CutMix
https://hongl.tistory.com/223
random crop보다 효과 있다는 CutMix를 사용하기로 했다.
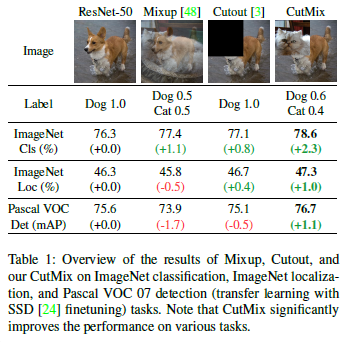
가령, crouput은 개의 얼굴을 그대로 날려버린다. CutMix는 개의 얼굴부분에 고양이를 붙여서 학습하겠다는 것이다.
- 목적: 를 와 결합하여 robust하고 성능이 좋은 모델 생성.
- 결합 방법: 만큼의 결합비율을 사용한다. 결합비율은 아래와 같이 사용된다.
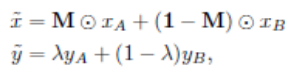
- , normalized했기 때문이다.
구현
공식 레포: https://github.com/clovaai/CutMix-PyTorch
pytorch implement 레포: https://github.com/hysts/pytorch_cutmix
implement repo의 cutmix.py와 train.py를 보면 감이 잡힌다.
loss
cutmix를 dataloader에서 collate_fn으로 사용하면 dataloader의 라벨 출력은 두 tensor가 나온다. 첫번째는 원래 라벨이고 두번째는 random shuffle되어 원래 이미지에 patch된 이미지의 라벨이다.
cutmix를 거친 이미지 tensor와 두 라벨 tensor에 대해서 각각 loss값을 구한 후 lambda와 1-lambda만큼 가중치를 부여주해주면된다.
pytorch implementation을 보면 cross entropy를 쓰고 있다. 자유롭게 criterion을 변경할 수 있게 돼있으니 바꾸고 싶은대로 바꾸자. 나는 데이터에서 class 불균형이 심해서 focal loss를 쓰고 있다.
평가지표
accuracy, loss
accuracy는 위 수식에서 lambda를 사용해 y hat을 구한 것과 같이 구하면 된다. 실제로 그만큼의 비율이 사용됐기 때문이다.
loss도 마찬가지로 crossentropy를 통과시킨 값에 대해서 위와 같은 수식을 적용시켜주며된다. 이뉴는 accuracy와 동일.
f1 score
보통 sklearn에 y와 predicted_y를 함께 넘겨줘서 계산한다. predicted y는 이미 준비돼있지만 y의 경우가 문제다.
CutMix를 Dataloader의 collate function으로 구현됐는데, 원본 y와 shuffled y를 각각 1개씩 받도록 설정돼있다. 즉, dataloader를 통해 받은 y는 2개의 y set으로 구성돼있고 다른 지표들(accuracy, loss)은 lambda와 (1-lamda)를 두 결과에 각각 곱하고 더해서 하나의 scalar 지표를 얻는다.
f1 score도 batch 단위로 새롭게 구해지는 lambda를 활용해 f1 score를 구하자.
(origin f1 score) lambda + (random shuffle f1 score) (1 - lambda)
batch 별로 구하고 하나의 epoch에 대해서는 batch f1_score들의 평균을 구해 사용하자.
