
지금까지 Unity를 이용하여 원하는 카메라 화면의 일부를 추출하였고, 추출과 LiDAR를 동시에 실행하는 것 까지 진행했다. 이번에는 추출된 이미지를 Classification model을 사용하여 분류하는 작업에 대한 내용이다.
먼저 Unity에서 classification model을 사용하기 위해 Barracuda package를 사용하였다. 그리고 MobileNetv3에 custom dataset을 이용하여 학습한 후 onnx 파일로 출력하여 unity에 적용하였다.
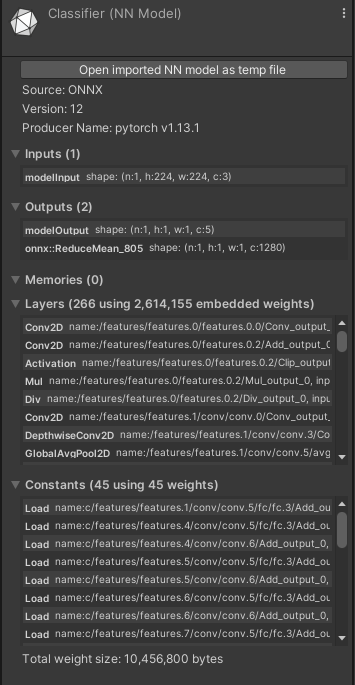
using Unity.Barracuda;로 Barracuda를 적용하고
// Barracuda를 이용하여 사용할 model 선언
public NNModel classification;
public Model model;
public IWorker engine;위 코드를 이용하여 Model을 사용하기 위한 기본 선언을 해준다.
label에 대한 정보는 '\n'을 기준으로 class를 분리한 text파일에 들어있으며 classs는
bus
car
motorcycle
train
truck
총 5가지로 이루어져 있다.
label에 대한 내용은
public TextAsset labelAsset;
private string[] labels;
// 화면에 text를 출력하기 위한 선언
public TextMeshProUGUI lab;을 이용하여 선언하였다.
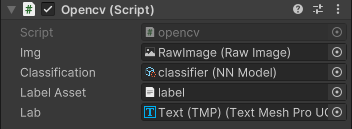
최종으로 script에 다음과 같이 적용하였다.
Model을 적용하기 위한 코드는
private void Awake()
{
// 화면에서 추출할 위치 지정
int width = Screen.width;
int height = Screen.height / 3;
// 화면 정보를 담을 공간 마련
tex = new Texture2D(width, height, TextureFormat.RGB24, false);
// '\n'으로 분리된 label text값을 split
labels = labelAsset.text.Split('\n');
model = ModelLoader.Load(classification);
// 모델을 수행할 device 설정
WorkerFactory.Device device = WorkerFactory.Device.CPU;
engine = WorkerFactory.CreateWorker(model, device);
}
private void ExecuteML(Texture2D inputTexture)
{
int bestIndex = 0;
float bestValue = 0;
Tensor inputTensor = new Tensor(inputTexture, 3);
engine.Execute(inputTensor);
var output = engine.PeekOutput("modelOutput");
// 가장 큰 값을 가지는 label 도출
for (int i = 0; i < 5; i++)
{
if (output[0, 0, 0, i] >= bestValue)
{
bestIndex = i;
bestValue = output[0, 0, 0, i];
}
}
// 화면에 classification 결과 label 출력
lab.text = labels[bestIndex];
//Debug.Log(labels[bestIndex]);
}위와 같다.
처음 object detection을 이용하려 하였으나 iPad에서 실행시키니 화면의 딜레이가 너무 심해서 classification을 사용하였다.
그러나 현재 동작은 되지만 아직 해결해야할 문제점들이 있다.
- 여전히 존재하는 화면 딜레이
- 임시로 적용한 classification model의 정확성 문제
- 최적의 화면 추출 위치 설정
- LiDAR point 위치 및 data 활용 방법 고안
위 문제를 지속적으로 해결해 나갈 예정이며 classification의 결과 사진을 마지막으로 이번 글을 끝내고자 한다.


꾸준히, 열심히, 즐겁게