
- 전체보기(56)
- CNN(5)
- Stable Diffusion(5)
- Object Detection(5)
- YOLO(4)
- ViTPose(3)
- Vision Transformer(3)
- boj(3)
- Deep Learning(3)
- pose estimation(3)
- NLP(3)
- VAE(3)
- Contrastive Learning(2)
- DNN(2)
- kaggle(2)
- Computer Vision(2)
- 이분탐색(2)
- LDM(2)
- Bounding Box(2)
- Keras(2)
- Resnet(2)
- RNN(2)
- LLM(2)
- Anomaly Detection(2)
- git(2)
- Anomaly Segmentation(2)
- 딥러닝(2)
- 포스코 ai big data 아카데미 20기(2)
- Attention(2)
- 포스코 ai big data 아카데미(2)
- 한이음(2)
- Lora(2)
- 머신러닝(2)
- LSTM(2)
- ViT(2)
- 캐글(2)
- Latent space(2)
- transformer(2)
- YOLOv8(2)
- Image Generation(1)
- 객체 인식(1)
- cold start(1)
- MetaFormer(1)
- ControlNet(1)
- causal inference(1)
- MicroNet(1)
- YOLO yaml(1)
- Image Synthesis(1)
- Soft NMS(1)
- Fire module(1)
- GPT(1)
- image embedding(1)
- ML/DL(1)
- inpainting(1)
- fewer parameters(1)
- 백준 1920번(1)
- CEVAE(1)
- attention mechanism(1)
- 경량화기법(1)
- NMS란(1)
- CNN inductive bias(1)
- bisect(1)
- Object pose estimation(1)
- Fast(1)
- 한이음블렌디드러닝(1)
- latent variables(1)
- 메뉴 추천(1)
- git 초급(1)
- 아카데미 20기(1)
- Knowledge distillation(1)
- programmers(1)
- 한이음프로젝트(1)
- Randomforest(1)
- git repository(1)
- Seq2Seq(1)
- LoRA adaptation(1)
- Image Captioning(1)
- Shift-based convolution(1)
- parameter tuning(1)
- anchor box(1)
- bounding box to polygon(1)
- 이미지처리(1)
- SOTA(1)
- Graph(1)
- 프로그래머스(1)
- Mixture of Experts(1)
- interpretability(1)
- sam(1)
- PatchCore(1)
- bayesian(1)
- 모델 경량화(1)
- Paper(1)
- 한이음 공모전 수상(1)
- 키즈카페 입지선정(1)
- ORB(1)
- Active Shift(1)
- Pretrained model(1)
- 교육(1)
- Roboflow(1)
- Image Augmentation(1)
- config management(1)
- 경량 네트워크(1)
- deep learning embedding(1)
- UCAD(1)
- multi-class anomaly detection(1)
- 포유드림(1)
- vision-language understanding task(1)
- POSTECH(1)
- Inception-v4(1)
- Custom Dataset(1)
- SqueezeNet(1)
- Non-local block(1)
- hybrid approaches(1)
- SVM(1)
- 딕셔너리(1)
- 피보나치(1)
- 임베디드 디바이스(1)
- Continual Learning in Anomaly Detection(1)
- AE(1)
- 지식증류기법(1)
- Causal Effect(1)
- project(1)
- 케라스(1)
- PyTorch(1)
- CNN 경량화(1)
- AutoEncoder(1)
- 컴퓨터 비전(1)
- knowledge decomposition(1)
- DP(1)
- 경량화툴(1)
- git 강의(1)
- fault detection(1)
- Sliding Window(1)
- 군집화(1)
- Yolo 구조(1)
- Encoder / Decoder(1)
- multi-view generation(1)
- Yolo 버전별 특징(1)
- 파이토치(1)
- yaml(1)
- Collaborative Filtering(1)
- Hybrid recommender systems(1)
- AI big data 교육(1)
- NeRF(1)
- 캐글 분류문제(1)
- TensorFlow Lite(1)
- YOLO 학습(1)
- bottom up(1)
- German Traffic Sign Benchmark(1)
- GoogleNet(1)
- 입지선정 프로젝트(1)
- 영상 분류(1)
- zeroshot prediction(1)
- GPT 답변길이(1)
- SDS(1)
- 한이음 후기(1)
- python(1)
- 과적합 방지(1)
- Prompt Tuning(1)
- 딥러닝모델(1)
- counter(1)
- Posco AI Big Data Academy(1)
- 콘텐츠 기반 추천(1)
- condition ldm(1)
- 무려20기(1)
- 컨텐츠 기반 추천(1)
- bottleneck(1)
- 객체 검출 경량화(1)
- Recurrent Model(1)
- latent diffusion model(1)
- GPT API error(1)
- No-category(1)
- 콜백함수(1)
- 추천시스템 사용예제(1)
- 경량화 기법(1)
- ROI(1)
- 자기계발(1)
- Residual block(1)
- offset(1)
- BRIEF(1)
- yolov5(1)
- 이진탐색 알고리즘(1)
- RateLimitError(1)
- colab(1)
- 인공신경망(1)
- 디바이스 객체 검출(1)
- huggingface(1)
- single image pose estimation(1)
- 한이음 프로젝트(1)
- 분류기 비교(1)
- skip connection(1)
- 한이음 ICT 멘토링(1)
- Token Mixer(1)
- docker(1)
- KL divergence derivation(1)
- latent diffusion models(1)
- 자연어처리(1)
- rcnn(1)
- 하이퍼파라미터(1)
- 포스코 아카데미 후기(1)
- 코테(1)
- Deep Neural Network(1)
- git 초보(1)
- item-to-item(1)
- YOLO hyper parameter(1)
- 도커 딥러닝 환경(1)
- 포스코 아카데미 20기(1)
- 온디바이스(1)
- Air(1)
- BERT(1)
- scalability(1)
- Exploitation-Exploration(1)
- Shift operation(1)
- sd(1)
- 한이음유데미(1)
- 자격증(1)
- posco(1)
- WGAN-GP(1)
- config(1)
- big data(1)
- 유튜브 추천시스템(1)
- git 명령어(1)
- 텐서플로(1)
- 머신러닝분류모델(1)
- callbacks(1)
- Classification(1)
- No-Cad(1)
- stable diffusion webUI(1)
- paper-review(1)
- Zero123(1)
- wgan(1)
- Data Analytics(1)
- simon funk's SVD(1)
- Vanishing gradient(1)
- image classification(1)
- MVDream(1)
- 3D Generation(1)
- 추천시스템(1)
- ANN(1)
- Recommender System(1)
- feature descriptor(1)
- roboflow dataset(1)
- Industrial Image Anomaly Detection(1)
- pytorch JIT(1)
- industrial anomaly detection(1)
- tensorflow(1)
- mode collapse(1)
- ICT멘토링(1)
- NVIDIA APEX(1)
- AI(1)
- 유데미(1)
- 머신러닝분류기 비교(1)
- CLDM(1)
- git 시작하기(1)
- 딥러닝 모델 경량화(1)
- prefix tuning(1)
- TensorRT(1)
- deep learning experiments(1)
- Non Maximum Suppression(1)
- Pytorch 경량화(1)
- MOE(1)
- 포스코 아카데미(1)
- 1 stage detector(1)
- VLP(1)
- detection model(1)
- content-based recommendation(1)
- SyncDreamer(1)
- tesorflow(1)
- 교통표지판 분류(1)
- 독일 교통표지판(1)
- self-attention(1)
- Vision-Language(1)
- iou(1)
- Linkedin 추천시스템(1)
- 한이음 gitlab(1)
- NMS(1)
- hydra(1)
- hyp.scratch-low.yaml(1)
- bounding box anchor box 차이(1)
- latent-factor methods(1)
- augmentation parameter(1)
- 포스코 포유드림(1)
- openai API(1)
- GPT API 사용(1)
- 추천방정식(1)
- Negative sampling(1)
- OPE toxanomy(1)
- Yolo Architecture(1)
- 2 stage detector(1)
- Bisect 라이브러리(1)
- segment anything(1)
- 커스텀 데이터셋 학습하기(1)
- slow&fast(1)
- Natural Language Processing with Disaster Tweets(1)
- YOLO parameter(1)
- Git 공부(1)
- segmentation(1)
- quantization(1)
- 추천 알고리즘(1)
- youtube 추천시스템(1)
- inception(1)
- 크롤링(1)
- variational autoencoder(1)
- clip(1)
- GTSRB(1)
- github(1)
- Yolo version(1)
- 딥러닝모델 경량화(1)
- Wasserstein loss(1)
- roboflow object detection to segmentation(1)
- image-to-text generation(1)
- 캐글 교통표지판분류(1)
- VISION(1)
- Binary Search(1)
- 백준(1)
- 이진탐색(1)
- MobileNetv3(1)
- GPI API 답변생성(1)
- 계산 그래프(1)
- temporal CNN(1)
- on-device AI SOTA(1)
- selective-search(1)
- Embedding(1)
- 딥러닝 프레임워크(1)
- Recommender Systems(1)
- stable diffusion install(1)
- Low-Rank Adaptation(1)
- 2022 한이음 공모전(1)
- opencv(1)
- 150370번(1)
- shufflenet(1)
- Threshold(1)
- 텍스트분석(1)
- dreamfusion(1)
- 분류모델비교(1)
- Overlap problem(1)
- confidence score(1)
- Yolo 버전별 성능(1)
- 포항공대(1)
- 공부(1)
- region-proposal(1)
- 동적계획법(1)
- detector(1)
- Sequence Model(1)
- Inductive Bias(1)
- 2023 강서구 빅데이터 활용 공모전(1)
- dynamic programming(1)
- video-classification(1)
- DP예제(1)
- Hyper-parameter(1)
- Long Term Dependency(1)
- Adapter(1)
- Action classification(1)
- Yolo series(1)
- Video Recognition(1)
- 협업 필터링(1)
- Yolo SOTA(1)
- NeuS(1)
- 모델 파라미터(1)
- 도커(1)
- gan(1)
- 시각화(1)
- GPT 토큰(1)
- 카카오블라인드(1)

[paper] ControlNet, Adding Conditional Control to Text-to-Image Diffusion Models
ControlNet은 Stable Diffusion 모델에 조건을 추가하여 더 정밀한 이미지 생성을 가능하게 하는 신경망 아키텍처입니다. Stable Diffusion은 원래 텍스트 입력을 바탕으로 이미지를 생성하는 모델로, 입력된 텍스트에 따라 이미지를 생성할 수 있

Docker container 환경 구축하기, 서버 간 파일 전송
사용하고 있는 서버에서 다른 서버로 프로젝트 옮기기.. > 상황 ssh접속으로 사용하고 있는 서버에서 gpu사양이 더 좋은 다른 서버로 코드 및 파일 전체, conda 가상환경을 이동하고자 함 현재 사용 서버에는 도커 없음, 루트계정 권한 없음 (일반사용자계정)
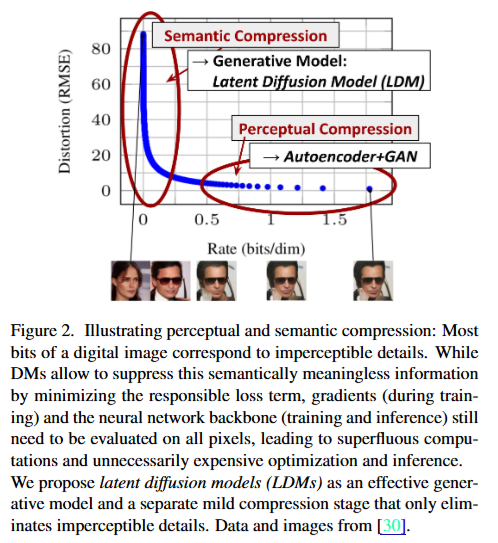
[paper] Stable diffusion
Stable Diffusion은 2022년 8월 Stability AI에서 발표한 text-to-image 생성 모델로, 오픈소스로 공개되어 인공지능 이미지 생성 분야에서 큰 주목을 받았는데요, 24년 12월 기준 1만 2천회가 넘는 인용수를 가지는 논문입니다. 최근

YAML과 Hydra를 이용한 config 관리
딥러닝이나 머신러닝 프로젝트를 하다 보면, 모델의 config 파일을 통해 학습에 필요한 다양한 설정을 정의하게 됩니다. 이러한 설정 파일을 만들 때 가장 많이 사용하는 포맷이 YAML입니다. 또한, 설정 파일을 효율적으로 관리하고, 다양한 실험 환경을 지원하기 위해
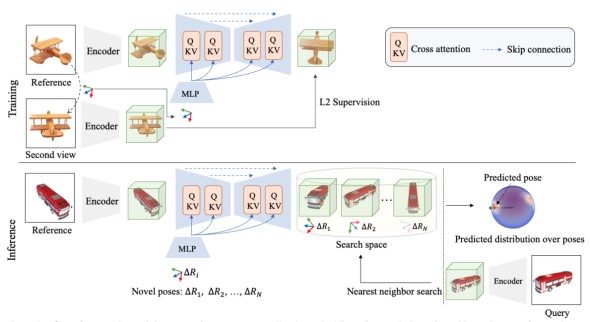
[paper] NOPE: Novel Object Pose Estimation from a Single Image
NOPE: Novel Object Pose Estimation from a Single Image은 arxiv 기준 23년 3월에 게재된 페이퍼입니다. 페이퍼 내용에 앞서 6D pose estimation task를 살펴보겠습니다. 먼저 최근 6D Pose esti
Roboflow 데이터셋 유형변경 - Object Detection에서 Instance Segmentation
바운딩 박스로 되어있는 object detection 데이터셋을 이용해서 segmentation 데이터셋으로 변경하고 싶을 때, 좌측의 annotate로 들어가서 이미지를 연다.우측의 툴바에서 polygon tool 또는 smart polygon tool을 사용하여 s
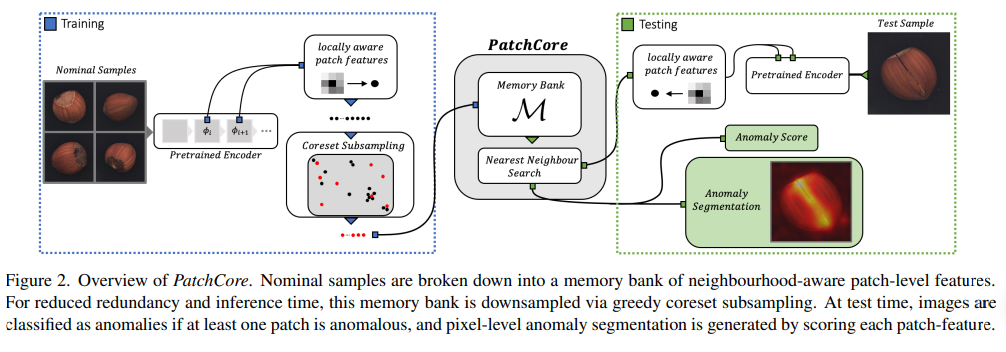
[paper] PatchCore: Towards Total Recall in Industrial Anomaly Detection
Towards Total Recall in Industrial Anomaly Detection (CVPR, 2022) locally-aware patch 비교 및 coreset subsampling을 통한 idustrial anomaly detection
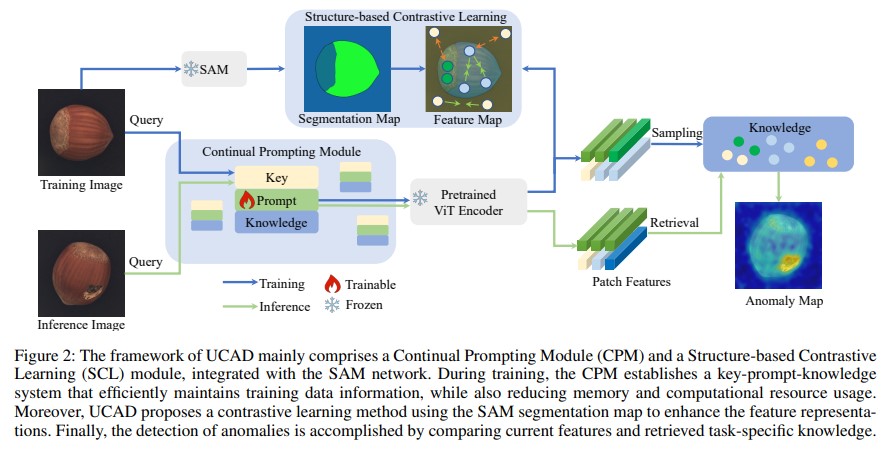
[paper] Unsupervised Continual Anomaly Detection with Contrastively-learned Prompt
catastrophic forgetting없이 하나의 모델에서 multi-object를 지속적으로 학습하고, task 간 transfer가 자유로운 anomaly detection 모델\*여기서 말하는 task는 다른 object category, anomaly det
OpenAI API로 여러 데이터에 대한 답변 뽑을 때 주의* - RateLimitError, InvalidRequestError
json데이터나 csv에서 각 row에 대한 답변을 받으려고 할 때, 다음과 같은 에러가 나타났다.. 토큰 아끼려고 데이터 하나 넣어서 함수 만든거 동작하는지 확인한 다음 전체 데이터에 대해 돌렸는데 에러 발생RateLimitError: Rate limit reach

3D Object Generation 기술 동향, 모델 비교- Zero123, MVDream, SyncDreamer
연구원에서 세미나 열리는거 메일받고 듣고싶어서 실장님께 말씀드리고 다른 연구실 세미나 참석하기 KAIST 박병준 연구원님이 오셔서 3D 콘텐츠 생성 기술동향과 CVPR 2024에서 발표하신 논문을 소개해주셨다. 최근 multi view의 synthetic data 만
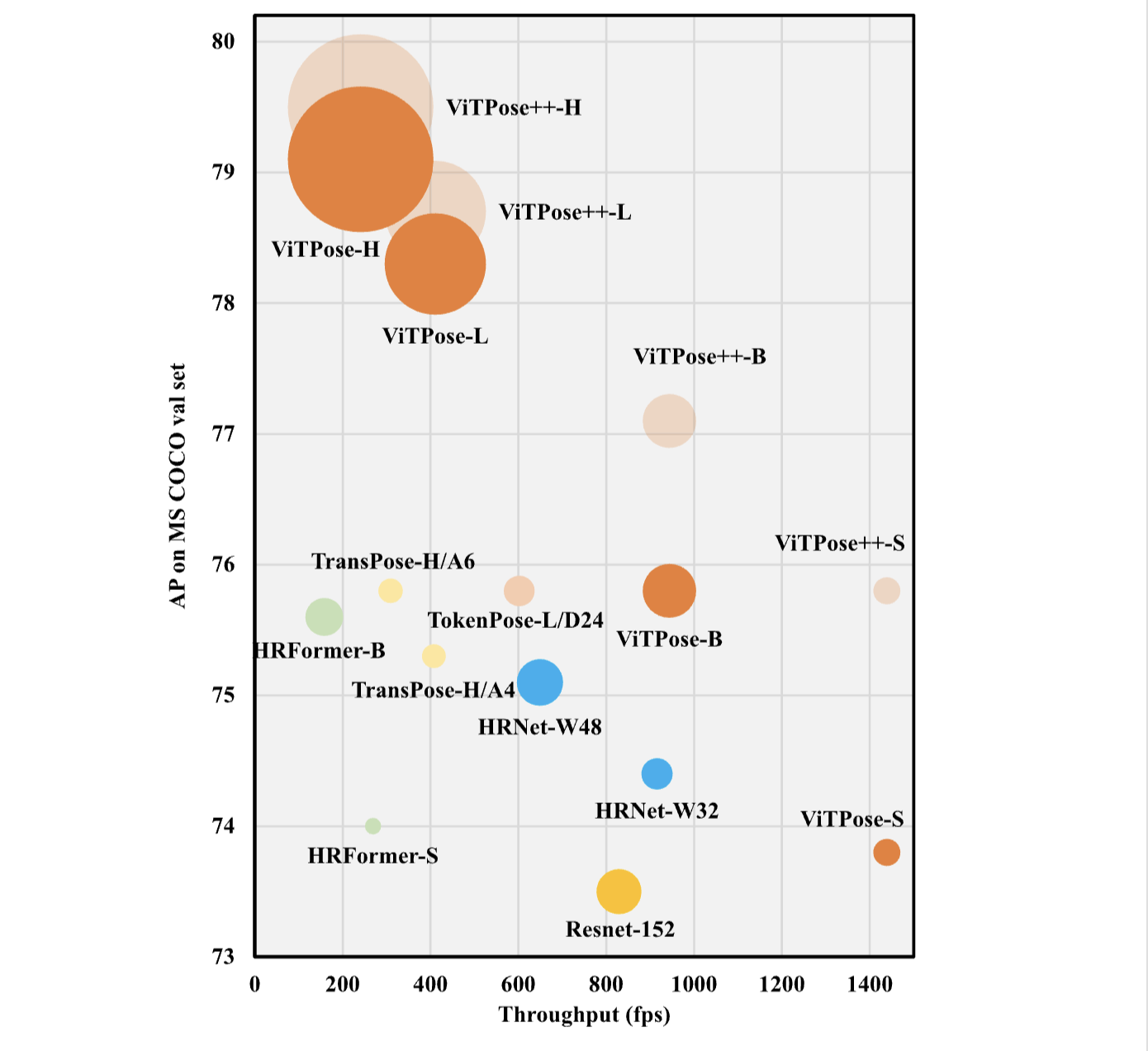
ViTPose++: Vision Transformer for Generic Body Pose Estimation
Vision Transformer는 컴퓨터 비전 작업에서 큰 잠재력을 보여주었으며, human body pose estimation에 적용되어 우수한 성능을 얻었습니다. 기존의 ViTPose에서는 vision transformer를 pose estimation tas
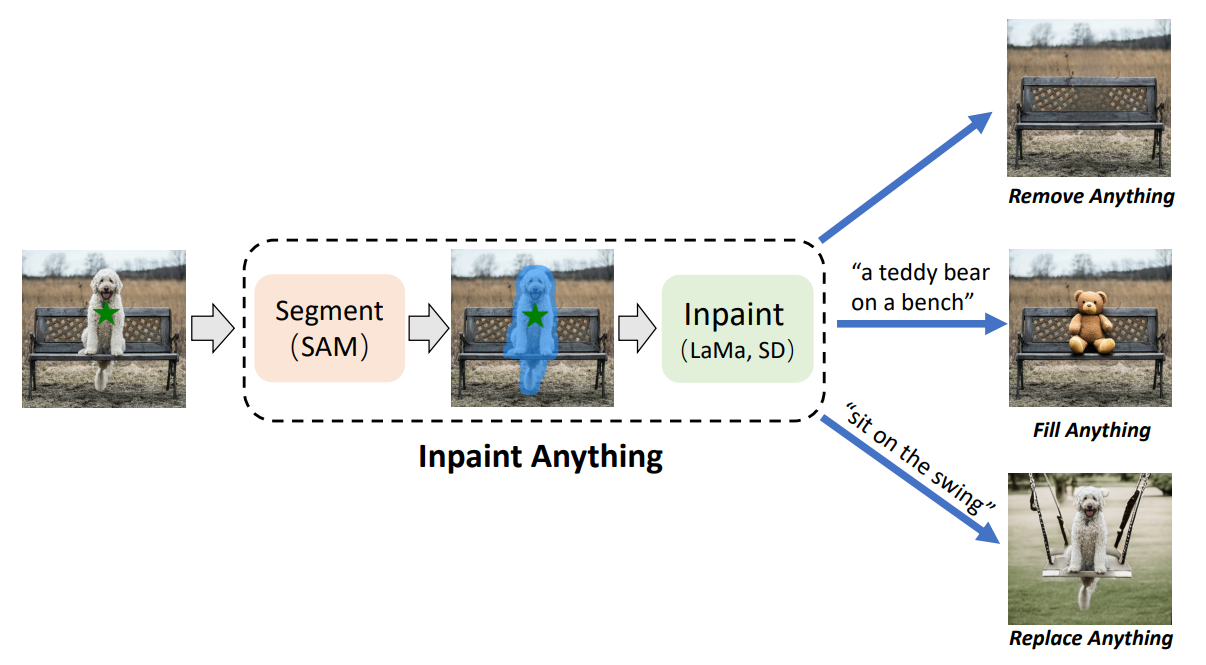
[paper] Inpaint Anything
Inpaint Anything 논문은 23년 4월에 발표되었습니다. 이 논문은 Segment Anything Model(SAM)을 기반으로 한 이미지 인페인팅 시스템을 소개합니다. 이 프레임워크는 다음과 같은 주요 기능을 제공합니다.Remove Anything: 사용자
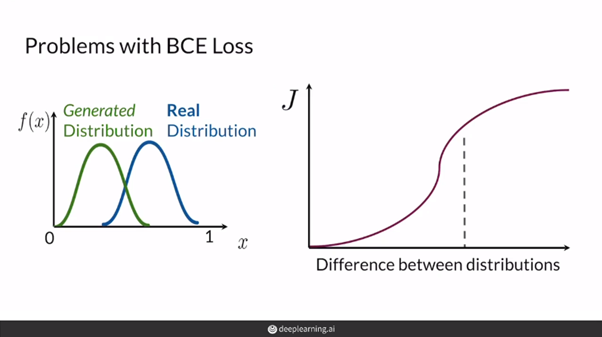
GAN Mode collapse, Wasserstein Loss, Weight Clipping, Gradient Penalty
generator가 discriminator가 못 맞추는 클래스를 파악해서 그 클래스만 계속 생성해서 discriminator가 전부 오분류하도록 하는것 즉 generator가 local minima에 갇힌 것이다. Problem with BCE lossGAN에서 bi
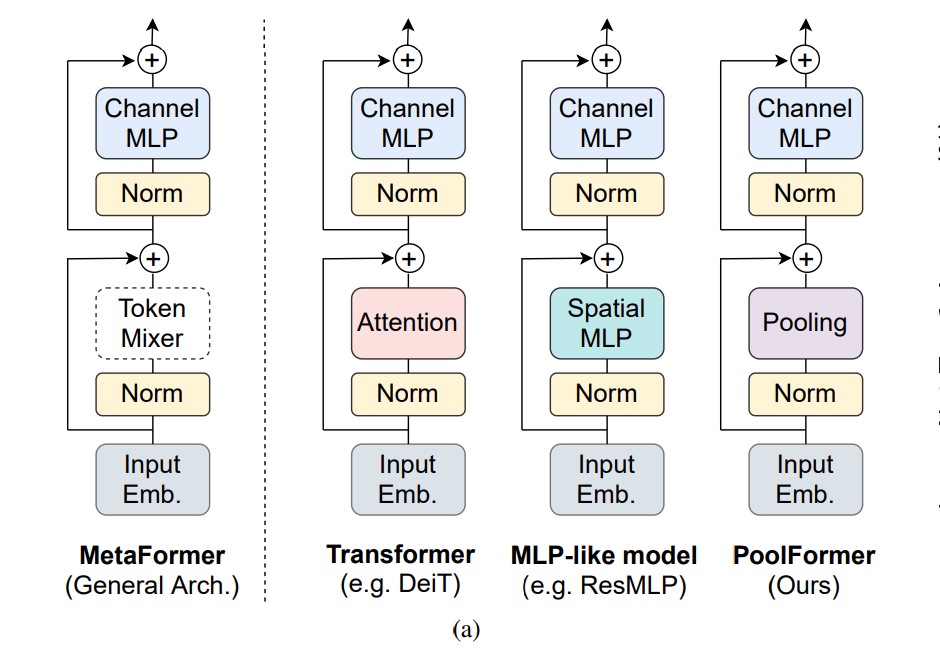
[paper] MetaFormer Is Actually What You Need for Vision
본 글에서는 CVPR에서 22년도에 발표된 MetaFormer is Actually What You Need for Vision, Yu et al.에 대해 간단하게 정리하겠습니다.논문에서는 일반화된 트랜스포머 아키텍처를 제안합니다.여기서 기존 트랜스포머 구조에서 Sel
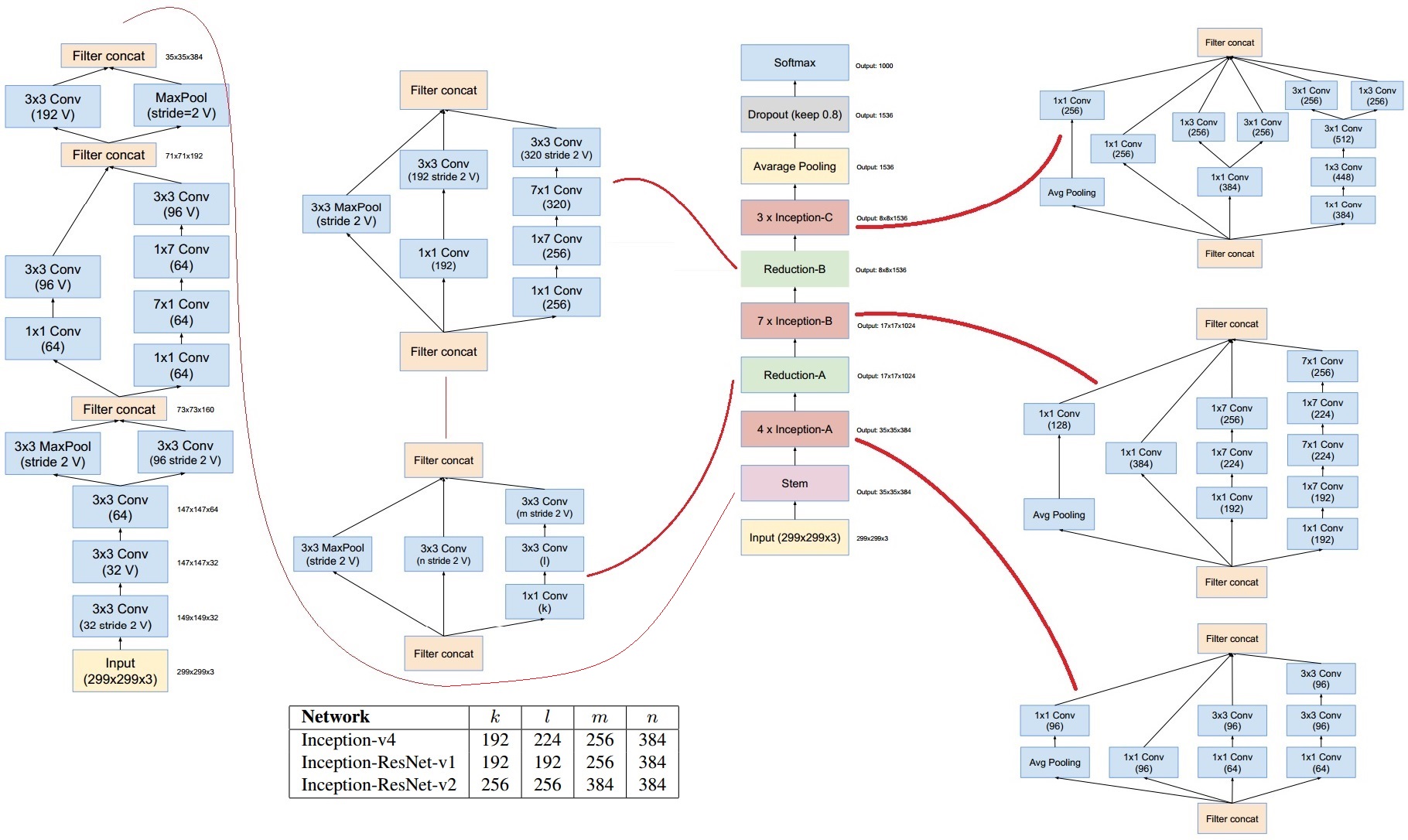
[paper] Inception v4 (2016)
Inception 아키텍처는 초기에 GoogLeNet으로 알려져 있었으며, 이후 Inception v2, Inception v3 등 다양한 버전이 발표되었습니다. Inception v4는 2016년에 소개되었으며, 그 이후로도 다양한 개선이 이루어진 것으로 알려져 있습
PEFT(Parameter-Efficient Fine-Tuning) 라이브러리 : 대규모 Pre-trained Language Model 효과적으로 활용하기
Pre-trained Language Model (PLM) 효율적으로 finetuning하기, PEFT 방법론 ``LoRA``, ``prompt tuning``, ``prefix tuning``
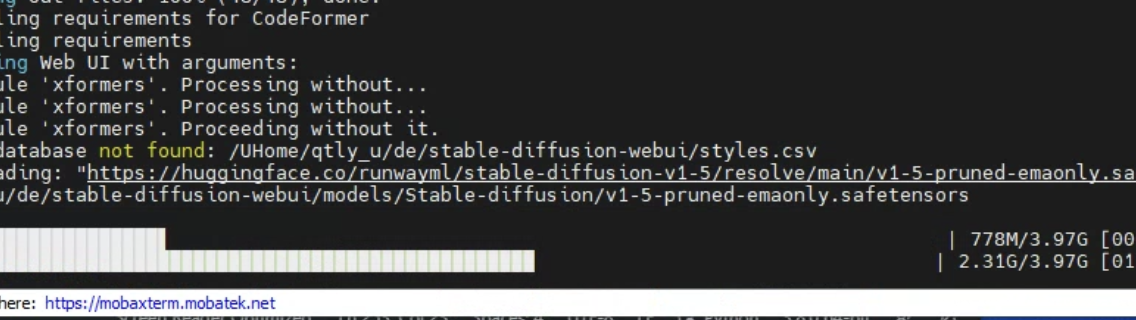
Linux server에서 Stable diffusion web-ui 설치하기
깃헙 설치 매뉴얼처럼 sudo 접근이 불가한 server에서 stable diffusion 설치하기
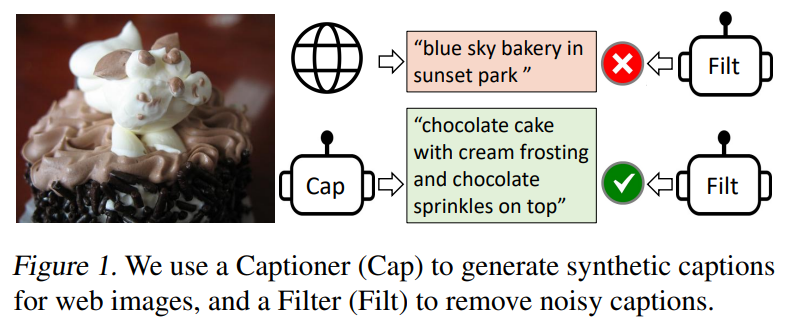
[paper] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
오늘 소개하는 BLIP(paper)는, 2022년 발표된 논문으로 vision-language understanding tasks와 generation-based tasks 모두 유연하게 사용할 수 있도록 아키텍처를 설계하였고, 합성된 캡션을 생성하고 기존
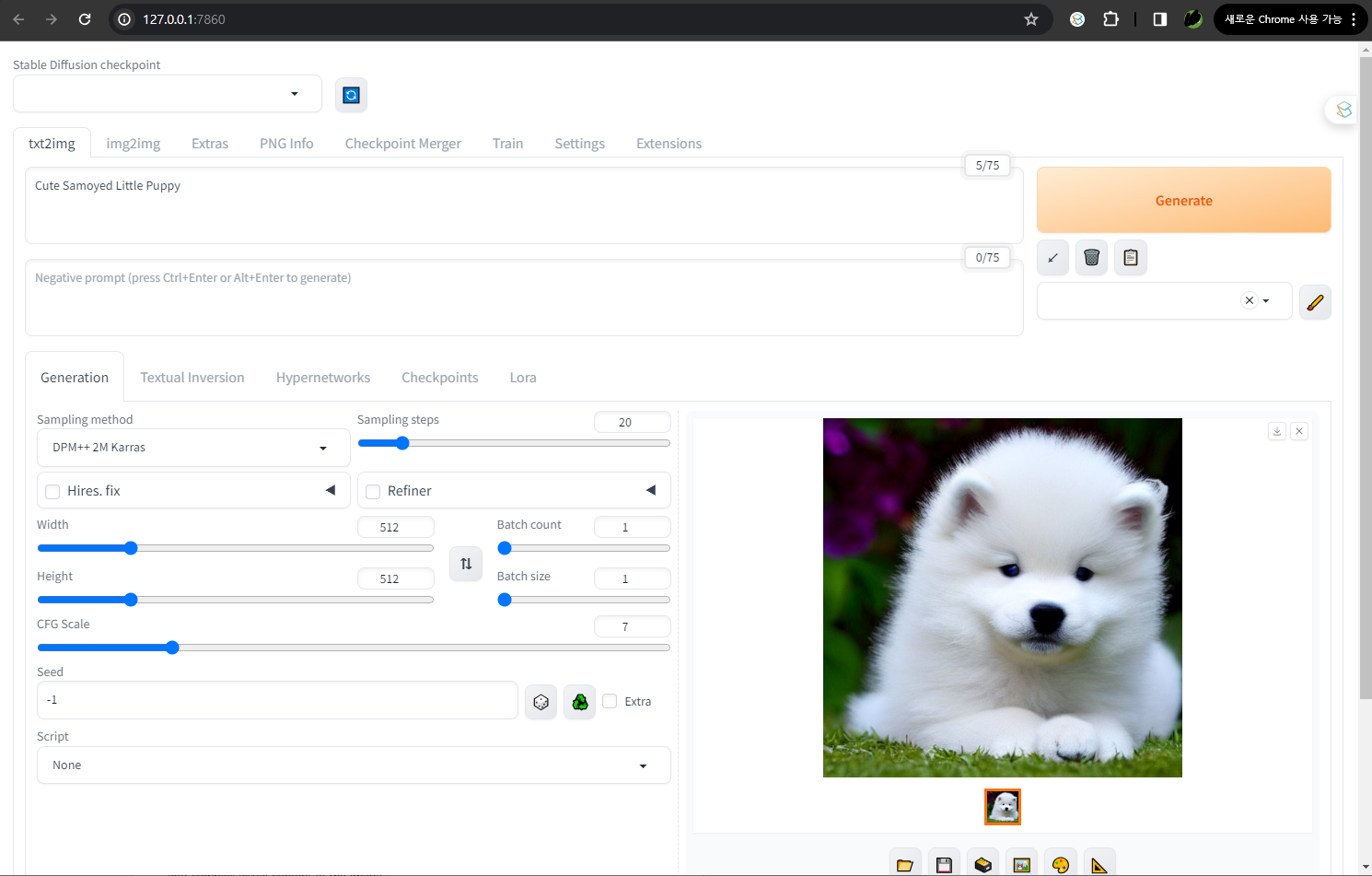
Stable diffusion webui 설치 및 실행방법, 에러
github link : https://github.com/AUTOMATIC1111/stable-diffusion-webui/위 레포지토리를 clone하고 webui-user.bat 파일을 더블클릭하여 실행하면 된다.이때 python을 찾을 수 없다는 에러가
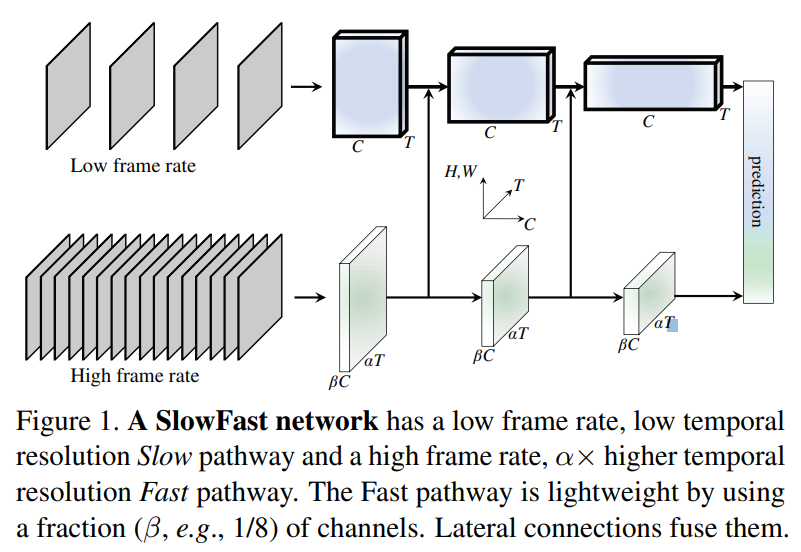
[paper] SlowFast Networks for Video Recognition
SlowFast Networks for Video Recognition 논문 리뷰