대회 막바지에 점수를 올리기 위해 사용했던 기법들이다. 극적인 성능 향상은 아니고 점수 굳히기 느낌이었다.
TTA(Test time augmentation)
ref: https://chacha95.github.io/2021-06-26-data-augmentation2/
확정된 모델이 존재할 때 사용할 수 있는 방법이다.
확정된 모델에 대해 각종 augmentation이 적용된 이미지를 개별적으로 넣어서 나온 출력을 ensemble하는 방법론이다.
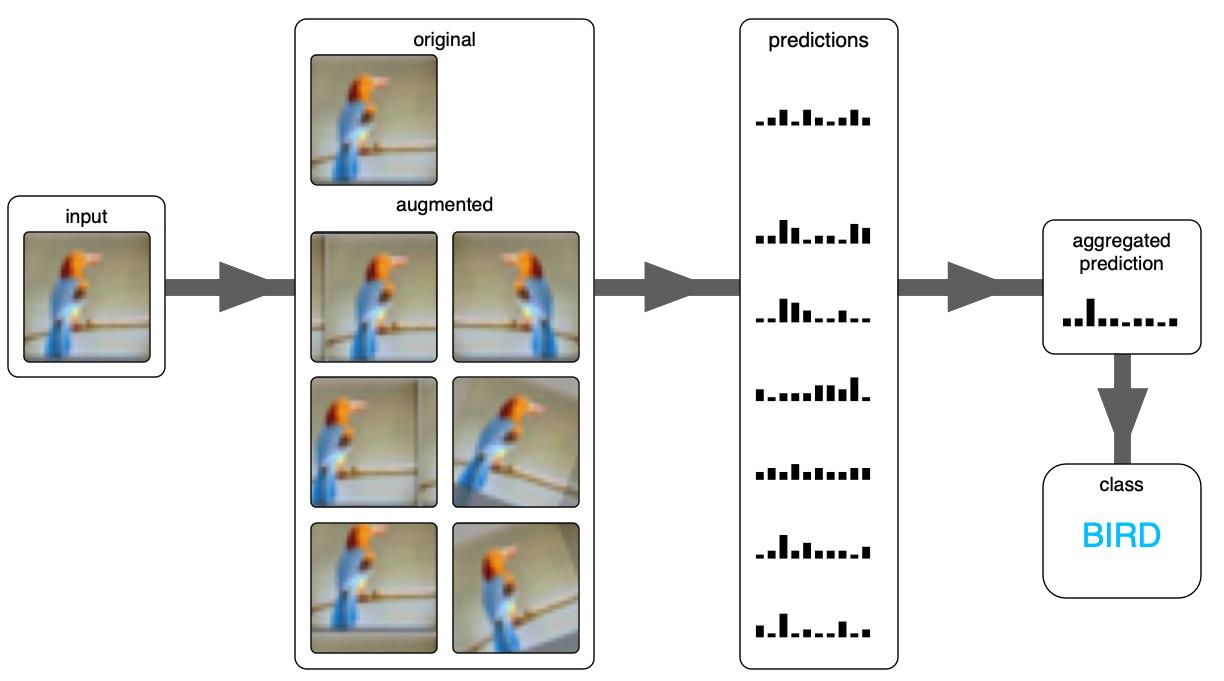
여러 출력을 ensemble하는 방법은 자유롭게 정한다. 보통은 soft voting을 사용한다고 한다. 여러 방법을 사용 가능한데 굳이 soft voting을 사용하지 않을 이유가 없다. soft voting이 hard voting에 비해 overfitting을 방지하면서 성능향상을 노리기 더 좋기 때문이다.
하지만 꼭 soft voting이 만능해결법은 아니다.
ref: https://devkor.tistory.com/entry/Soft-Voting-%EA%B3%BC-Hard-Voting
어떤 class에 대한 probability 가 일정 값보다 큰 모델들만 따로 모아서 이들에 대해서만 Hard Voting 을 진행한다.
위의 예시가 hard voting을 사용하는 전형적인 예라고 한다.
Soft voting 구현
다양하게 구현할 수 있는데 내가 본 예시는 다음의 두 가지다. 모듈을 굳이 찾아보진 않았는데 모듈을 쓰는 것보다 구현하는게 더 빠를 것 같았다.
- validation 단계에서 batch image에 대해 n개의 augmentation을 적용해서 나온 각각의 출력들이 이라고 하자. 그러면 단순하게 n개의 tensor들을 더해주고 n으로 나눠준다.
- transoformation을 정하고, 모델과 dataset, dataloader를 만들어 validation을 하는 과정을 하나의 파이프라인으로 만들어져 있다고 하자. 이러한 파이프라인에 대해 동적요인으로 transformation을 줘서 여러 파이프라인에 대한 출력을 구하고 class index에 대해 평균을 구한다.
난 2번째 방법을 택했는데, 구현의 편의성이나 간결성을 고려하면 첫번째가 압도적으로 편하다. 구조상 어쩔 수 없이 두번째를 택했다.
Half precision
이건 적용이 된지 모르겠다. batch size가 2배정도 늘어나야 정상인데 40에서 50으로밖에 안 늘어난다거나 이전과 동일한 경우가 허다하다. 속도는 그대로인거 같고.. 뭔가 docs에서 하라는대로 적용은 했는데 하나도 안된다. nightly에서만 제대로 적용되나 싶었서 nightly로 설치해봐도 안되더라.
적용만 제대로 된다면, 학습의 초창기부터 적용해도 좋을 기법이다. 부동소수점은 16비트로 써서 학습속도와 batch size에서 2배 이상의 이득을 볼 수 있다고 한다.
대회 막바지에 알게되서 이 포스팅에 넣었다.
