2주간의 짧은 시간이었지만, 계속 밤을 샜던지라 4주와도 같았던 시간이었다. 그 동안 시도했던 내용들, 다른 사람들이 사용했던 방법들을 정리해봤다.
최종 결과물
실험을 위해 구현했던 개인 코드: https://github.com/naem1023/boostcamp-pstage-image
내가 만든 모델을 통해 5위를 한 것도 너무 좋았고 그 과정에서 팀원들과 밤새면서 함께 코딩하고 실험했던 경험들이 소중했다. 교외에서 한번도 협업하면서 함께한다는 기분을 느낀 적이 없었는데, 비즈니스적인 협업 외의 끈끈함을 느낀 것은 이번이 처음이었다.
public data로 채점했을 때는 10위라 졌잘싸 분위기였다. private data까지 포함된 최종 순위에서 확 올라서 우리 조는 축제 분위기였다.
public data와 private data 간의 f1 score의 변화가 없었던 것을 보면 robust한 모델을 구현하는 것에 신경 쓴 것이 효과가 있었던 것 같아 좋았다.
대회 개요
18개 class는 mask(3개 class), gener(2개 class), age(3개 class)로 구성된다. 학습 데이터를 기준으로 18개 class에 대한 classifier를 만들고 이를 submission.csv로 제출해서 채점한다.
학습 계획
첫번째 학습계획: https://velog.io/@naem1023/TIL-train-%EA%B3%84%ED%9A%8D-%EC%A0%95%EB%A6%AC-2021.08.24
첫번째 학습계획: https://velog.io/@naem1023/TIL-train-%EA%B3%84%ED%9A%8D-%EC%A0%95%EB%A6%AC-2021.08.24-xuou0hx5
처음에는 단순하고 모호하게 Ensemble을 하고자 생각했는데 어떤 방식으로 해야될지 계획조차 짜지 못했다. 팀원들에게 피드백을 받아서 정돈된 모델 학습 계획을 세우고 해당 방법론이 후의 모든 학습 방법에 대한 토대가 됐다.
학습 파이프라인
ref: https://github.com/victoresque/pytorch-template
해당 템플릿을 활용해서 코드를 구성해보려 했다. 추상화를 완벽하게 해서 가령 BaseTrainer를 상속받아 팀원들이 각자 새로운 Trainer를 만드는 형태로 프로젝트를 구성하려고 했다. 물론 이렇게는 안되고 OOP를 사용한다는 것 자체에 의의를 두게 됐다.
config
config.py에 관련 설정들을 해두고 train.py를 실행시키면 알아서 학습하도록 구성해보려고 했다. 본래 config.json을 구성하고 이에 맞춘 parser를 구성하는 것이 맞다. 하지만 parser를 만드는 수고를 할 시간에 빨리 모델을 돌려보며 여러 실험을 하고 싶었다.
config.py에 변수 형태로 여러 configuration 값들을 설정하고 python 문법을 활용해서 configuration을 구성해두는 것으로 간단하게 해결했다.
Backbone model
여러 시도를 했고 그에 대한 결과들을 다음과 같다.
- 실험을 위한 모델(Resnet18, efficientnet-b2)
- Augmentation, cutmix 등의 여러 방법들을 실험할 때 빠르게 결과를 내기 위해서 사용했다.
- 재밌는 점은 cutmix 적용 이후부터는 resnet18에서 성능이 너무 별로였다. f1 score 기준으로 대체로 0.6후반 0.7초반이 형성이 됐는데 여러 cutmix 기법을 사용했을 때의 차이점을 알기가 어려웠다. 가령, cutmix를 기존 방식대로 vertical하게 잘라보되 lambda의 비율은 random으로 줄지말지를 결정했을 때의 차이가 resnet18에서는 드러나지 않았다.
- 더 큰 모델에서는 cutmix 기법에 따라서 결과의 차이가 제대로 나타나서 대회 2주차부터는 efficientnet-b2를 통해 실험했다.
- 검증을 위한 모델(Efficientnet-b7)
- Efficientnet-b4를 사용하고자했으나 소수점 3자리 차이로 b7이 더 좋은 결과들을 내서 b7 위주로 검증을 했다.
- 1, 2위 조의 사용모델들은 efficientnet-b0, resnet152이었다.
Augmentation
Albumentation을 시도: https://velog.io/@naem1023/Preprocessing
Transformation 정리:
속도도 매력적이었지만 다양한 transformation을 제공해준다는 점에서 Albumentation을 사용했다. 매우 좋았다.
주의해야될 점은 pytorch의 transformer와는 다르게 반환형이 dictionary다.
전처리
Face crop
마스크, 나이, 성별에 관한 학습이기 때문에 배경을 날려버리는 것이 중요하다는게 우리 조의 정론이었다. 따라서, 얼굴만 자른 데이터셋을 만들어보자는 의견이 있었고 해당 데이터셋을 조원분께서 구해주셔서 사용했다.
1, 2위는 오히려 Face crop을 안했다고 했다. ???
내 생각에는 모델이 사진에서 사람의 형태를 찾는 것은 다소 쉬운 task에 해당하기 때문에, 굳이 배경을 날려버릴 필요가 없는 것 같다.
transformation
https://velog.io/@naem1023/TransformationAlbumentation
따로 정리한 글이 있는데, 이대로 했다. 요점은 강한 augmentation을 통해서 되도록 robust한 모델을 구성하고자 한 것이다. 데이터의 수가 많지 않았기 때문이다.
Label 기준 변경
age에 대해서 데이터들의 기준을 바꿨다. 대회는 30세, 60세를 기준으로 age를 3 그룹으로 나눠서 최종적인 18개의 class를 도출하는 것이 기본 가이드였다. 하지만 데이터 자체가 매우 불균형해서 해당 기준대로 데이터를 사용하면 학습이 거의 안된다.
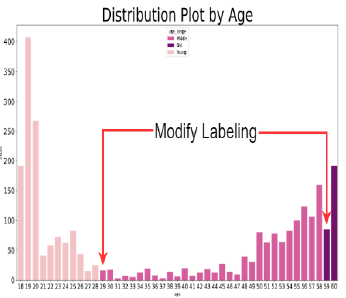
- 30~60세 사이에서 30세 부근에는 매우 적은 사람만이 30세~60세 그룹에 들어간다.
- 60세 이상의 그룹은 다른 그룹에 비해서 사람이 너무 적었다.
이러한 문제점을 age class의 기준점을 바꾸는 것으로 해결해보려했다.
- 30세~60세 그룹의 데이터 수를 조금이나마 늘리기 위해 30세가 아닌 29세를 기준점으로 삼았다.
- 60세 이상에 해당하는 그룹의 데이터 수를 늘리기 위해 60세가 아닌 59세를 기준점으로 삼았다.
Feature 분할
다행히 우리 조는 대회 첫날부터 이 이슈가 나왔다.
대회는 mask, age, gender라는 feature를 사용해서 임의의 이미지를 18개의 class로 분류하는 문제다. 하지만 feature들 간에 상관관계도 없거니와 인과관계도 없다는 의견이 나왔다. 내가 생각해도 정론이었다.
우리 조에서는 내가 feature를 분할해서 학습을 진행하고 다른 분들이 모든 feature를 한꺼번에 학습시켜봤다. 결과적으로 feature를 분할해서 학습시킨 것이 소수점 2자리에서 미세하게나마 성능이 좋았다.
물론 대회이기 때문에 이 차이는 매우 컷지만, 인과관계가 없는 feature를 분할하는 것이 큰 효과가 있다고 말할 수는 없었다. 내 생각에는 모델의 크기가 보통 크기때문에 mask, gender, age의 feature를 모델이 알아서 한꺼번에 학습했던 것 같다. 즉, 인과관계가 없지만 하나의 모델이 parallel하게 여러 feature를 동시에 학습한 것이라고 생각한다.
Label smoothing
우리조는 해당 방법론을 적용하니 되려 성능이 나빠졌다. 1, 2위조는 사용했다고 하니 적용 방법에 문제가 있었던 것 같다.
Validation set 구성
우리조에서 약간 등외시한 사항이다. 어차피 대회 웹사이트에 csv를 제출하면 채점이 되서 확인 가능하니 굳이 할 필요가 있냐는 것이다.
지금 생각해보면 정말 정말 잘못된 생각이다. 왜냐하면 여러 학습 기법들은 validation set에 대한 평가지표를 활용해서 판단을 하기 때문이다. 즉, 올바르게 구성되지 않은 validation set은 쓰레기다.
물론 validation set 자체는 model paramter update 과정에 관여하지 않기 때문에 validation set을 잘못 구성한 것이 학습이 잘 안된다는 것과 동일한 의미는 아니다. 하지만 앞서 말한 이유들 때문에 반드시 제대로 구성해야된다.
구성 방법
- train, test set에 동일한 사람이 존재하지 않도록 한다.
- 대회에서 제공해주는 파일들은 mask 5장, normal 1장, incorrect 1장으로 구성된다. 이 때, 7장의 사진이 train, test set에 산개한다면 같은 사람이 train과 test에 2번 이상 등장한 것이다. 즉, 해당 사람에 대해서는 당연히 validation 점수가 높을 것이고 이는 평가지표에 방해요인이 된다.
- train, test set에 동일한 class 분포를 형성해줘야 한다.
- 대수의 법칙에 따라 매우 많은 데이터를 임의로 분리하면 두 데이터 set의 분포는 동일한 분포를 가질 것이다. 하지만 대회의 학습 데이터는 그 정도로 충분히 많지 않기 때문에 동일한 class 분포를 가지도록 조정해야 할 것이다.
Loss function
더 적은 데이터 분포에 더 많은 가중치를 부여해주는 focal loss를 썻고, 이는 다른 조들도 매우 일관되게 공통되는 사항이었다.
다른 점은 1, 2위는 f1 loss를 사용했다. loss.backward()를 하고 optimizer.step()으로 parameter를 업데이트하기 전에, loss 값에 f1 score를 더해주는 것이다. 즉, loss function이 f1 score를 줄이는 방향으로 움직이도록 유도하는 것이다.
CutMix
화두의 그 CuiMix다. 오히려 1, 2위는 cutmix를 안 썻더라. cutout을 썻다.
우리 조의 CutMix 적용기는 아래 링크에 있다.
https://velog.io/@naem1023/CutMix
https://velog.io/@naem1023/CutMix-vertical
Datasampler
Dataloader에서는 sampler를 지정할 수 있다. 나는 train, test set을 분리할 때, RandomSampler를 사용했다.
다른 조는 pytorch 공식 제공 라이브러리 외에 imbalancedDatasetSampler를 사용해서 불균형 데이터에 대해서 어느 정도 균등하게 만들어주는 sampler를 사용했다고 한다.
One hot vector?
대부분 One hot vector를 통해 multi label classification을 진행했지만, 2위조는 사용하지 않았다고 한다. 모든 class에 대한 출력단의 독자적인 확률을 가지도록 출력단에 sigmoid를 통과시켜서 모델을 구성했다고 한다. 물론 이 중 가장 높은 확률을 가지는 하나의 class를 활용하는 것은 One hot vector를 구성해나가는 과정과 같이 torch.argmax를 썻다.
Psuedo labeling
화두의 그 방법이다. 우리조는 Dacon 등 여러 국내 대회에서 test set의 사용 자체를 금지한다는 것을 알았기 때문에 고려도 안했던 방법이다. 나중에 부스트캠프 대회 규정을 살펴보니 test set을 활용해도 무방하다고 했더라. 몰랐다...
test set data나 인터넷에서 크롤링한 이미지와 같이 unlabeled data를 학습 데이터로 활용하기 위한 방법론이다. 모델이 학습을 진행해서 inference을 할 수 있으면, 해당 모델을 통해 unlabeled data를 labeling해서 학습 데이터로 사용하는 방법이다. 즉, 기존 모델의 학습 방향을 강하게 강화시키는 역할을 한다.
물론 도박에 가까운 방법론이다. 왜냐하면 기존의 모델 학습 방법이 옳다는 보장이 없기 때문이다. 물론 이번 대회와 같이 대회 막바지에 상위권을 향하는 모델이 만들어진다면 매우 유용한 방법이다.
1, 2위와의 f1 score이 0.01차이였는데 수도 라벨링의 유무가 제일 컷던 것 같다.
TTA
대회 마감 하루 전에, 내가 제출했던 최고 모델에 대해서 0.7665를 0.7666으로 만든 방법론이다. 결과처럼 획기적인 성능 향상 방법은 아니고 약간 점수 굳히기 용도로 사용했다.
후기
생각보다 놓친 방법론이 너무 많았다. 특히 validation set 구성은 치명적이었다.. 결과는 좋았지만 회사에서는 결코 하지 않을 방법들이다. 성적이 잘 나와서 좋은 점도 있지만, 그 만큼 놓쳤던 많은 방법들을 remind할 수 있는 기회였다.
