인프라
1.AWS - EC2 (Amazon Elastic Compute Cloud)

EC2는 Elastic Compute Cloud의 약자로, 다양한 운영체제로 인스턴스를 생성하고 보안 및 네트워크 설정 등을 관리할 수 있다. 사용량에 따라 가격이 부여되며, CPU나 RAM, 인터넷 연결 속도까지 필요에 맞게 고를 수 있다.과거 '서버'를 돌리려면 컴
2.AWS - S3
Amazon S3(Amazon Simple Storage Servive) 는 인터넷용 스토리지 서비스이다.이번 프로젝트에서는 이미지만 저장할 목적으로 S3을 이용하였다.S3에는 Bucket과 Object 라는 단위가 있다. 객체(Object)는 데이터와 메타데이터를 구
3.AWS Basic - Network
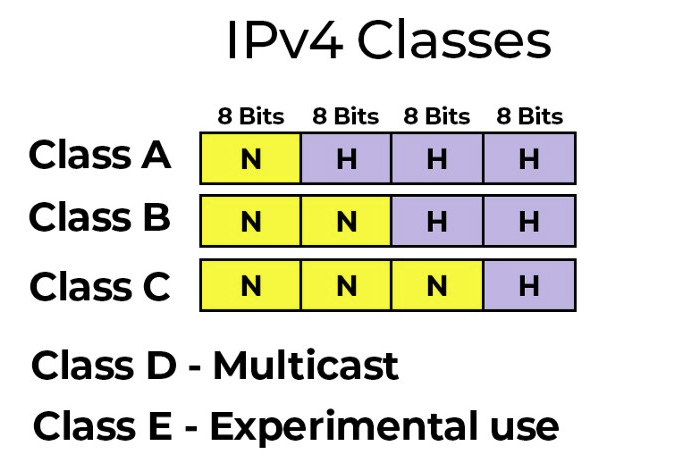
컴퓨터 사이에 통신을 하기 위한 컴퓨터의 위치값 ( IPV4 )172.16.254.1 → 각 .(온점)으로 구분되어있는 숫자를 옥텟이라고 표현각 옥텟은 8비트의 수로 표현네트워크는 클래스로 나누어져 있으며, 첫 번째 옥텟의 앞자리 숫자들을 바탕으로 Class들을 구분한
4.AWS - Glue(1) : 개념과 특징
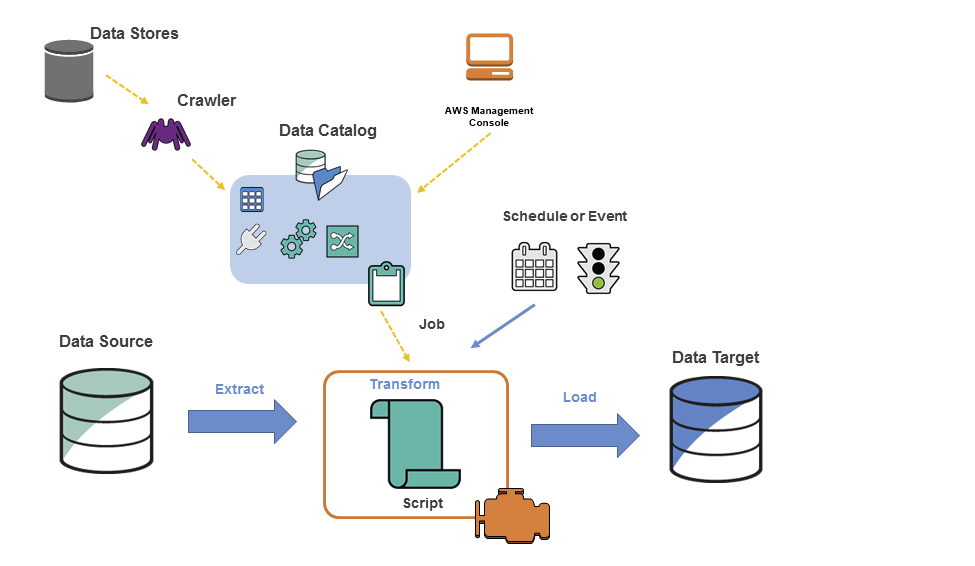
AWS Glue란?완전 관리형 데이터 추출, 변환 및 로드(ETL) 서비스Data Store : S3, RDS, Redshift, Kinesis, Apache kafka 등 데이터 저장 서비스 혹은 데이터 스트림 서비스Crawler(크롤러) : Classifier의 우
5.AWS - Glue(2) : 사용
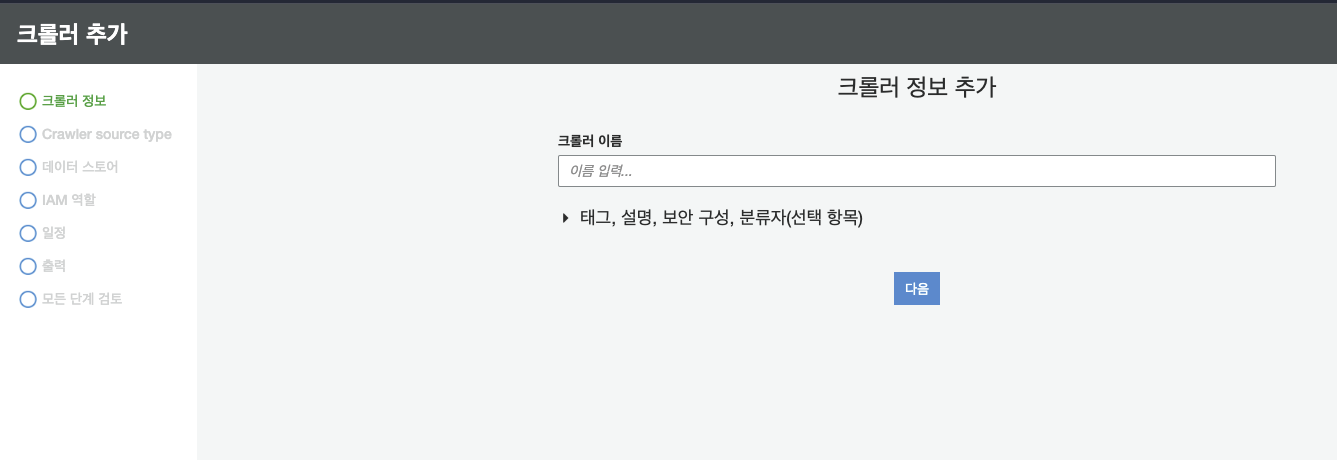
데이터 엔지니어링에 관한 이론적인 공부만 하다가, AWS Glue를 사용할 일이 생겼다.S3에 csv 파일로 저장되어 있는 데이터를 AWS Glue를 사용하여 parquet로 변환한 후, Athena를 이용하여 데이터를 분석할 예정이다AWS Glue의 크롤러에 들어간다
6.AWS - Athena
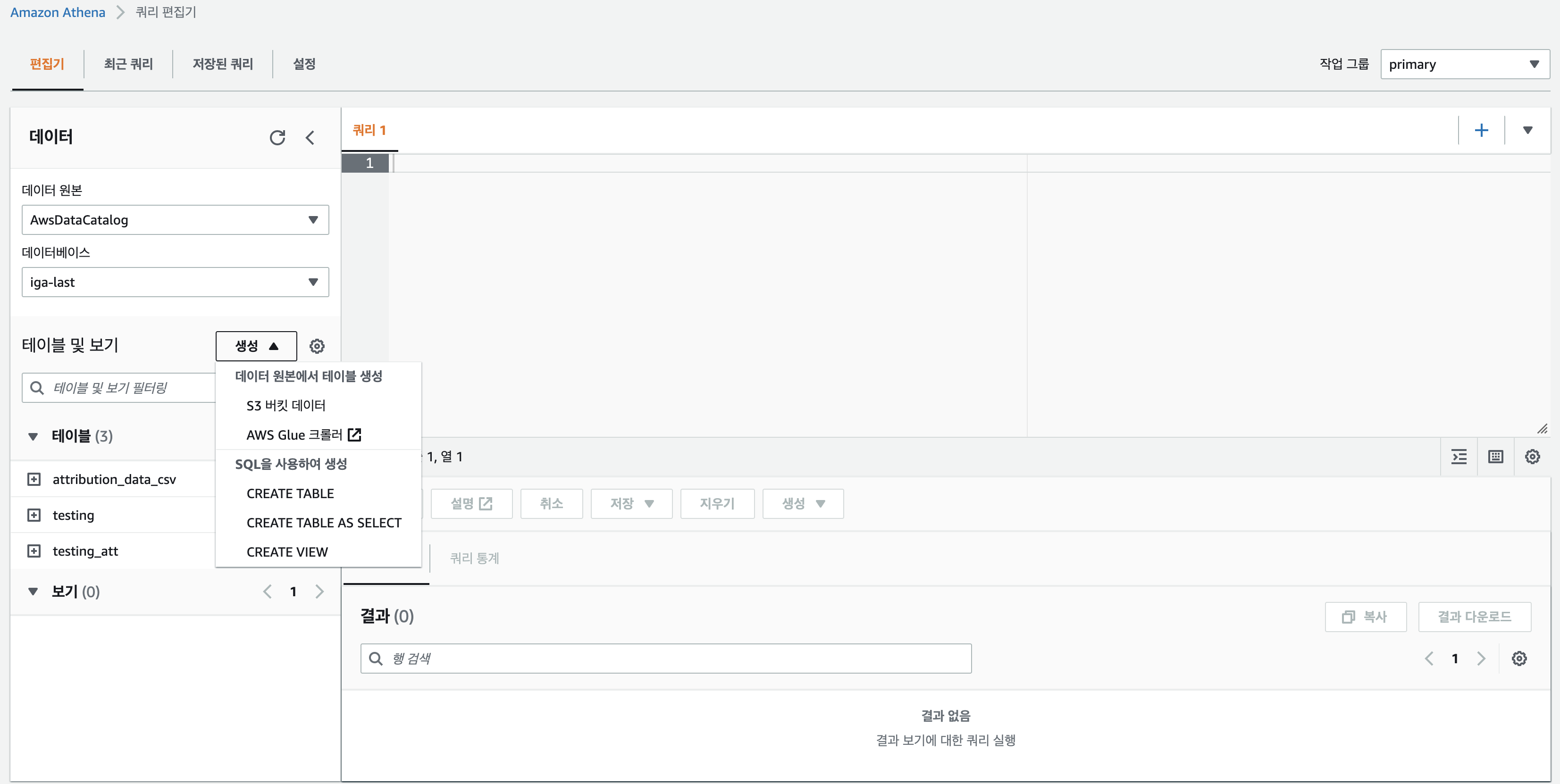
AWS Athena란? S3에 저장된 로그 데이터를 쉽게 분석하는 기능을 제공해주는 SQL 쿼리 서비스 AWS Athena는 CSV, JSON, Avro, parquet, text 로그등의 데이터를 분석하는데 도움을 준다. Athena는 메타 데이터 스토어의 역할을
7.AWS - Redshift(1) : 개념
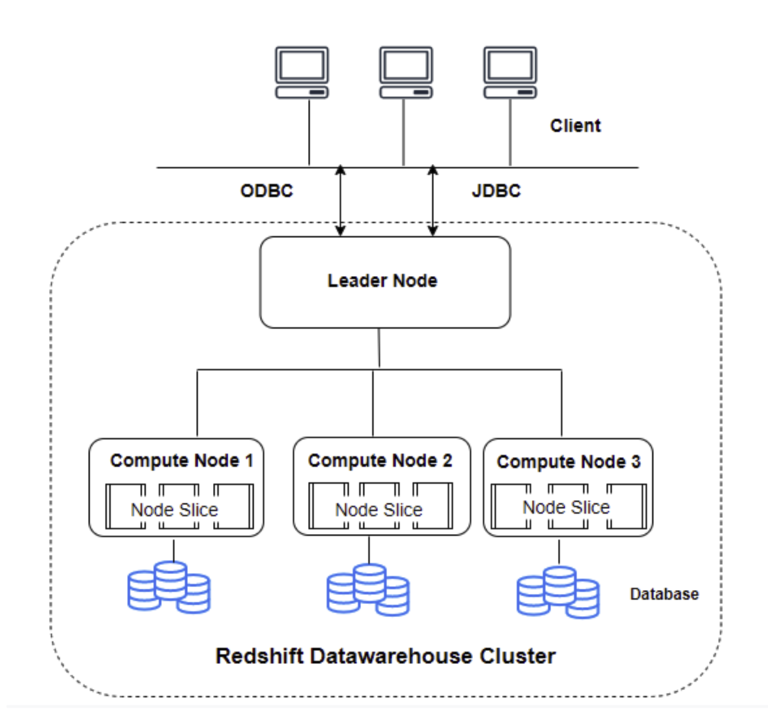
대용량 데이터를 처리할 수 있는 완전 관리형 데이터 웨어하우스 서비스MPP (Mass Parallel Processing) : 대규모 병렬 컴퓨터\--> 많은 독립적인 노드들이 네트워크로 서로 연결된 하나의 커다란 분산 메모리 컴퓨팅 시스템여러 컴퓨팅 노드가 병렬로 작
8.AWS - Redshift(2) : 사용
근무중인 회사에서, 전자지갑의 트랜잭션을 확인하여 DAU와 일일 거래액을 확인해야 할 일이 생겼다. Pandas나 Spark로 충분히 처리할 수 있지만, 추후에 생길 PG서비스의 아키텍처 구성을 연습할겸, Redshift를 사용해보기로 했다.지난 포스트에서, S3에 업
9.AWS - Kinesis(1) : 개요
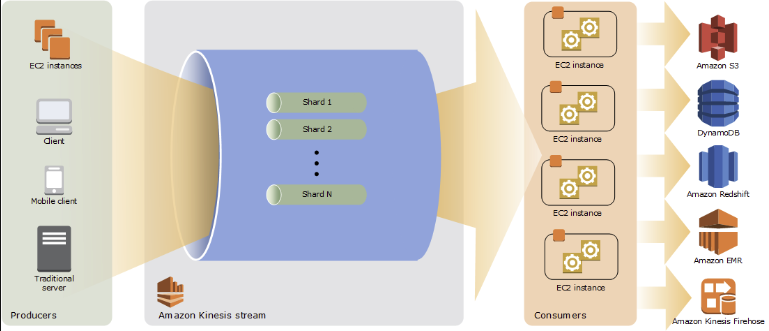
실시간으로 대용량 스트리밍 데이터를 수집하고, 처리 및 분석할 수 있는 서비스스트리밍 데이터 처리의 Usecase 크게 3가지로 나눌 수 있다분석 도구에 신속하게 데이터 전달ex) S3에 로그 데이터 수집데이터가 생성될 때 분석 수행실시간 데이터 출력 가능ex) 시계열
10.AWS - Kinesis(2) : 사용
회사에서는 자바 혹은 노드로 서버단을 처리하지만, 프로젝트에 적용하기 전 실습이니만큼 파이썬으로 기능을 구현하고자 한다aws configure가 마무리 되었다는 가정하에 본 포스트를 작성한다데모용이므로 온디맨드로 가볍게 만든다. 데이터 스트림을 생성하는 것은 복잡하지
11.AWS - EMR : 개요 및 사용
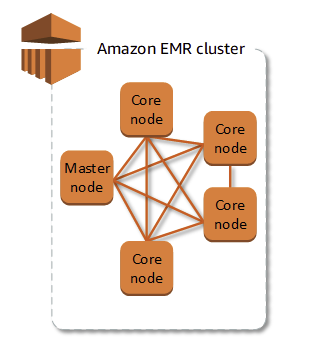
AWS에서 제공하는 완전관리형 빅데이터 플랫폼하둡, 스파크, Hive, 제플린 등 오픈소스 프레임워크를 가지고 클러스터를 쉽게 구축해주는 서비스이다클러스터는 EC2 인스턴스의 모음. 클러스터에 있는 각 인스턴스를 노드라고 한다처리를 위해 다른 노드 간 데이터와 작업의