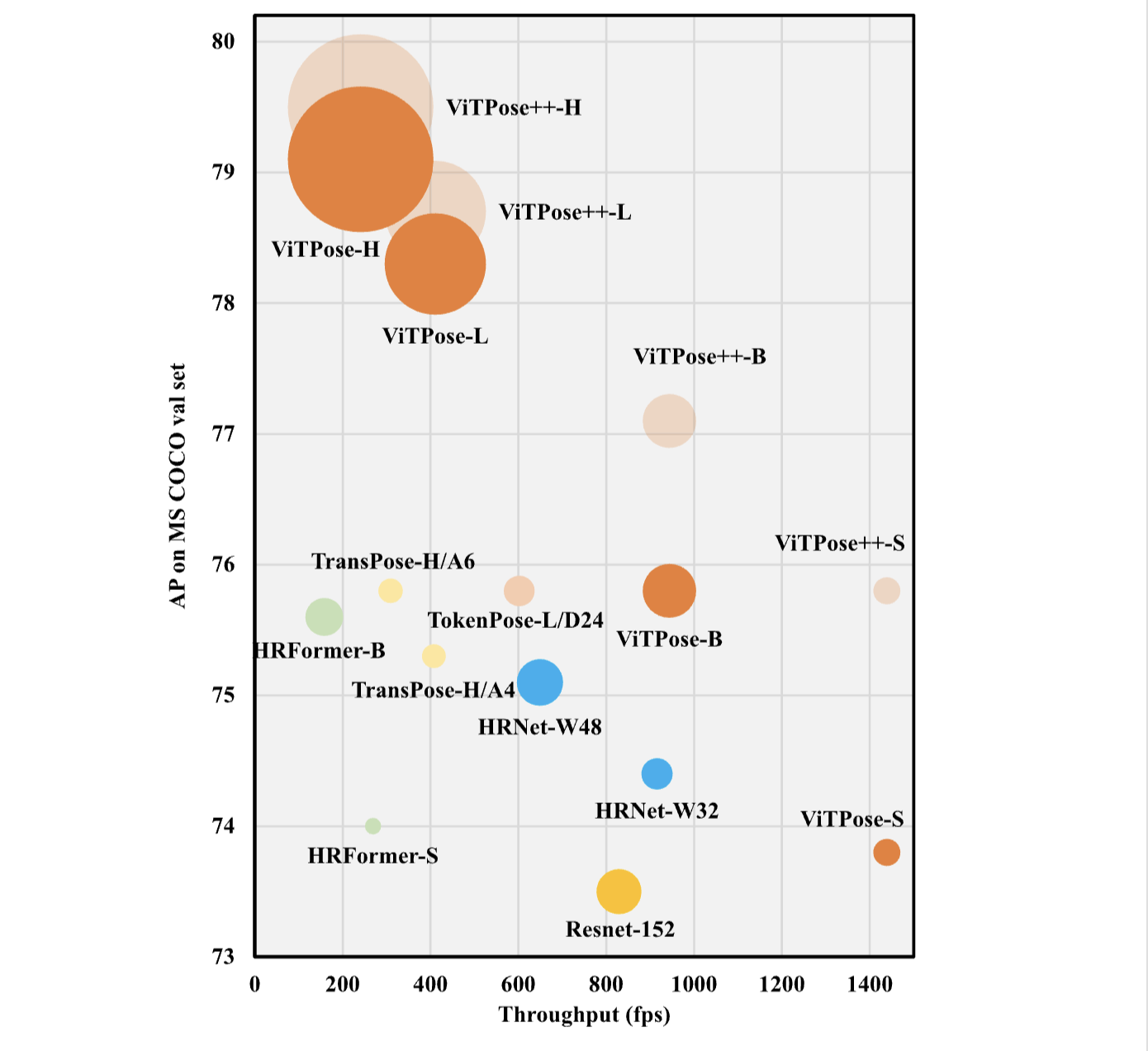
Vision Transformer는 컴퓨터 비전 작업에서 큰 잠재력을 보여주었으며, human body pose estimation에 적용되어 우수한 성능을 얻었습니다.
기존의 ViTPose에서는 vision transformer를 pose estimation task에 적용하면서, 베이스라인을 제시하고 확장성, 단순성 등의 이점을 보여주었습니다.(이전 ViTPose 글 참고) ViTPose++에서는 ViTPose에 MoE 방식을 사용하여 다양한 pose estimation task에서 사용할 수 있도록 지식을 분해하는 방법을 도입했습니다.
간단하게 요약하면 다음과 같습니다.
| ViTPose | ViTPose++ |
|---|---|
| - 비전 트랜스포머를 사용하여 신체 자세 추정을 수행하는 간단한 베이스라인 모델 | - MoE(Mixture of Experts) 방식을 도입하여 지식 분해(knowledge decomposition)를 수행 |
| - 확장성, 단순성 등의 이점을 보여주며, MS COCO 등에서 우수한 성능을 달성 | - FFN 계층을 공통 전문가(task-agnostic expert)와 작업 특화 전문가(task-specific experts)로 분할하여 각각 공통 지식과 작업 특화 지식을 인코딩 |
| - 작업 간 충돌을 최소화하고 다양한 포즈 추정 작업에서 우수한 성능을 달성 | |
| - 추가적인 파라미터나 계산 비용 없이 다양한 신체 키포인트 검출 작업을 효과적으로 수행할 수 있음 |
본 글에서는 ViTPose 부분은 생략하고, ViTPose++에서 제시한 지식분해 방법에 대해 살펴보겠습니다.
다양한 pose estimation task를 위한 MoE방식의 지식 분해(knowledge decomposition):
일반적인 신체 키포인트 검출을 위해서는 다양한 신체 자세 추정 작업을 다룰 수 있어야 합니다. 여기서 중요한 도전 과제는 서로 다른 자세 추정 작업에서 신체 키포인트의 차이를 처리하는 것입니다. 예를 들어, 인간과 동물의 외형이 다른 동일한 키포인트(예: 코), 그리고 MS COCO와 MPII에는 없는 COCO-W의 키포인트 카테고리의 차이를 처리해야 합니다. 또한, 다른 종의 데이터 분포도 다릅니다. 예를 들어, 인간의 머리는 항상 어깨 위에 있지만, 소의 머리는 항상 어깨의 좌우에 위치합니다.
단순한 해결책으로는 ViTPose 모델을 멀티태스크 학습으로 훈련시키는 것입니다. 즉, 공통 백본을 사용하고 각 자세 추정 작업에 대한 별도의 디코더를 사용하는 것입니다. 그러나 이러한 방법은 작업 간 충돌이 발생하여 학습 성능에 영향을 줄 수 있습니다.
ViTPose++에서는 지식 분해 관점에서 이 문제를 해결하고자 하는데, 구체적으로, MoE(Mixture of Experts) 아이디어를 채택하여 FFN 계층을 task-agnostic(작업에 민감하지 않은) 전문가와 task-specific(작업 특화) 전문가로 분할하여 각각 공통 지식과 작업 특화 지식을 인코딩합니다. 이는 MHSA 계층은 자세 추정 작업에 민감하지 않기 때문에 가능하다고 합니다. 각 신체 자세 추정 작업에 대해 작업 특화 디코더를 사용한다는 점에서 앞서 언급한 단순한 멀티태스크 학습 방법과 유합니다.
논문에서 예로 주어진 하나의 트랜스포머 블록을 살펴보겠습니다.
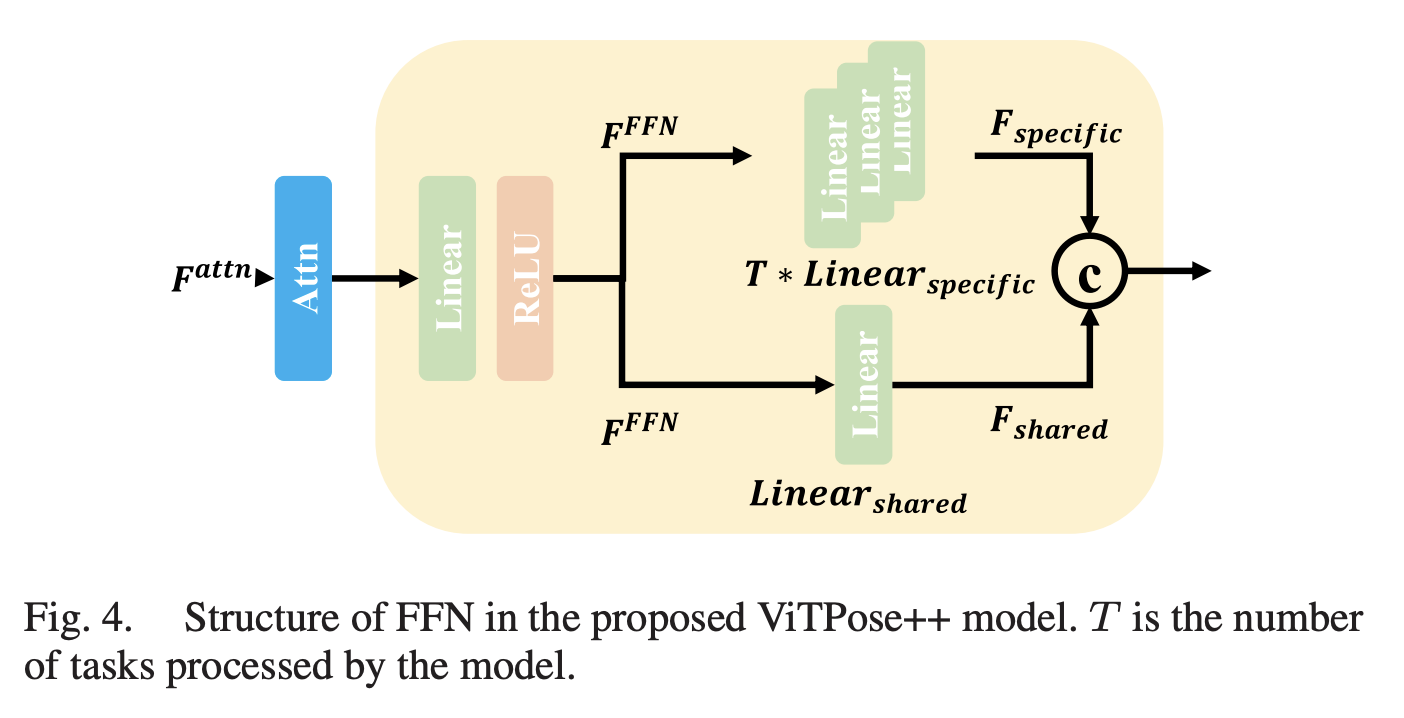
MASA의 ouput feature 가 주어졌을 때, FFN의 첫번째 linear layer에서 처리되고, 그것은 MoE에 의해 공유됩니다.
그런다음, 은 별도의 linear layer들에 전달됩니다. 여기서 N은 토큰 수를, 는 FFN의 확장 비율을 나타내며, 기본값은 4입니다. 두 종류의 전문가가 를 으로 투영하며, 채널 차원은 각각 (1 − α)C와 αC입니다.
여기서 는 shared expert(공유 전문가)와 task-specific expert(태스크 특화 전문가)를 균형 있게 사용하기 위해 설정된 분할 비율로, 기본값은 0.25입니다. 공통 전문가가 전체 채널의 75%를, 작업 특화 전문가가 25%를 차지하도록 합니다. 공통 전문가의 파라미터는 모든 데이터를 사용하여 학습되며, 작업 특화 전문가의 파라미터는 해당 작업의 데이터만 사용하여 학습됩니다. 그런 다음, 은 채널 차원에서 결합되어 트랜스포머 블록의 출력을 형성합니다. 특정 자세 추정 작업의 학습 세트에서 입력 이미지를 받으면, 위에서 설명한 트랜스포머 백본에서 인코딩된 특징을 얻은 후, 해당 디코더에 전달되어 히트맵을 regression합니다.
추론 단계에서는 각 자세 추정 작업에 대해 공유 및 작업 특화 선형 계층이 병합되어 병렬 계산을 수행합니다. 이 방식으로 ViTPose++는 ViTPose 모델과 비교하여 추가적인 파라미터나 계산 비용 없이 일반적인 신체 자세 추정을 위한 foundation model로 기능할 수 있습니다.
Ablation Studies of ViTPose++ and Analysis
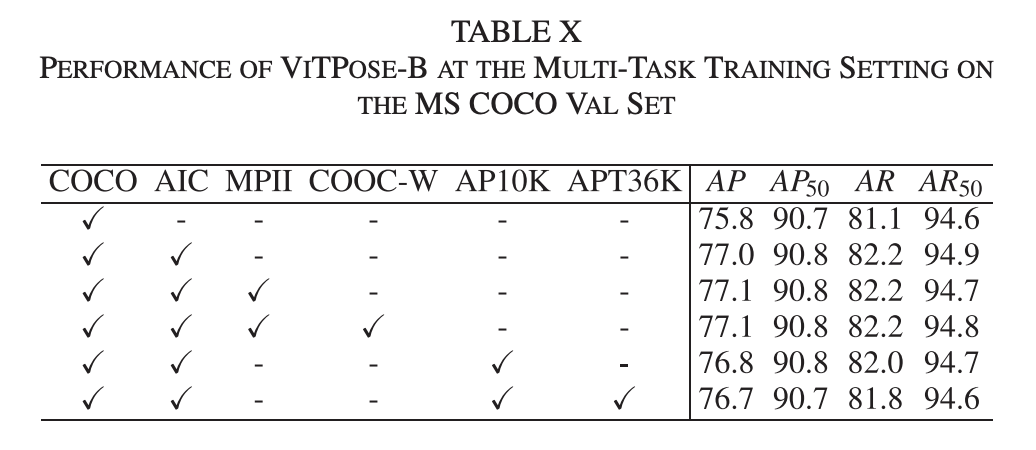
실험결과를 살펴보면, MS COCO val 세트에서 다양한 데이터셋(MS COCO, AIC, MPII 등)을 추가하면서 성능이 지속적으로 향상되는데, 동물 데이터셋(AP-10K, APT-36K)을 포함하면 성능이 약간 하락하는 것을 볼 수 있습니다.
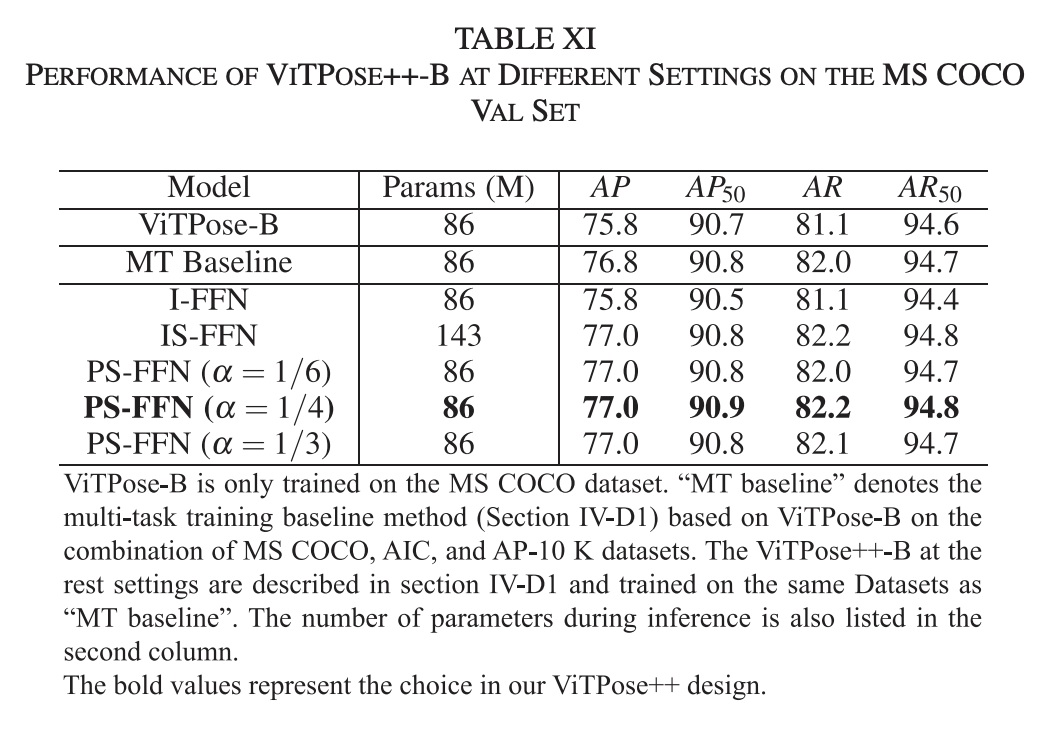
- 독립적인 FFN (I-FFN): 각 작업에 대해 독립적인 FFN을 사용하여 작업 간 충돌을 완화시킬때는 성능은 ViTPose와 비슷하거나 더 나쁩니다.
- 독립 및 공유 FFN (IS-FFN): 공통 지식을 인코딩하기 위해 공유 FFN을 추가로 도입하여 작업별 FFN과 공유 FFN의 출력을 합쳐 다음 레이어로 전달하는 방식에서 I-FFN보다 성능이 좋아집니다.
- 부분적으로 공유된 FFN (PS-FFN): 공통 지식과 작업 특화 지식을 인코딩하기 위해 FFN의 마지막 선형 계층을 공유 부분과 독립 부분으로 분할하는 것인데, 성능과 모델 복잡성 간의 균형을 잘 맞출때(알파 0.25에서) 77.0 AP를 달성합니다.
I-FFN에서는 공통 지식을 모델링하지 않아 성능이 낮고, PS-FFN에서 공통 및 task-specific 지식을 잘 인코딩하여 77.0 AP를 달성하는 것을 볼 수 있습니다.
ViTPose++는 human pose estimation 뿐 아니라 다양한 pose estimation task를 공통적으로 학습하면서도, Mixture of Experts(MoE) 방식을 통해 태스크 간의 충돌을 최소화할 수 있는 방안을 제시했습니다. 이를 통해 다양한 pose estimation task에서 일반적인 foundation model로서 효율적으로 동작할 수 있음을 보였습니다.
감사합니다.
Reference
ViTPose++ Paper
