데이터 분석
1.신뢰, 이해, 반복 가능한 분석을 위한 체크리스트

데이터 블로그 챌린지: 데블챌 2기 1일차똑같은 분석을 해도 조직에서 의미있는 '차이'를 만드는 분석은 어떤걸까?신뢰할 수 있는 분석데이터 분석은 분석 그 자체로 끝나는 것이 아니라, 상대방(고객)을 설득해야한다. 데이터는 신뢰로운지? 올바른 통계적 기법이 사용되었는지
2.분석 목적을 고려하여 RFM 기준을 세우는 방법
RFM 분석은 대표적인 고객 세분화 분석 방법이다. 그런데 처음 고객 세분화 분석을 할 때, R, F, M 각각의 기준을 어떻게 잡아야 할지 고민이었다. 이와 관련하여 좋은 글이 있어서 읽어보았다.출처: 데이터리안, RFM 고객 세분화 분석에서 합리적으로 기준을 잡는
3.진입률과 전환율, 두 가지 퍼널 최적화 전략
퍼널 분석을 배우면서 퍼널 최적화에 대해 관심이 생겼다. 마침 딜라이트룸에서 데이터 분석 사례를 시리즈로 작성하였기에 살펴보았다. 이 글 이후에 분석 사례가 많던데, 매우 기대된다.퍼널 최적화는 '유저의 제품 내 특정 전환율 증진'을 위한 방법으로, 두 가지 접근으로
4.매출 증대를 위한 최적의 할인 전략을 찾아보자
게속해서 딜라이트룸의 데이터 분석 글을 읽고 있다. 실제로 알라미 어플을 자주 사용하고 있지만, 아직까지는 알라미 유료 결제의 필요성을 느끼지 못한 무료 유저이다. 가끔 할인 배너가 뜨곤 하는데, 마침 이번 글이 최적의 할인 전략 실험 내용이라서 흥미롭게 읽었다.출처:
5.어떻게 문제를 정의하고 가설을 세워야할까?
지난번 데이터 문해력 책을 읽으면서 문제 정의와 가설 설정의 중요성을 되새겼다. 이와 관련하여 두가지 글을 읽어보았다. 문제 정의와 가설 설정이 데이터 분석의 시작이라는데, 어떻게 해야 '잘' 정의하는걸까?출처: ‘좋은 문제’ 정의하는 꿀팁 🍯: 사례로 살펴보는 나쁜
6.진짜 활성 사용자는 몇명일까?
'활성 사용자'는 단순히 해당 서비스에 접속한 사용자로 두루뭉실하게 정의하면 되는걸까? 어떻게 정의하고, 어떻게 이 개념을 활용해야하며, 어떻게 측정할 수 있을까? 이 질문에 대해 매우 쉽게 설명한 글이 있어서 정리해보았다.출처: 기획자와 마케터를 위한 활성 사용자 총
7.데이터 사이언스 영역별 자동화 전망
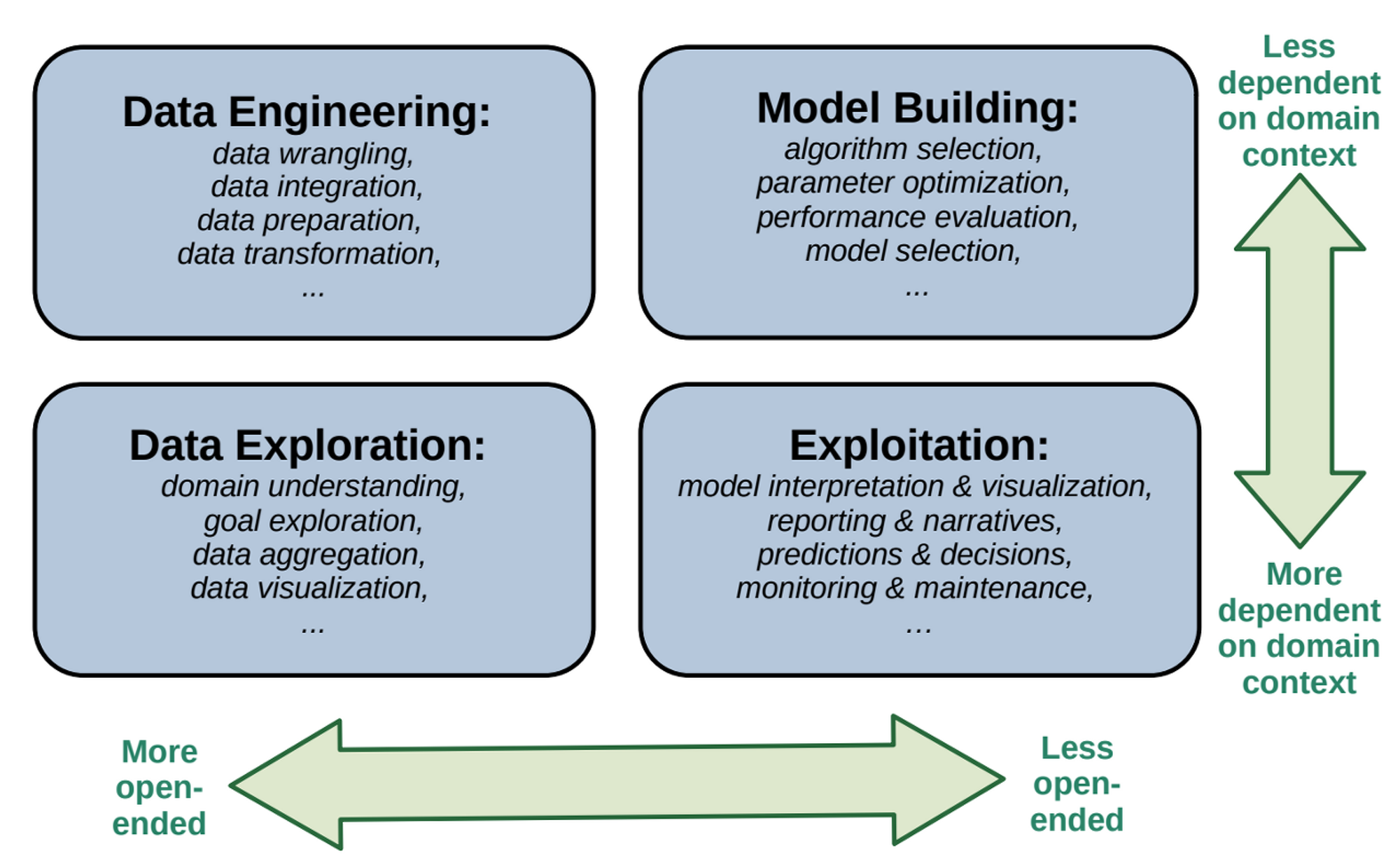
점점 더 AI의 발전 속도가 빨라지면서 AI를 활용한 업무 자동화 사례들이 눈에 띄고 있다. 특히 데이터 사이언스 분야의 업무에는 반복되는 부분이 많은데, 이를 AI가 다 대체하면 나는 어디로 취업을 해야하나..라며 우스개소리로 걱정한 적도 많다. 이와 관련하여 데이터
8.[리뷰] Twyman 법칙과 분석에서의 다양한 실수들
벌써 매일 한 편의 글을 읽고 정리한지 일주일이 넘었다. 오늘은 '데이터 과학자 원칙' 저자 중 한 분인 김진환님의 글을 읽으며 데이터 분석 결과물을 바라보는 시각에 대해 알아보았다.출처: 수상할 정도로 결과가 잘 나오는 데이터 분석을 만드는 방법: Twyman 법칙과
9.[리뷰] AARRR로 뉴스레터 쪼개보기
뉴닉, 어피티 등 몇가지 뉴스레터를 구독하면서 가끔 "뉴스레터는 어떻게 돈을 벌지?" 라는 생각이 들곤한다. 유료 멤버십을 가입해야만 읽을 수 있는 컨텐츠가 아닌 무료로 제공되는 뉴스레터들은 도대체 어떻게 돈을 버는걸까 궁금했다. 그런데 오늘의 데블챌을 작성하기 위해
10.[리뷰] 스타트업을 위한 16가지 지표
오늘은 스타트업, 특히 비즈니스와 재무에 중점을 둔 16가지 지표를 간략히 정리해놓은 글을 읽어보았다. 재무 지식이 부족하여서 특히 기억에 남길 지표 위주로 정리해보았다.출처: \[해외 데이터 분석 소식] 스타트업 지표에 대한 16가지 이야기(원문: 16 Startup
11.[리뷰] 리텐션을 잘 못 다루면 망하는 이유 3가지
계속해서 지표와 관련한 글을 읽고 있다. 오늘은 그중에서도 리텐션이 중요한데, 이 중요한 리텐션을 다룰 때 주의할 점이 무엇인지에 대한 글을 읽었다. 출처: 리텐션의 또 다른 의미, 조용한 킬러빠르게 성장한 스타트업 중에서 빠르게 망하는 회사들이 종종 있다. 분명 회사
12.리텐션이 증가하면 LTV와 매출은 얼마나 증가할까?

12일차 데블챌을 실패하고, 13일차를 작성하게 되었다. 어느덧 내일이 마지막 데블챌이라니, 마지막까지 최선을 다해야겠다.오늘은 저번글에 이어서 리텐션과 관련된 글을 읽었다. 확실히 개념만 설명한 글보다는 실제 예시로 수치와 함께 계산해주는 글이 이해하기 쉽고 더 생생
13.[리뷰] 데이터 분석가의 깊은 분석이란
데블챌 마지막날은 돌고돌아 '분석'의 의미에 대해서 읽어보았다. 분석이 무엇인지, 다른 직군과 차별화 되는 분석가만의 분석과 역할은 무엇인지에 대해 쉽게 이해할 수 있었다.출처: 얕은 분석과 깊은 분석의 차이점분석은 "무엇"이 아니라 "이유"와 "맥락"이 중요하다. 단