데이터 블로그 챌린지: 데블챌 2기 7일차
점점 더 AI의 발전 속도가 빨라지면서 AI를 활용한 업무 자동화 사례들이 눈에 띄고 있다. 특히 데이터 사이언스 분야의 업무에는 반복되는 부분이 많은데, 이를 AI가 다 대체하면 나는 어디로 취업을 해야하나..라며 우스개소리로 걱정한 적도 많다. 이와 관련하여 데이터 사이언스 각 영역별로 자동화에 대한 전망은 어떤지, 이를 업무에서 어떻게 활용할 수 있는지에 대한 글을 읽어보았다.
요약
1. 자동화를 위한 몇 가지 조건
AI만 있으면 자동화가 뚝딱 이루어지고, 업무 효율성이 극대화될까? 사실은 자동화가 불가능하거나, 자동화로 인한 이득보다 비용이 큰 경우 등 몇 가지 조건이 존재한다.
- 요구사항, 프로세스, 평가기준이 잘 정의되어 있는가?
- 도메인이나 문제 특성에 구애받지 않는 일반적인 해결책이 존재하는가?
- 결과물이 인간에 의해 직접 사용되는가?
- 오류나 장애 해결을 위한 비용이 자동화에 따른 효용보다 작은가?
2. 데이터 사이언스의 네 가지 영역
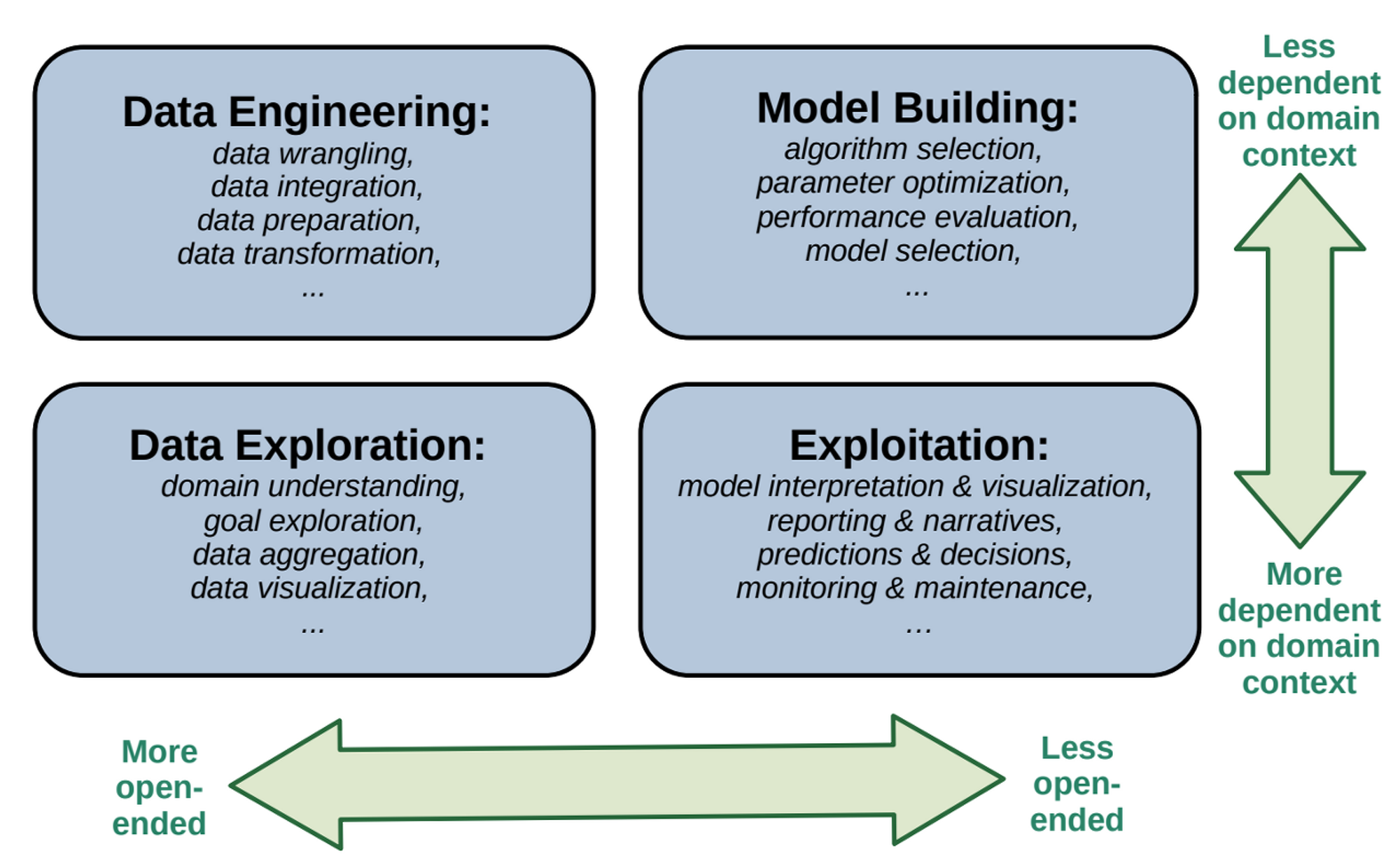
데이터 사이언스는 크게 도메인의 영향을 얼마나 받는지, 정해진 정답이 존재하는지의 두 축으로 나눌 수 있다.
이때 자동화에 따른 비용 대비 효용이 얼마나 좋은가에 따라 자동화가 얼마나 용이할지 전망을 가늠할 수 있다.
1) 데이터 엔지니어링
- 자동화 전망: 하
- 다양한 데이터와 조직별로 다른 요구사항을 수용해서 데이터 파이프라인을 만드는 일은 속도보다 완성도가 중요한 업무이다.
- 대신 자동 스키마 추출 등 부분적으로 반복적인 업무를 자동화하여 업무의 효율성을 증가시킬 수는 있다.
2) 탐색적 분석
- 자동화 전망: 중
- 수많은 데이터셋의 종류만큼 다양한 접근 방법을 통해 문제를 정의하고 가설을 세워 데이터를 검증하는 일은 특히 도메인 지식이 많이 관여하기 때문에 완전한 자동화는 어렵다.
- 그러나 개별 컬럼의 분포와 이상치를 살피고, 컬럼간 상관 관계를 시각화 하는 등 이미 EDA를 자동화하는 라이브러리가 많이 존재한다. 분석 이후 자동으로 리포트까지 써주니, 시간을 대폭 단축할 수도 있다.
3) 예측 모델링
- 자동화 전망: 상
- 서비스에 필요한 모델을 만들기 위해서는 '요구사항 수집 → 모델 개발 → 오프라인 평가 → 디버깅 및 조율 → 온라인 평가'의 사이클이 반복되어야 한다.
- 이미 AutoML등을 통해 모델과 하이퍼파라미터를 탐색하고 최적의 예측 모델을 만드는 것은 충분히 자동화 되어있고, 효율성을 높이기 위한 자동화가 꾸준히 연구되고 있는 부분이다.
- 다만 학습에 적합한 클린한 데이터를 만드는 일, 개별 모델을 조합해서 실무의 요구사항을 모두 만족시키는 일 등은 모델러의 영역이고 많은 협업이 필요하므로, 결국 모델링의 전 과정이 자동화 되기에는 어려움이 존재한다.
4) 리포팅 및 의사결정
- 자동화 전망: 중
- 조직 내 다른 구성원과 소통하기 위해서는 대시보드나 리포트 형태로 결과물이 정리되어야 한다.
- 정기 리포팅의 경우 반복적인 업무이고, 자동화로 인해 더 쉽게 결과물을 공유받고 빠르게 의사결정을 돕는 것인 매우 이득이 될 것이다.
인사이트
처음 AutoML을 써봤을 때 매우 신세계라고 느꼈다. 열심히 코드를 작성하며 데이터 분석 하는 방법을 배웠는데, 몇줄의 AutoML 코드로 몇시간의 노력이 대체되는 경험이었다. ChatGPT 유료 버전으로 데이터 분석을 요구했을 때는 두번째 신세계를 맞보았다. 아마 점점 생성형 AI는 발전할 테고 많은 부분에서 자동화는 가속화 될 것이다.
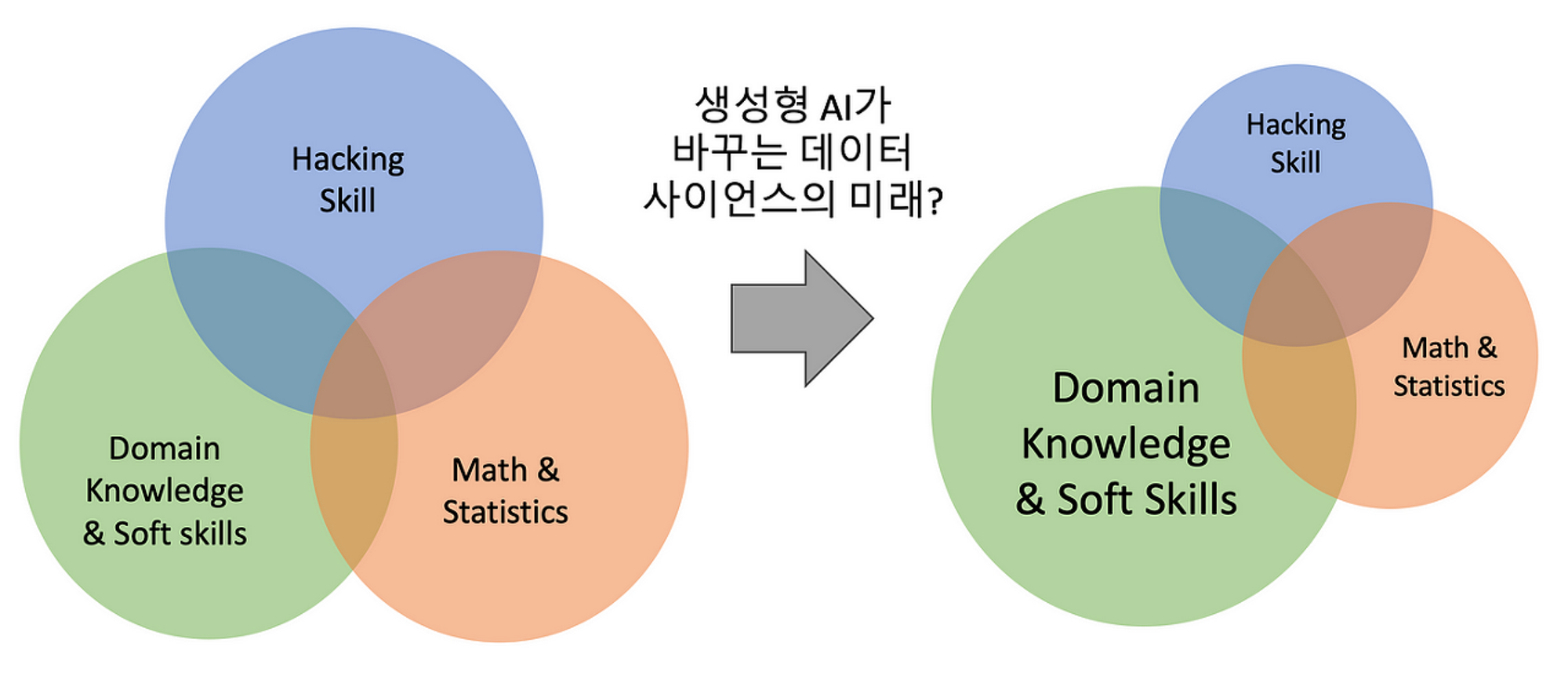
그러나 글쓴이가 말했듯이, 데이터 사이언스의 모든 영역이 자동화 될 수는 없다. 그리고 그 자동화는 인간을 대체하는게 아니라, 업무의 효율성을 높이는게 목적이 되어야 한다. 그러니 위 사진처럼 소프트 스킬과 도메인 지식을 나의 무기로 갖출 수 있도록 겁 먹지 말고 나만의 역량을 쌓는데 집중해야겠다.
