[paper] Unsupervised Continual Anomaly Detection with Contrastively-learned Prompt
Computer Vision
catastrophic forgetting없이 하나의 모델에서 multi-object를 지속적으로 학습하고, task 간 transfer가 자유로운 anomaly detection 모델
*여기서 말하는 task는 다른 object category, anomaly detection 특성 상 하나의 분류 전체를 독립적으로 학습하고 이상탐지를 하기 때문에
Introduction
- Unsupervised Anomaly Detection (UAD) : 사전 지식이나 레이블없이 이상치를 탐지
- industrial manufacturing처럼 잘 레이블된 결함 데이터를 얻기 힘들 경우 유용한 접근방식
- 다양한 클래스에 이상탐지 모델을 사용하기 위한 최근 연구
- 다양한 클래스에 대한 훈련 → 테스트 시에 class identiy에 의존
- 개별적인 모델로 분리 → computational 부담
- UniAD : 다양한 클래스들을 다루기 위한 하나의 통합 모델
- 그러나 실제 적용할 때, 학습이 연쇄적으로 일어나기 때문에 새로운 데이터 학습시 이전에 학습한 정보를 까먹을 수 있음(Catastrophic forgetting) → 그래서 real-world에는 적용하기 어렵다.
- Continual Learning (CL) : Catastrophic forgetting를 다루는 방법으로, 지속적으로 데이터를 학습하면서도 이전에 학습한 정보를 잘 유지하는 방법
- 최근 연구는 테스트 단계에서 task identity가 필요한지 여부에 따라 분류할 수 있음
- Task-aware 접근 방법은 task identity를 명확하게 guide해주어 task 간 간섭을 방지
- 그러나 실제 추론할 때 task identity를 얻기 어려울 수 있음 → 따라서 task에 구애받지 않는 방법이 필요하다.
정리하면 아래와 같은 상황
1) 실제 산업환경에서는 높은 생산 성공률과 정보보호문제로 anomaly 데이터를 얻기 힘들고
2) 여러 태스크에 적용가능한 모델이 필요
3) supervised tasks에서 task-agnostic Continual Learning이 효과적임에도 불구하고 UAD에서 continual learning의 효과가 입증되지 않음
그래서 저자들은
Continual Learning을 활용한 Unsupervised Anomaly Detection을 하겠다!
고 제시
그런데 기존 연구가 없었냐, 하면
- Gaussian distribution estimator (DNE) (Li et al. 2022) 외에는 없었음
- DNE는 augmentation을 사용하여 pseudo-supervision을 제공, anomaly segmentation에는 적용할 수 없음
- Continual AD 방법보다는 Continual binary classification 방법에 더 가까움
- 실제 산업 제조 환경에서는 이상 영역을 정확하게 분할하는 것이 중요하기 때문에 Unsupervised Continual Anomaly Detection과 Anomaly Segmentation을 동시에 수행할 수 있는 방법이 필요함
그래서 제안한 내용은 새로운 프레임워크인 UCAD
- 하나의 모델로 다양한 클래스의 anomaly를 지속적으로 배울 수 있고, 그런데 unsupervised 방식임
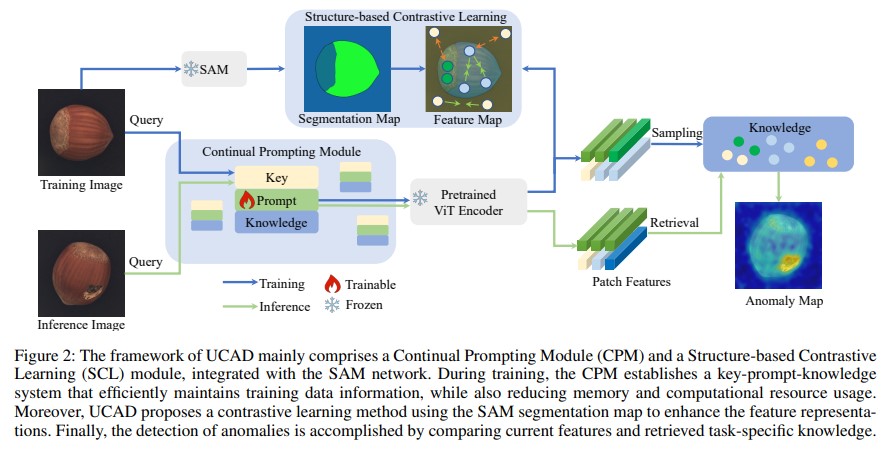
- 구성요소
- Continual Prompting Module (CPM)
- “key-prompt-knowledge” 메모리 공간 학습; 이미지가 주어지면, key는 자동적으로 상응하는 task prompt를 찾고, prompt를 바탕으로 feature를 추가로 추출하여 해당 클래스의 정상 정보와 비교하여 이상을 탐지
- 한계 : 고정된 백본 ViT가 다양한 task에서 충분히 압축된 feature representation을 제공하지 못한다는 한계가 있음
- Structure-based Contrastive Learning Module (SCL)
- CPM의 한계를 극복하기 위해, 즉 dominant feature representation을 추출하고 도메인 간의 차이를 줄이기 위해 도입
- SAM의 general한 segmentation 능력을 활용하여 영역 안의 feature들을 함게 묶고, 다른 영역의 feature와는 멀리 떨어지게 만듦, 이 과정에서 프롬프트가 더 나은 feature 추출을 위해 대조적으로 학습됨 (Contrastive Learning)
- Continual Prompting Module (CPM)
Contribution
- UCAD는 unsupervised anomaly detection과 segmentation에서 최초의 task-agnostic continual learning 프레임워크임
- Key-prompt-knowledge 메모리 공간을 통해 자동화된 작업 지시(task instruction), knowledge transfer, unsupervised anomaly detection및 segmentation을 수행함
- SAM의 일반적인 능력을 활용하여, 다양한 클래스에서 대조 학습된 프롬프트를 사용해 비지도 특징 추출 성능을 향상시킴
- 철저한 실험과 새로운 벤치마크를 도입하여, 이전의 최신 AD 방법들에 비해 15.6% 높은 detection 성능과 26.6% 높은 segmentation 성능을 보였음
Related Work - Industrial image Anomaly Detection
- 이건 그냥 흐름 파악용으로 정리
Unsupervised Image Anomaly Detection
MVTec AD dataset(2019) 공개와 함께, 지도에서 비지도 이미지 이상탐지로 패러다임 변화
Unsupervised anomaly detection 패러다임에서는, 테스트 데이터는 정상데이터와 이상 데이터로 구성, 반면 학습 데이터는 정상데이터로만 구성됨
Unsupervised Industrial Anomaly Detection 연구의 분류
- Feature-embedding-based methods
- Teacher-student model
- One-class classification methods
- Mapping-based methods
- Memory-based methods
- Reconstruction-based methods
- Autoencoder based methods
- GANs based
- ViT based
- Diffusion based
기존 UAD 방법의 한계
- single object category에서 anomaly detection
- Continual Learning scenario에서 anomaly detection 수행 능력 부족
- 심지어 multi-class unified anomaly detection 모델도 continual learning을 고려하지 않음
Continual Image Anomaly Detection
Natural image object detection task와 달리, 제조산업에서는 *데이터 스트림이 일반적이다.
💌 Datastream in Industrial manufacturing
제조 산업 환경에서 데이터를 한 번에 모아서 처리하는 것이 아니라, 데이터가 시간이 지나면서 점차적으로 계속 들어오는 경우가 많음
이러한 현상을 인식하고 다루기 위한 시도가 몇 있음
- IDDM (2023) : 레이블이 달린 데이터가 적은 상황에서 점차적으로 anomaly를 detection하는 방법
- LeMO (2023) : 레이블이 없는 정상 데이터가 지속적으로 증가하는 상황에서 정상데이터를 추가학습 할 수 있는 anomaly detection 방법
그러나 위 두 연구는 다른 추가 클래스의 추가학습을 고려하지 않음
DNE (Li et al. 2022)가 가장 저자들의 연구와 비슷한데, DNE는 continual learning 시나리오에서 이미지레벨로 수행하는 anomaly detection을 제안
근데 저자들의 연구와 뭐가 다르냐, 하면
DNE는 오직 클래스 레벨의 정보만 저장 가능하고, 이상 위치를 localization할 수 없음, 즉 anomaly segmentation에는 부적합하지만,
저자들의 연구는 ‘anomaly detection을 detection(이미지 분류)를 넘어 pixel-level의(segmentation) continual learning이 가능하다. ‘는 것
Methods
문제 정의 - Unsupervised Continual AD Problem
- 오로지 정상 데이터; 현실 생산 과정에서는 레이블된 이상 샘플을 얻기 힘들기 때문에
- 테스트 셋은 실제처럼 normal과 abnormal로 구성
- task n개에 각각 train set, test
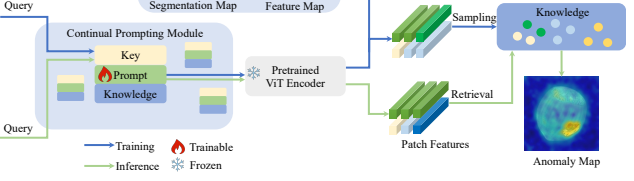
Continual Prompting Module
UAD에 CL을 적용하는 것은 두가지 어려움이 있음
1) 들어오는 이미지의 task identities를 어떻게 자동적으로 결정할건지
2) unsupervised manner로 관련 태스크의 모델 예측을 어떻게 가이드 할건지
⇒ CPM(Continual Promptin Module)은 (1) 동적으로 적용하고, (2) 모델 예측을 지시할 수 있음
Architecture
-
key-prompt-knowledge 아키텍처를 위한 memory space
-
task identification 단계와 task adaptation 단계로 구성
- Task Identification
- image 를 frozen pretrained ViT 통과, 추출된 feature를 key로 사용 → task identity가 됨
- 이때 task identity는 textual details과 high-level information을 동시에 가지고 있어야 하기 때문에, ViT에서 마지막 임베딩 레이어를 제외한 특정 i번째 레이어의 임베딩 feature를 사용 (논문에서는 i=5)
- 각 태스크 t에는 개의 학습 이미지가 있다고 가정하며, 추출된 모든 임베딩은 크기가 가 됨 → 많은 메모리 필요
- 테스트 동안 효율적인 태스크 매칭을 위해, 단일 feature space representing을 사용 → , 바로 윗줄과 비교했을 때 공간적 크기가 매우 작음
- FPS (Furthest Point Sampling) 기법 사용
- FPS는 관련성 있는 대표 feature를 선택하는 방법, 태스크 t에 대해 세트를 설정, 특정 태스크의 모든 임베딩을 대표함
- : 태스크 t에 대한 임베딩 벡터 중 대표 feature
- image 를 frozen pretrained ViT 통과, 추출된 feature를 key로 사용 → task identity가 됨
- Task Adaptation
- 각 레이어의 input feature에 태스크 정보를 전달하기 위한 프롬프트 가 더해짐 , 는 i번째 레이어의 output feature가 됨
- learnable prompts
- Knowledge : task transfer된 이미지 feature 는 Knowledge 을 생성하는 데 사용, 생성된 knowledge는 학습 중에 저장되고, 이후 normal과 abnormal을 비교하는 데 사용
- Core-set Sampling : 이미지 feature가 학습 중에 너무 많이 축적될 경우, Coreset Sampling을 사용하여 저장되는 정보의 양을 줄임
- M : 학습 중에 생성된 정상 이미지들의 특징, : Coreset으로 선택된 정상이미지들의 특징
- Task Identification
CPM은 이전 task의 지식을 현재 태스크에 성공적으로 transfer 가능, 즉 태스크 간 knowledge transfer 가능
문제점 : 백본이 natural image로 학습되었기 때문에, industrial image의 특정 구조와 특징을 충분히 반영하지 못할 수 있음 (industrial image는 주로 텍스처와 엣지 구조를 가지고 있음, 이미지들이 유사함)
→ 이를 해결하기 위해 structure-based contrastive learning을 통해 프롬프트가 다양한 태스크 간 feature를 더 잘 추출하고 학습할 수 있도록 함
Structured-based Contrastive Learning
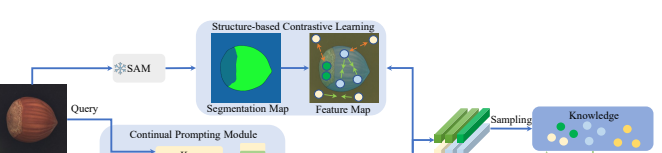
- SAM (Segment Anything Model)을 통한 Segmentation
- 학습 중 각 이미지에서 SAM을 사용하여 세그먼트화된 이미지 생성
- 동시에 프롬프트에 따라 각 영역에 대해 특징맵 획득
- 세그먼트화된 이미지 는 크기 로 다운샘플링되어 와 같은 크기로 조정되고, 해당 위치에서 레이블맵 가 생성됨
- 그리고 Contrastive Learning을 적용하여 동일한 영역의 feature는 가까이, 다른 영역의 feature는 더 멀어지게 학습
- Loss Function
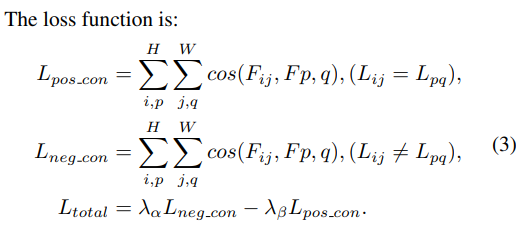 : 동일한 영역이 가까워지도록 하는 positive contrastive loss
: 동일한 영역이 가까워지도록 하는 positive contrastive loss
: 다른 영역이 특징들이 멀어지도록 하는 negative contrastive loss
Test-Time Task-Agnostic Inference
테스트 시에 추론
- Task Selection and Adaption
- 자동적으로 task identity를 결정하기 위해, 테스트 이미지는 가장 유사한 태스크에 선택됨 는 ViT의 i번째 레이어에서 추출된 패치 수준의 feature map을 나타냄
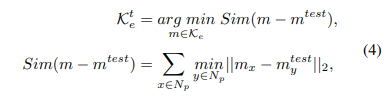
- 자동적으로 task identity를 결정하기 위해, 테스트 이미지는 가장 유사한 태스크에 선택됨 는 ViT의 i번째 레이어에서 추출된 패치 수준의 feature map을 나타냄
- Anomaly Detection and Segmentation
- anomaly score를 계산하기 위해서, image feature 와 에 저장된 정상(nominal) feature를 비교
- re-weighting 방식을 사용하여, 패치 수준에서 anomaly detection process 구현
- 이때 에 저장된 NN(Nearest Neighbors)를 사용하여 anomaly score 계산
- 구체적으로, 두 맵의 l2 norm을 사용하여 계산
- 얻은 NN으로부터 다시 re-weighting
- 각 패치에 대해 계산된 anomaly score 중에서 가장 높은 값이 해당 이미지의 anomaly score로 사용됨 → 즉 이미지 내에서 가장 이상하다고 판단된 부분이 전체 이미지의 anomaly score 결정
- 각 패치별로 계산된 점수를 모아서 대략적인 segmentation map 생성; 이미지의 어느 부분이 이상한지를 나타냄

Experiments and Discussion
Experiments setup
- Dataset
- MVTec AD (2019)
- VisA (2022)
- Methods
- CFA (2022)
- CSFlow (2022)
- CutPaste (2021)
- DNE (2022) - unsupervised continual AD SOTA method
- DREAM (2021)
- Fast-Flow (2021)
- FAVAE (2020)
- PaDiM (2021)
- PatchCore (2022) - 메모리, 통합 기반 대표적인 AD method
- RD4AD (2022)
- SPADE (2020)
- STPM (2021)
- SimpleNet (2023)
- UniAD (2022) - 메모리, 통합 기반 대표적인 AD method
- Metrics
- AUROC/AUC : anomaly classification
- AUPR/AP : 픽셀 수준의 anomaly segmentation
- FM : Forgetting Measure; 이전에 학습한 내용을 잊어버리지 않는 능력
Training Details and Module Parameter Settings
- Backbone : vit-base-patch16-224
- Trainig settings : batch 8, Adam, 25 epochs
- Key-Prompt-Knowledge : (15, 196, 1024), (15, 7, 768), (15, 196, 1024)
Continual anomaly detection benchmark
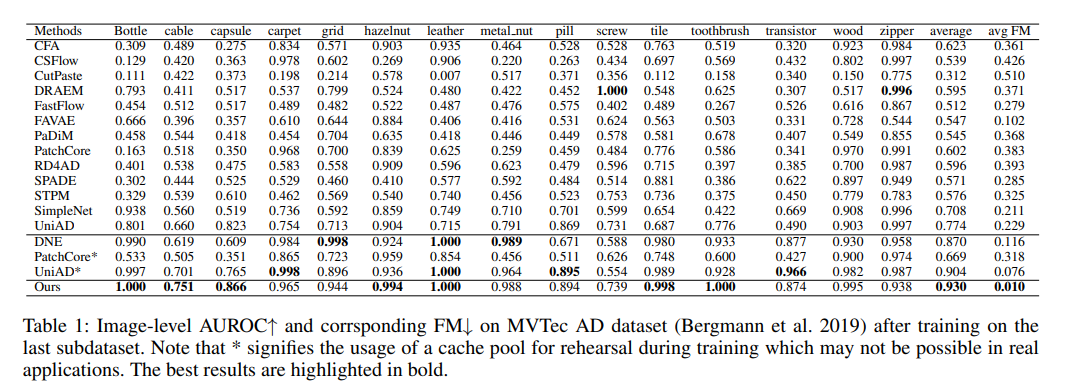
- AUROC, FM on MVTecAD
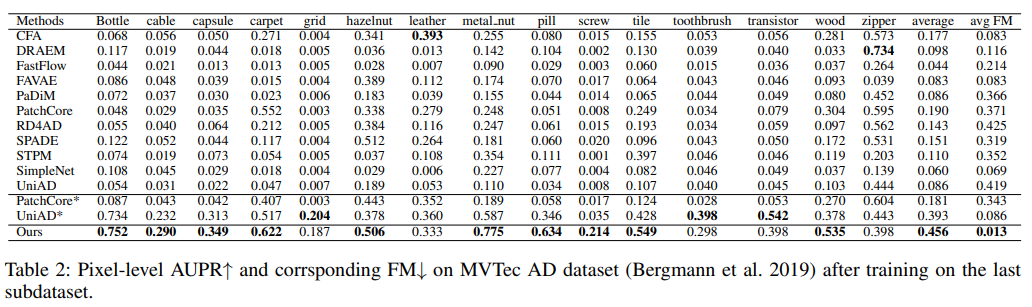
- AUPR, FM on MVTecAD
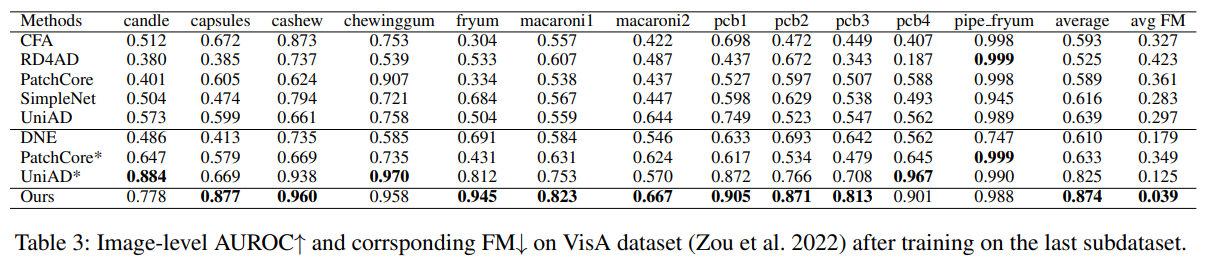
- AUROC, FM on VisA
- AUPR, FM on VisA
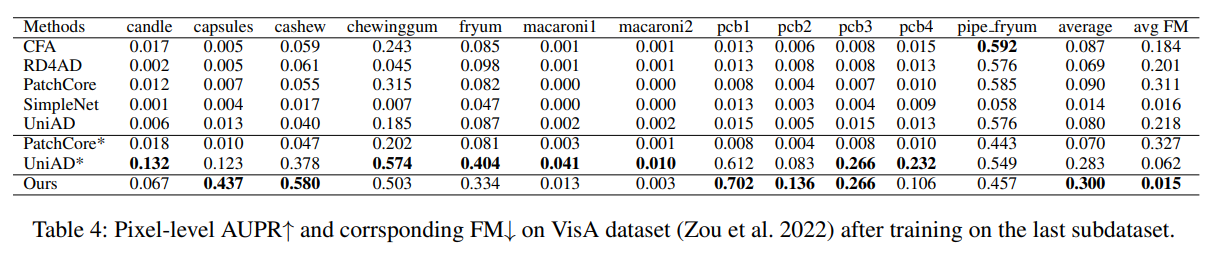
- 대부분의 anomaly detection 방법이 continual learning 시나리오에서 성능이 매우 감소
- 복잡한 구조를 가진 VisA 데이터셋에서, DNE의 탐지 능력은 클래스 토큰에 의존하는 방식 때문에 크게 감소한 반면, 저자들이 제안한 방법은 영향을 받지 않았음 (Table 1, 3, DNE AUPR average 0.870→0.610)
- PatchCore와 UniAD와 비교했을 때 장점
- 더 정밀한 anomaly localization
- False positive 최소화
Ablation study
-
Module Effectivity
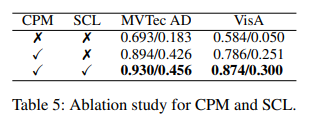
- SCL을 사용하지 않으면, 모델은 고정된 ViT 백본에만 의존하여 feature 추출, 성능에서 약 4 포인트의 감소
-
Size of Knowledge Base in CPM
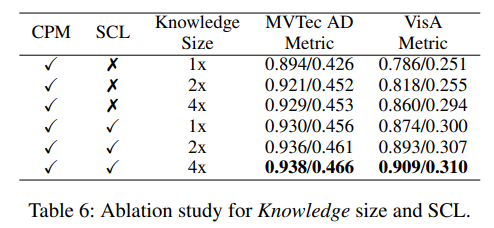
- 기본 knowledge base size는 196
- SCL을 사용하지 않는 경우 Knowledge Base size를 늘리면 성능 향상
- 반면 SCL을 사용한 경우 늘려도 성능향상이 거의 없었음
→ SCL이 특징 분포를 더 컴팩트하게 만들어 같은 크기의 knowledge base에 더 많은 정보를 압축할 수 있기 때문
-
ViT Feature Layers
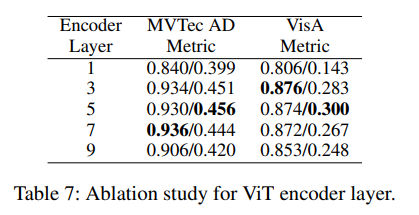
- 중간 레이어가 contextual 정보와 semantic 정보를 모두 표현할 수 있기 때문에 좋은 성능을 보임
- 데이터셋마다 요구되는 contextual 정보의 정도가 다를 수 있음
Conclusions
- 저자들은 Unsupervised Anomaly Setection에 Continual Learning을 적용하는 문제를 연구하여, Industrial Manufacturing과 같은 실제 응용 분야에서 발생하는 문제를 해결하고자 함
- Task-Agnostic CL을 최초로 UAD에서 segmentation도 같이 가능
