열하는 것을 순열이라고 한다. 예로 1, 2, 3이 있으면 3개 중 2개를 뽑는 방법은 (1, 2), (1, 3), (2, 1), (2, 3), (3, 1), (3, 2) 6개로 기호로는 nPr로 나타낸다. 중복순열은 중복을 허용하며 순서를 따져가며 나열하는지를 다룬다. 중복을 몇 번까지 허용하며 탐색을 하는지 문제에 따라서 변형을 해주면 될 것이다.
4. 1 문제
n개의 숫자카드가 주어지면 k개를 뽑을 수 있는 경우를 DFS를 이용하여 중복을 한 번 허용하는 순열로 나열하고 몇 가지 경우의 수가 생기는지 출력하시오.
n = [2, 4, 6, 8], k = 2
4.2 풀이
순열(순열을 설명한 전 챕터 참고)은 중복을 허용하지 않는다. 그래서 탐색을 할 때 n 크기만큼의 체크 배열을 만들어 반복문 실행시 앞의 순회에서 선택된 인덱스의 값을 반복하지 않게 했다. 그림과 같이 앞의 순회에서 '2'가 선택이 되면 '2'를 제외한 나머지를 순회하는 것이다.
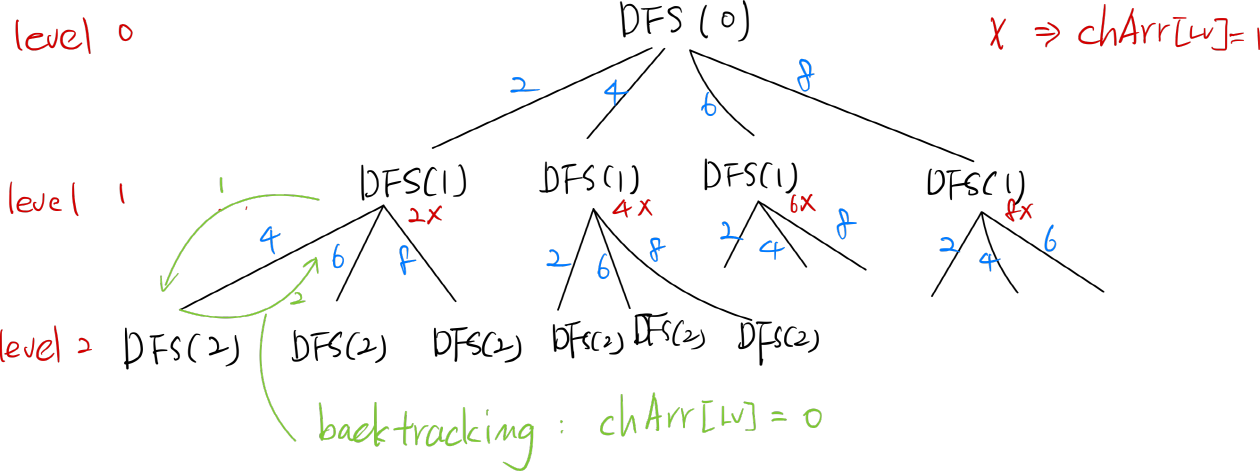
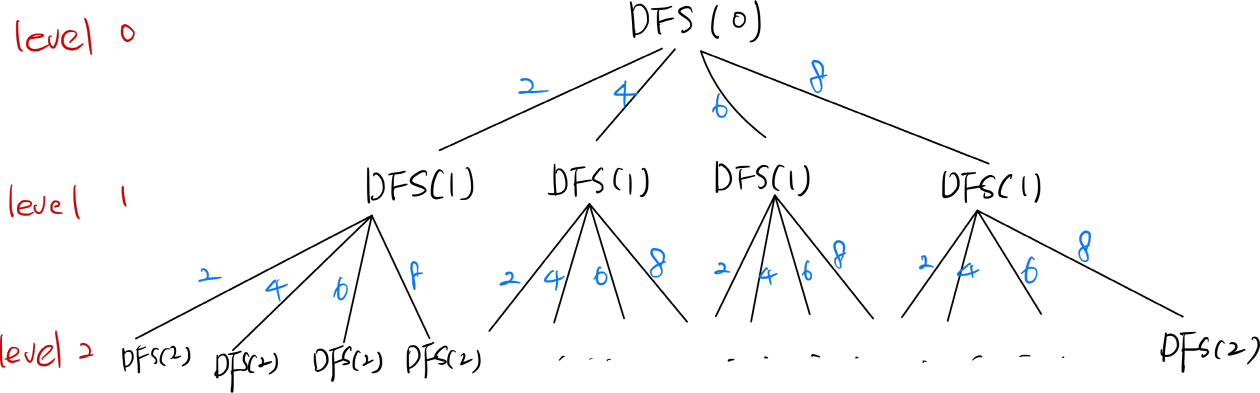
중복순열은 순열일 때와는 다르게 중복을 허용하기에 체크 배열은 따로 생성하지 않고 'level k' 깊이까지 내려가면서 순회한 것을 출력해주면 된다. 체크 배열을 따로 생성하지 않기에 2중 반복문을 실행하듯이 그림과 같이 모든 인덱스를 순회하며 출력한다.
K값이 2로써 level이 2만큼의 깊이로 내려가서 탐색한 후 탐색한 값을 조건문을 통해 출력한다.
1. DFS lv이 0일 때 else문의 for 반복문을 통해 인덱스로 순회한다. 먼저 인덱스가 0인 '2'가 per(lv:0)에 추가되고 DFS(1)을 호출한 후, 다시 반복문을 통해 인덱스가 0인 '2'가 per(lv:1)에 추가된다.
2. lv이 2가 되면 if문이 실행되어 per이 순서대로 출력되고 함수는 종료, 그 후 else문의 반복문이 인덱스 1인 '4'를 per에 업데이트한다. 다시 if문에서 출력 그리고 반복문 실행의 순으로 계속 진행된다.#중복을 허용하지 않는 순열에서 사용한 체크 배열을 제외하면 순열과 같다. def DFS(lv): global count if lv == k:# k개 만큼의 깊이로(2개를 뽑기에 level 2까지 순회) 내려왔을 때 조건문에 의해 출력되고 DFS 종료 후, 반복문 다음 DFS 실행 순으로 for i in per: print(n[i], end=' ') print() count += 1 # 하나의 순열이 만들어질 때 마다 수를 센다. else: for j in range(len(n)):# 중복이 허용되기에 반복문은 처음부터 끝까지 순회하도록 한다. per[lv] = j # level의 깊이(0, 1)에 따라서, 출력할 인덱스 번호를 업데이트. DFS(lv + 1) # 반복문이 순회하면서 lv에 따라서 덮어쓰기에 순회만 하면 된다. if __name__ == '__main__': n = [2, 4, 6, 8] k = 2 per = [0] * k # 순열을 담을 체크 배열 생성 count = 0 DFS(0) print('count: ', count) 출력: 2 2 2 4 2 6 2 8 4 2 4 4 4 6 4 8 6 2 6 4 6 6 6 8 8 2 8 4 8 6 8 8 count: 16