Ai competition
1.ai competition
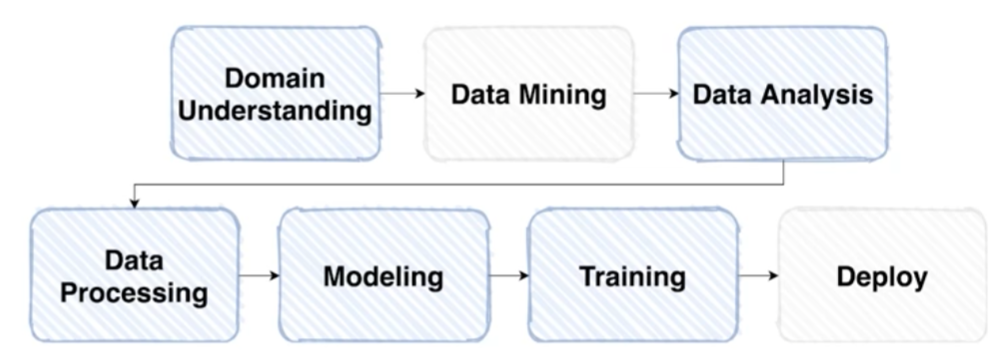
대회 시작하자마자 데이터 열어보지말고 overview check.탐색적 데이터 탐색. 데이터를 사용하여 이루고자 하는 목표 확인데이터 확인input, output 정의방법론 수립데이터 처리모델 생성반복
2.TIL train 계획 정리 2021.08.23

TIL 자체를 체계적으로 정리하지않고 카테고리별로 포스팅 후, 주간학습 정리에서 TIL을 간략하게 적었다.지식을 배울 때는 쓸모있는 방식인데 매일매일 해커톤과 같이 계속 코딩할 때는 매우 비효율적인 느낌이다. 대회가 진행되는 P stage에서는 TIL을 직접 적어야겠다
3.Preprocessing
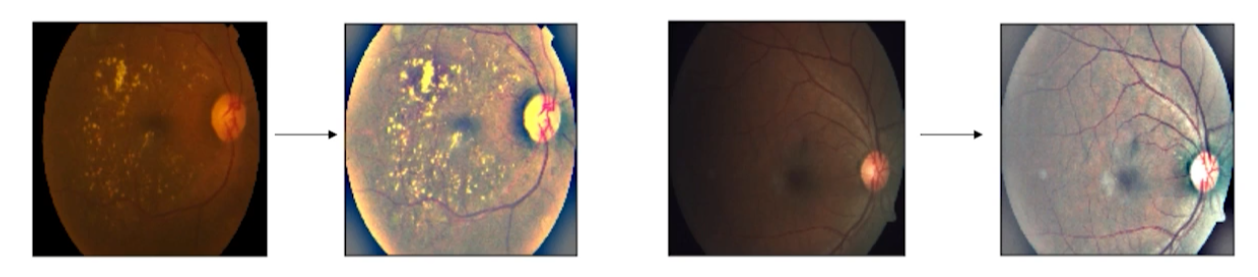
필요 이상의 정보를 거르자. 문제는 보통 그냥 이미지만 덜렁 주어진다는 것이다. 개발자가 알아서 적절한 방법을 찾아야한다.수업 때 배웠던 YOLO를 써도되고, 대부분 이미지 중앙에 마스크 사진이 있으니 중앙crop만 해도 되고... 이것저것 해봐야겠다.원본 크기로 계산
4.Data Generation
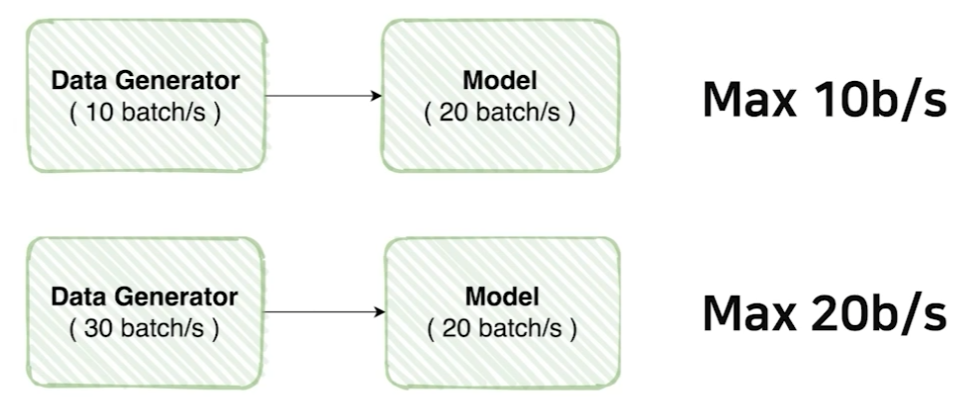
Data feeding을 잘해보자. 가령, 위처럼 코딩해놨다고 하자. 두 코드 모두 비효율적이다.첫번째는 generator의 속도가 model보다 느리기 때문에 model이 제 성능을 내지 못한다.두번째는 model의 속도가 generator보다 느리기 때문에 gene
5.TIL train 계획 정리 2021.08.24

학습 계획은 이전 TIL에 적은 그대로이긴하다. 다만 ensemble learning으로 학습할 방도가 떠오르지않아 일단은 단순 if문으로 처리했다.3개의 feature 조건에 따라서 18개 클래스가 결정된다. 일일히 if문을 18개 넣어도되지만, python iter
6.TIL 코딩 정리 2021.08.25~27
코딩, 검증에 정신없어서 기록을 하나도 못했다. 몰아서 정리해야겠다.conda가 dependency conflicts 측면에서는 압도적으로 좋다. 다만, 네이버 서버에서는 매우 느렸다. 대부분 conflicts가 발생했고 설치된 모든 파이썬 모듈에 대해서 conda가
7.부스트캠프 AI Tech 2기 4주차 학습정리
https://velog.io/@naem1023/series/Ai-competition학습 계획 수립: https://velog.io/@naem1023/TIL-train-%EA%B3%84%ED%9A%8D-%EC%A0%95%EB%A6%AC-2021.08
8.CutMix
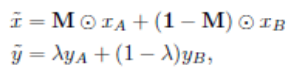
CutMix https://hongl.tistory.com/223 random crop보다 효과 있다는 CutMix를 사용하기로 했다. 구현 공식 레포: https://github.com/clovaai/CutMix-PyTorch pytorch implement 레포:
9.CutMix vertical
본래 cutmix는 랜덤하게 이미지 패치를 샘플링한다. 해당 방식이 마스크 이미지에선느 썩 효과적이지 못할 수도 있다. 마스크를 착용여부, 성별, 나이를 알기 위해서는 얼굴만 detection해서 patch를 하는것이 가장 효과적일 것이다. 따라서 랜덤하게 패치하고자한
10.헷갈렸던 training 방법
그 동안 헷갈리고 모호하게 알고 있던 내용들을 정리했다.이 순서가 맞다. 아래처럼 해도 모델이 input data에 대해서 학습을 하긴한다.문제는 validate 시점이 모든 trainig이 끝난 시점이라는 것이다. 즉, 최종적으로 학습이 끝난 모델을 다시 epoch만
11.Training proecss
gpu가 좋은 상황이 아닐 경우 사용할만한 방법이다. num_accum만큼의 epoch을 돌아야지 model의 parameters를 업데이트.critertion의 결과물에 num_accum을 나눠주는 이유는 일반화때문이라고 한다.뇌피셜: num_accum동안의 loss
12.Ensemble
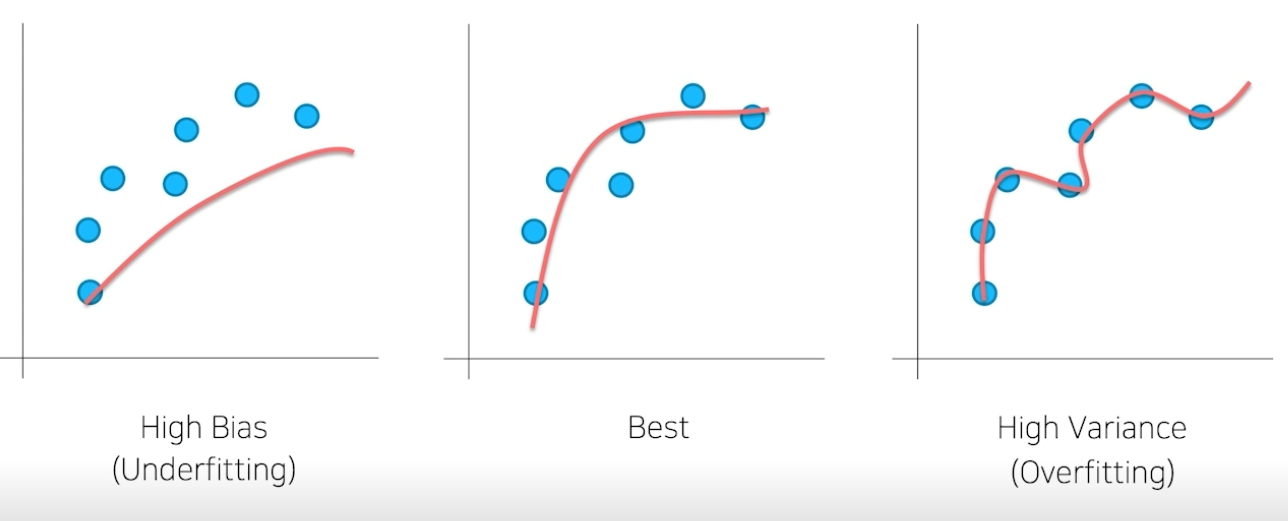
필드에서는 앙상블을 시도하기 위한 노력을 모델과 학습 파이프라인을 최적화시키는데 사용한다고 한다. 하지만 competition에서는 소수점 한자리 이하의 싸움이 있기 때문에 앙상블을 활용해서 점수를 올리는 것이 중요하다. 대부분의 모델들을 학습시켜보면 overfitti
13.마지막 점수 올리기
대회 막바지에 점수를 올리기 위해 사용했던 기법들이다. 극적인 성능 향상은 아니고 점수 굳히기 느낌이었다. ref: https://chacha95.github.io/2021-06-26-data-augmentation2/확정된 모델이 존재할 때 사용할 수 있는
14.Transformation(Albumentation)
속도, 다양성 면에서 pytorch 내장 transformation보다 좋길래 사용했다.가령, 아래와 같은 transformation을 학습에서 사용했다고 해보자.그러면 inference에서도 아래와 같이 동일 구성의 크기 조절, crop, normalization을
15.첫번째 Ai Competition 마무리
2주간의 짧은 시간이었지만, 계속 밤을 샜던지라 4주와도 같았던 시간이었다. 그 동안 시도했던 내용들, 다른 사람들이 사용했던 방법들을 정리해봤다.실험을 위해 구현했던 개인 코드: https://github.com/naem1023/boostcamp-pstage
16.Kaggle tip
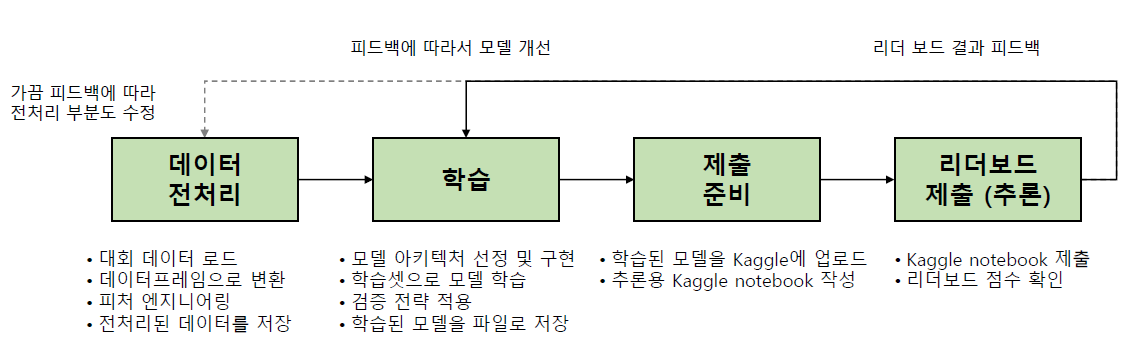
경진대회 플랫폼 Kaggle 카카오 아레나: 계열사 전용이라고 한다. 데이콘: public 대회. Kaggle 스타일이 적용되는 중이라고 한다. Ranking Ranking system: competition 내의 point로 정해지는 순위 팀을 이뤄 출전하면 $
17.Kaggle dataset
kaggle notebook을 안쓰고 개인 서버에서 train 해보려면 kaggle dataset을 전부 서버에 받아야한다. 대회에서 제공해주는 train/test 파일들만 쓴다면 kaggle api를 쓸 필요까지 없다.하지만 discussion에 올라온 여러 code