정리
학습 계획은 이전 TIL에 적은 그대로이긴하다. 다만 ensemble learning으로 학습할 방도가 떠오르지않아 일단은 단순 if문으로 처리했다.
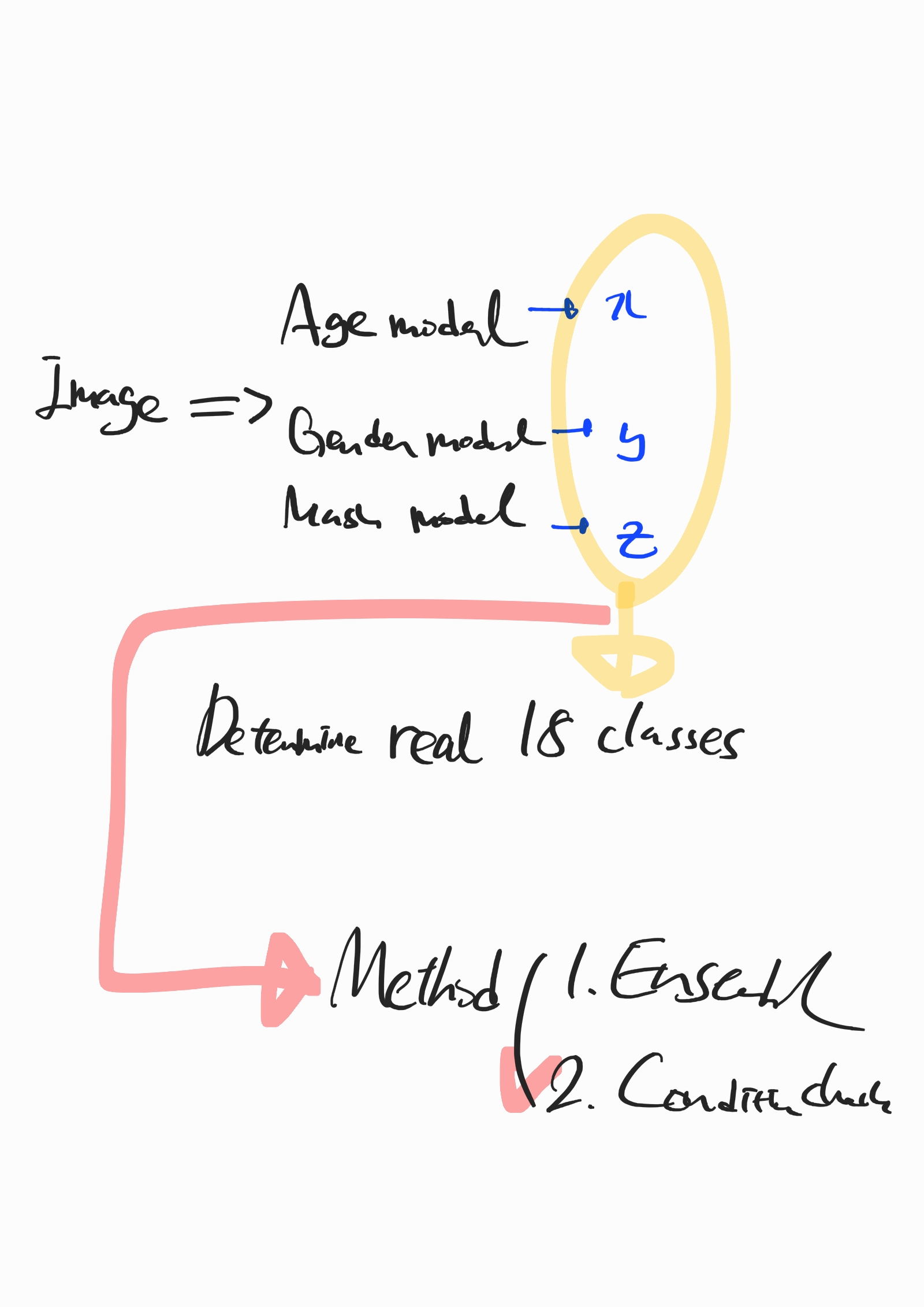
3개의 feature 조건에 따라서 18개 클래스가 결정된다. 일일히 if문을 18개 넣어도되지만, python itertools의 product를 써서 해결했다.
mask = [0, 1, 2]
gender = [0, 1]
age = [0, 1, 2]
label_number = list(product(mask, gender, age))전제조건은 3개의 featuer와 class 번호가 오름차순이어야한다는 것이다. 다행히 그랬다. 3개의 model에서 나온 출력을 label_number에 대조시켜서 최종적인 class를 얻으면된다.
그림으로 표현하면 다음과 같다.!
Ensemble learning
- Bagging(parallel): 동일한 출력을 가진 모델을 사용한다고 해보자. 이 모델과 동일한 구조를 가진 여러 모델이 동일 데이터 셋에서 반복 추출하여 학습하는 행위(Bootstrap Aggregation)를 여러번 반복한다. 같은 데이터셋이라도 표본을 여러번 뽑으면 학습 효과가 증가한다고 한다.
- Boosting(sequential): 서로 다른 모델을 활용한다고 한다. 이전 모델의 결과를 다음 모델 학습 시, 데이터에 가중치를 부여하는 방식으로 재활용하여 사용한다고 한다.
두 방법의 사용은 왕도가 없다고 한다. 도메인과 문제에 적합한 방법을 사용하자.
- Boosting은 Bagging에 비해 error 적다.
- Boosting은 학습 속도가 느리고 overfitting될 가능성이 높다.
- 모델의 낮은 성능이 문제다 -> Boostring으로 해결해보자.
- Overfitting이 문제다 -> Bagging으로 해결해보자.
모델 변경
https://paperswithcode.com/sota/image-classification-on-imagenet
참고한 cnn 랭킹.
- 기존: resnet18, 학습속도가 매우 빨라 테스트 용도로 용이
- efficientnetb7: epoch=5, kfoldsplit=2로도 9위를 찍었다! 하지만 매우 느리다. 안전하게 사용할 수 있는 최저선이라고 생각하자.
- volo: 성능이 매우 좋다고 했지만 model의 output이 이상하게 나와서 못 써먹었다. 랭크표에서 성능이 매우 좋았는데 아쉽다.
- CaTi: ViT의 일종이라고하는데 pretrained 모델이 없어서 accuracy가 38%로 나왔다..;;
- BiT: Google에서 transformer로 만든 Image Classification이다. 이것도 순위권에 있길래 시도 중이다.
계획
일단 efficientnet을 epoch, kfoldsplit을 늘려서 학습해보자.. 8시간이 날라갔다 ㅠ

https://github.com/naem1023

헤으응 성호쿤 굉장해요오옷