필드에서는 앙상블을 시도하기 위한 노력을 모델과 학습 파이프라인을 최적화시키는데 사용한다고 한다. 하지만 competition에서는 소수점 한자리 이하의 싸움이 있기 때문에 앙상블을 활용해서 점수를 올리는 것이 중요하다.
Ensemble
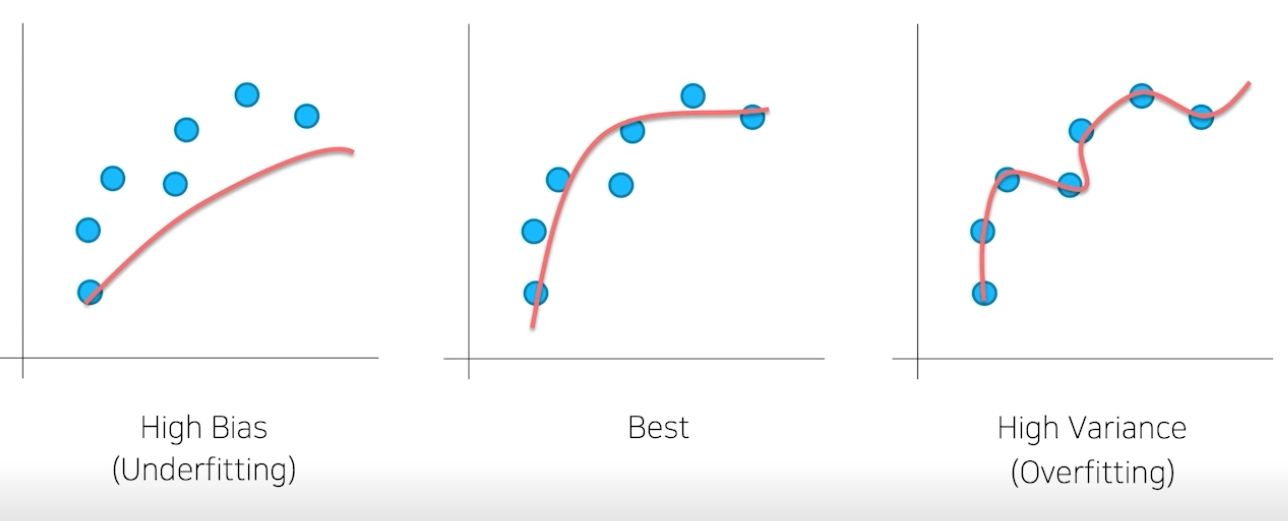
대부분의 모델들을 학습시켜보면 overfitting이 빈번하기 발생한다. 물론 데이터가 너무 작고 편향돼서 underfitting이 발생할 수도 있지만 흔한 경우는 아니다.
아래 그림을 보면 이해가 편할 것이다.
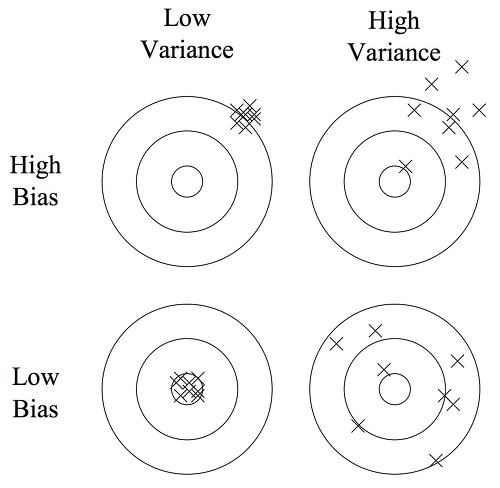
ref: https://bywords.tistory.com/entry/%EB%B2%88%EC%97%AD-%EC%9C%A0%EC%B9%98%EC%9B%90%EC%83%9D%EB%8F%84-%EC%9D%B4%ED%95%B4%ED%95%A0-%EC%88%98-%EC%9E%88%EB%8A%94-biasvariance-tradeoff
Voting
ref: https://devkor.tistory.com/entry/Soft-Voting-%EA%B3%BC-Hard-Voting
- Hard voting: majority class를 선발
- Soft voting: class 간의 평균을 출력
- Weight voting: model의 출력에 각각의 weight를 곱해주고 weight의 합으로 나눠준다.

https://github.com/naem1023