AWS Glue란?
- 완전 관리형 데이터 추출, 변환 및 로드(ETL) 서비스
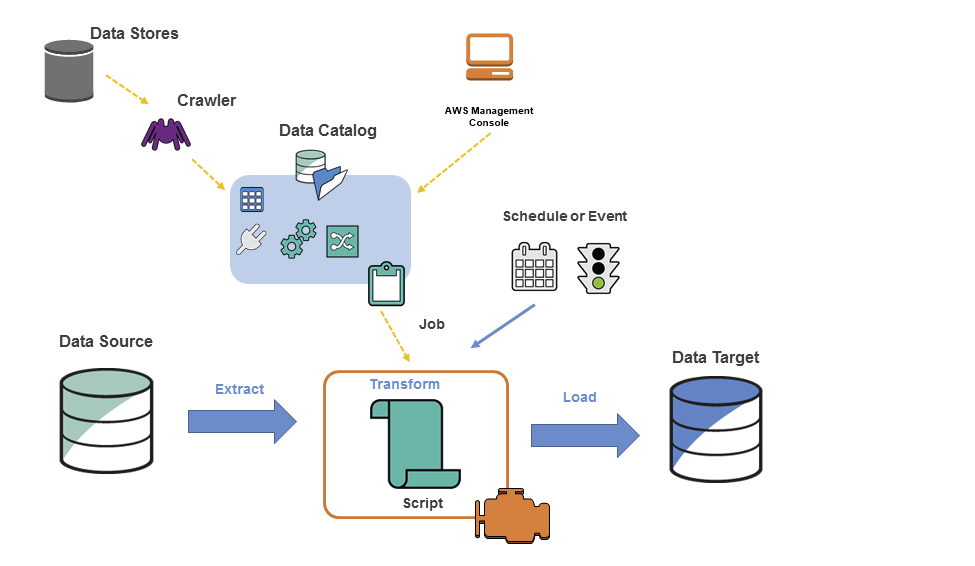
AWS Glue 구성요소
- Data Store : S3, RDS, Redshift, Kinesis, Apache kafka 등 데이터 저장 서비스 혹은 데이터 스트림 서비스
- Crawler(크롤러) : Classifier의 우선 순위 지정 목록을 통해 데이터의 스키마를 결정한 다음, 메타 데이터 테이블을 생성
- Classifier : 데이터의 스키마를 결정하고 일반적인 파일들의 분류자를 제공 ex) csv, parquet 등
- Data Catalog : 테이블 정의, 작업 정의 및 기타 관리 정보를 포함
- Job : ETL 작업을 수행하는 데 필요한 변환 스크립트, 데이터 원본 및 데이터 대상으로 구성된 비즈니스 로직
- Connection : AWS의 다른 데이터 저장 서비스나 사용자의 VPC환경 내부에 있는 데이터베이스에서 데이터 추출을 위한 장치
- Script : Apache Spark에서 사용하는 PySpark, Scala등으로 짜여진 ETL 작업 스크립트
- Schedule, Event : Job이 실행되는 주기를 설정하거나, 혹은 특정 이벤트로 인한 트리거로 실행할 수 있습니다.
AWS Glue 특징
- 서버리스 이므로 설정하거나 관리할 인프라 없다
- 원본 데이터의 변경 및 변경 데이터의 저장을 위한 별도의 저장소가 필요없다
-> 메타데이터 만으로 ETL작업을 수행
- 반정형 데이터 또한 작동할 수 있다
- ETL 스크립트에서 사용할 수 있는 Dynamic Frame이라는 구성 요소를 사용하여 Apache Spark의 Data Frame과 완벽 호환. 또한 스키마가 필요 없고 Dynamic Frame용 고급 변환 세트 이용할 수 있다
- 고성능의 워커로 빠른 작업수행이 가능
- 스케쥴링 기능으로 주기적인 작업 실행을 자동화할 수 있다
- 북마크 기능으로 작업상태를 저장하여 중단된 시점부터 작업 재개 가능하다
- 작업에 대한 모니터링을 지원
AWS Glue 기능
- 데이터 스토어 소스의 경우, 크롤러를 정의하여 메타데이터 테이블 정의로 AWS Glue Data Catalog를 채운다
- 크롤러는 Data Catalog에서 테이블 정의를 생성한다
- AWS Glue는 스크립트를 생성하여 데이터 변환이 가능하다
Glue Studio
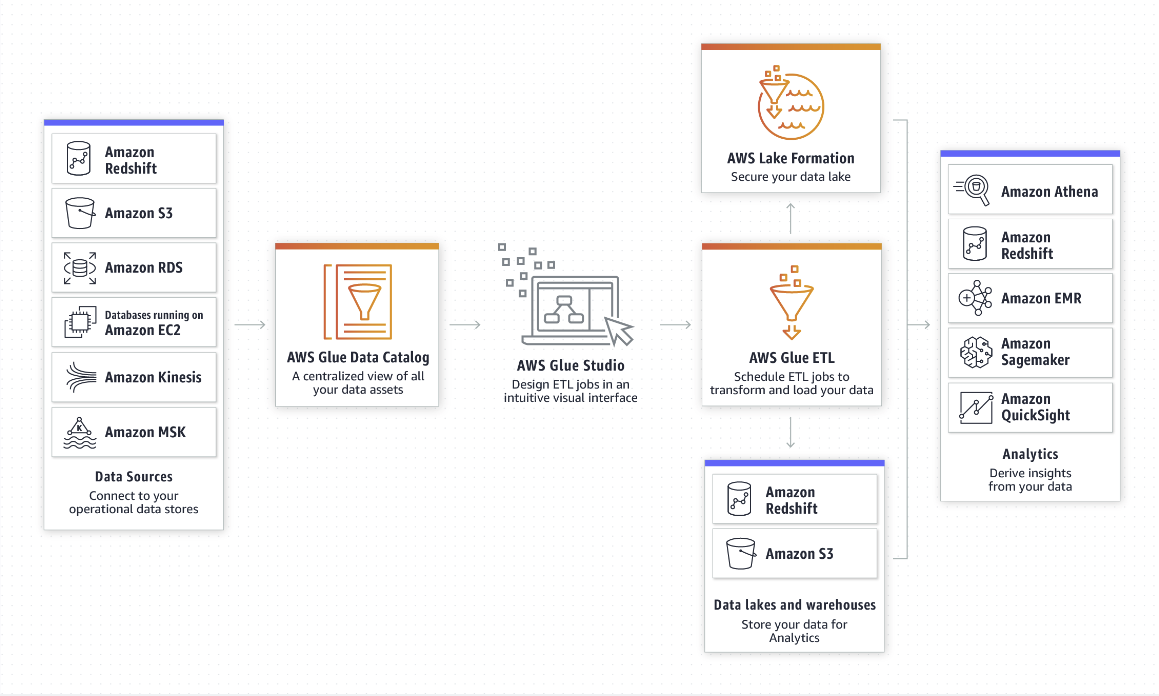
- 사용자가 별도의 코드를 작성하지 않고 AWS Glue의 서버리스 Spark 기반 ETL 플랫폼에서 빅데이터를 처리할 수 있다
- Glue Studio를 통해 여러 데이터 소스에서 카탈로그로 메타데이터만 가져오고, ETL 작업 후 데이터를 저장하거나 엔드포인트를 생성하여 Sagemaker, EMR, QuickSight 등의 서비스로 연결할 수 있다

데이터 엔지니어로 전향중인 백엔드 개발자입니다