데이터 엔지니어링에 관한 이론적인 공부만 하다가, AWS Glue를 사용할 일이 생겼다.
S3에 csv 파일로 저장되어 있는 데이터를 AWS Glue를 사용하여 parquet로 변환한 후, Athena를 이용하여 데이터를 분석할 예정이다
AWS Glue Crawler
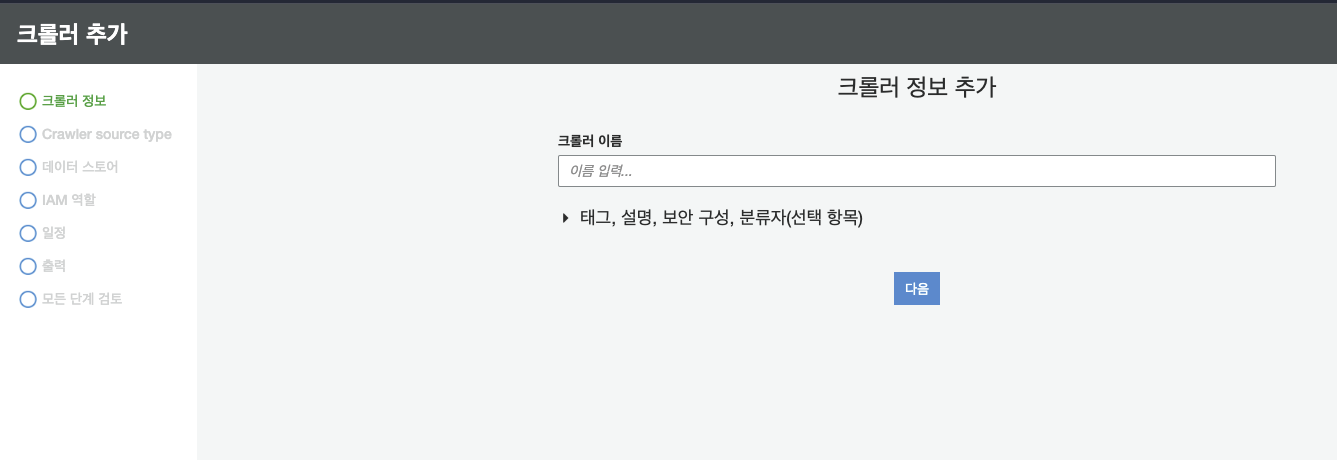
AWS Glue의 크롤러에 들어간다
-
크롤러 이름 입력
-
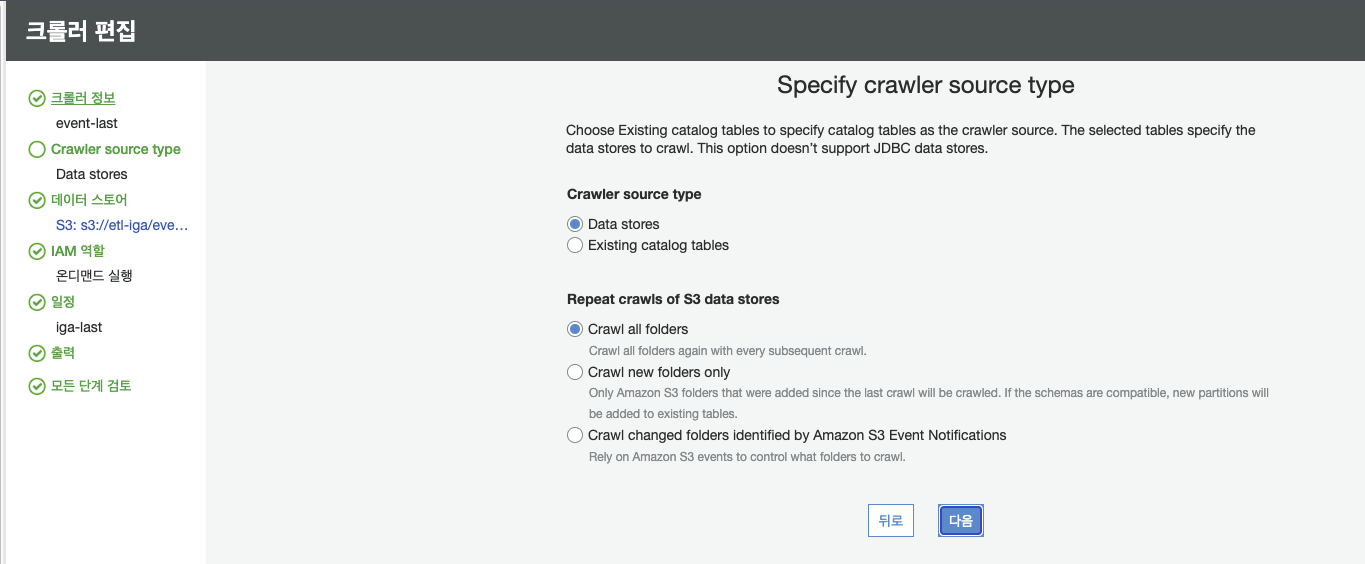
크롤러 소스 타입은 Data stores로 한다
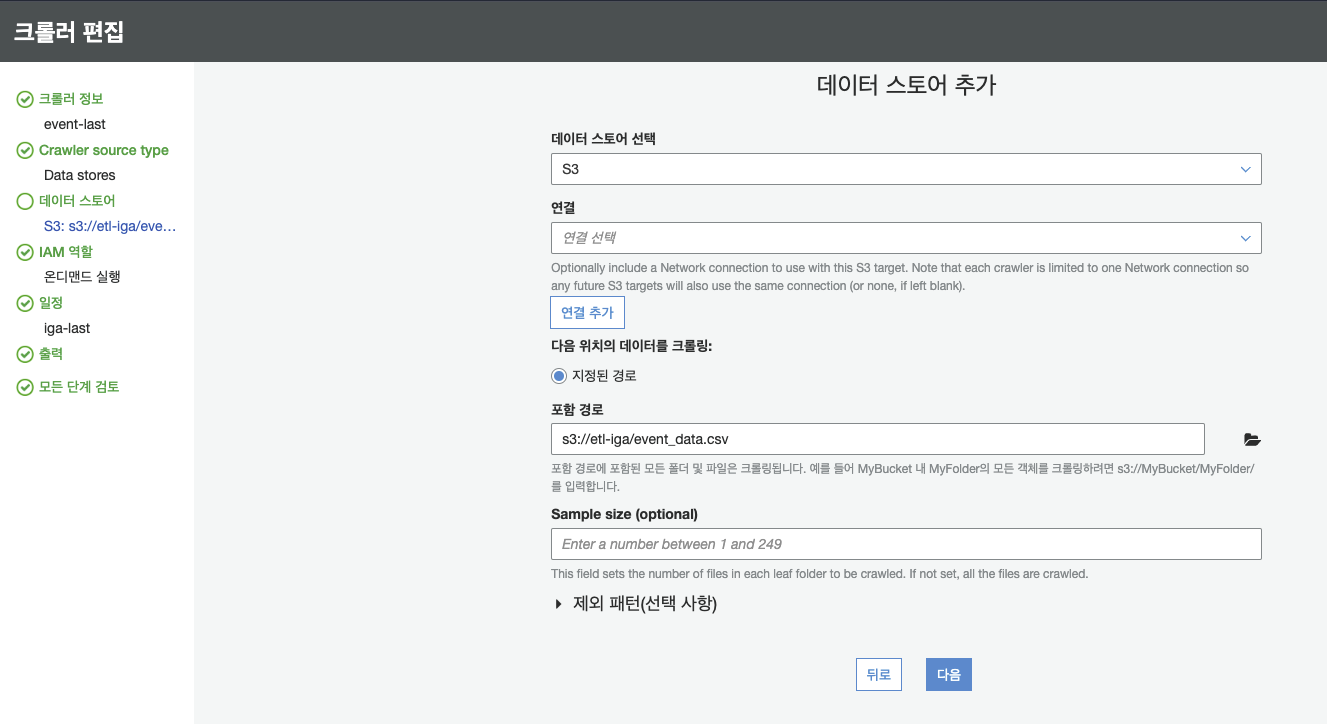
- S3에 있는 CSV 파일을 이용할 예정이므로 데이터 스토어는 S3, 포함 경로는 크롤링 하고자 하는 파일로 정한다

- IAM 역할은 기존에 만들었던 Glue 역할로 하고, 해당 Glue 역할에는 S3의 모든 기능을 사용할 수 있는 권한을 추가하여야 한다
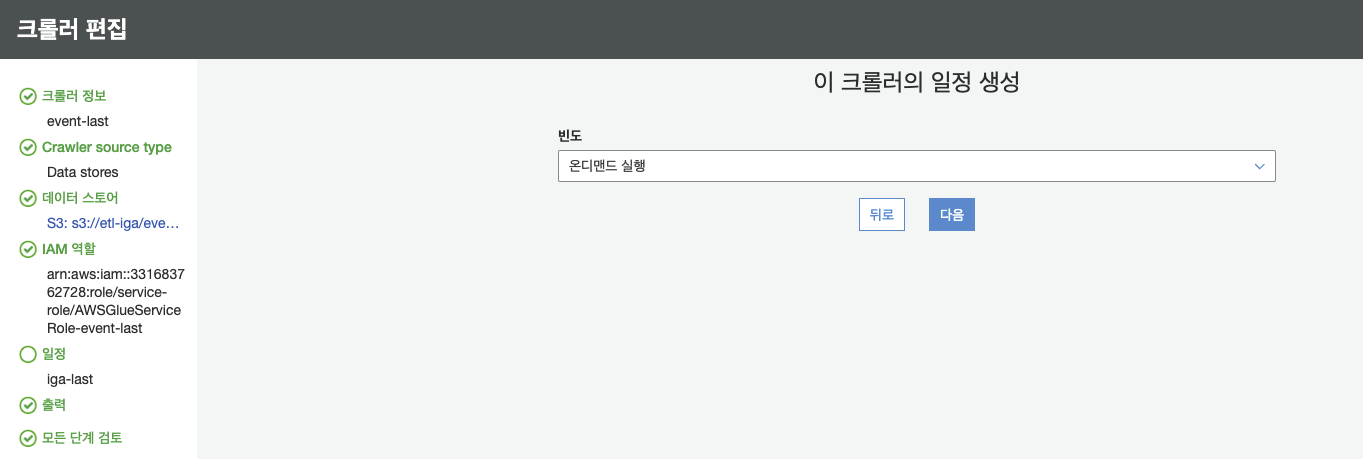
- 후에 실사용 할 때에는 일별 보고서 등의 주기를 포함한 데이터 크롤링을 할 수 있겠지만, 현재는 연습용이기 때문에 온디맨드로 실행
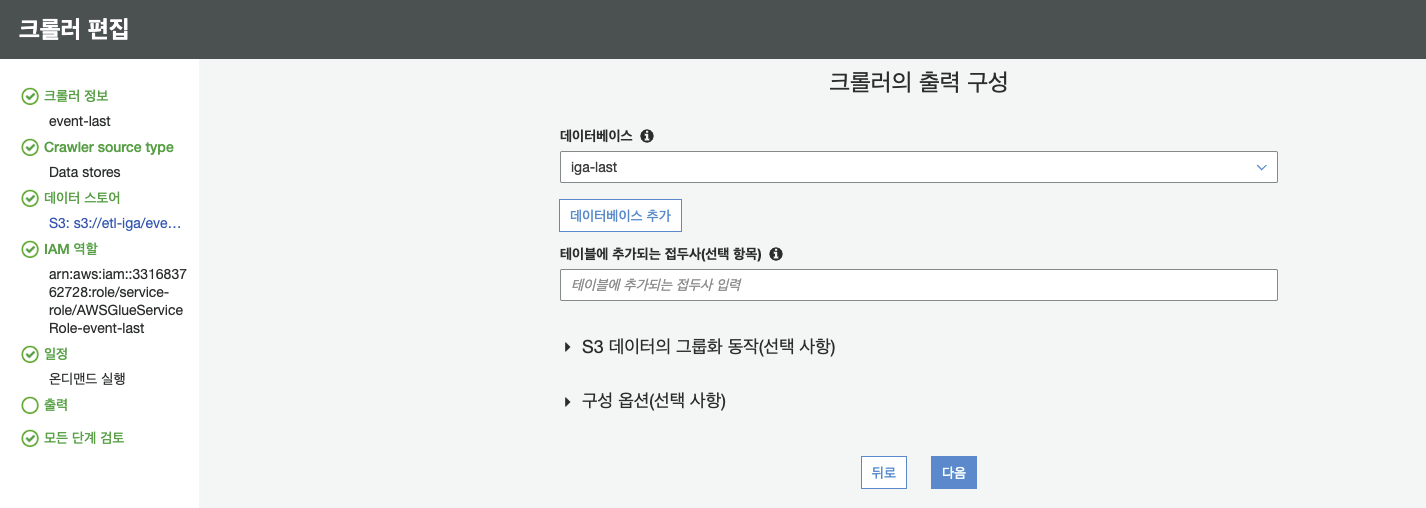
- 크롤링한 결과는 원하는 데이터 베이스에 저장한다
이로써 S3에 저장되어 있는 CSV 파일을 데이터 베이스로 크롤링 하는데에는 성공했다
AWS Glue Studio
: AWS Glue Studio를 이용하여 CSV 파일을 Parquet로 바꾸어 S3로 저장하는 작업을 진행한다
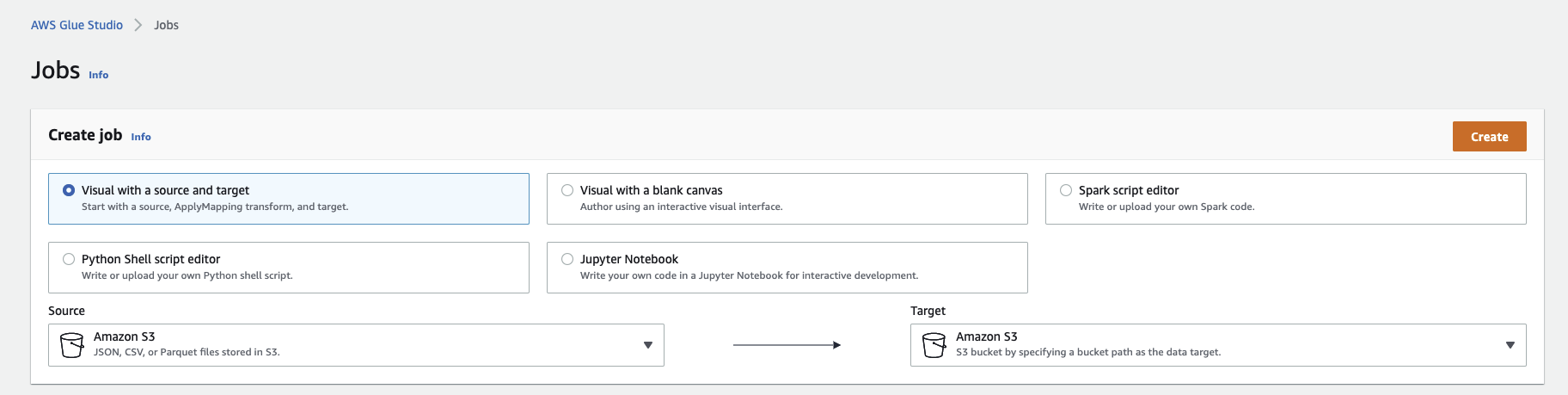
- S3 -> S3로 옮기는 작업으로 Job 생성
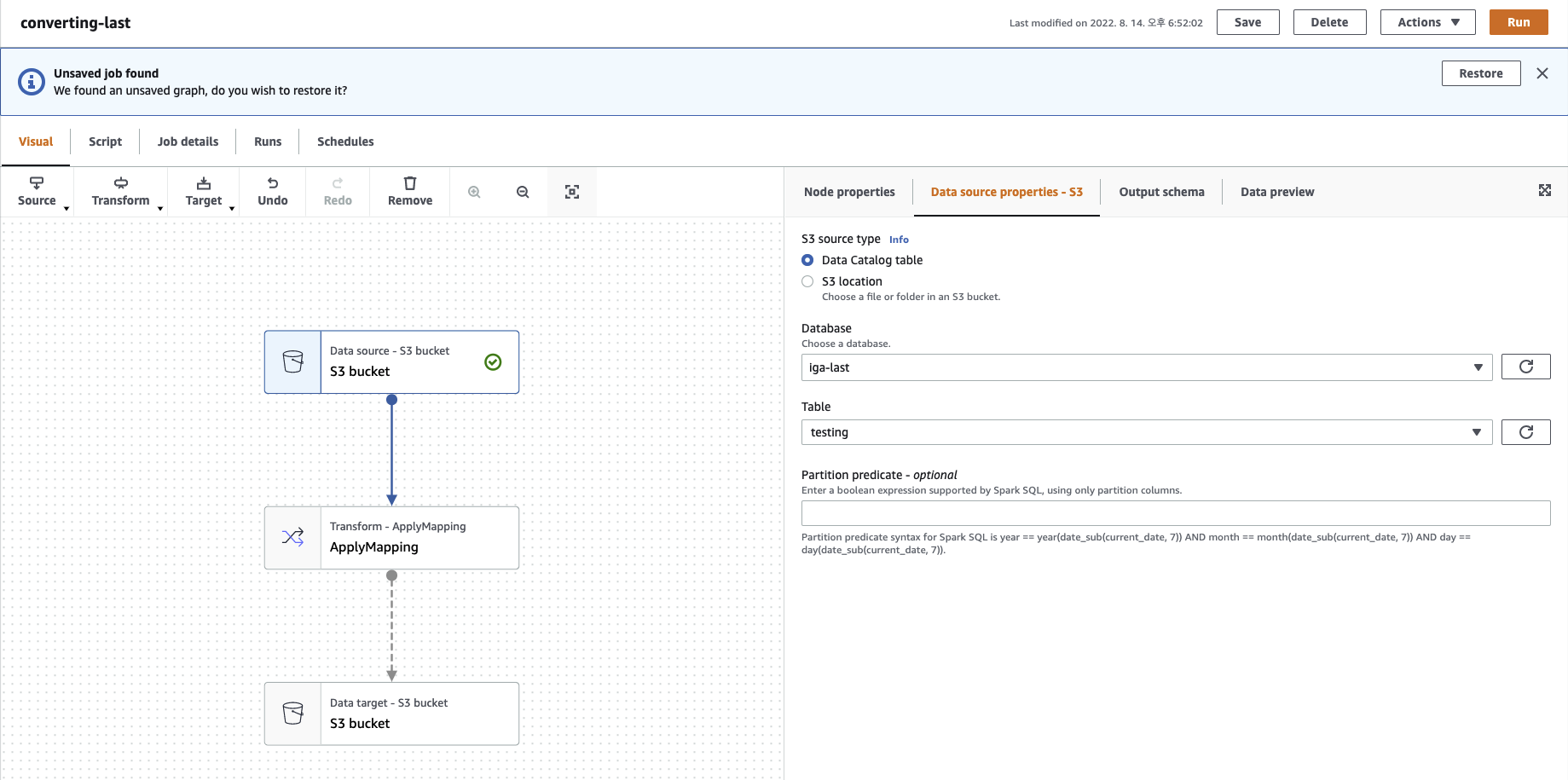
- Database와 Table은 각각 작업하고자 하는 데이터에 접근할 수 있도록 설정
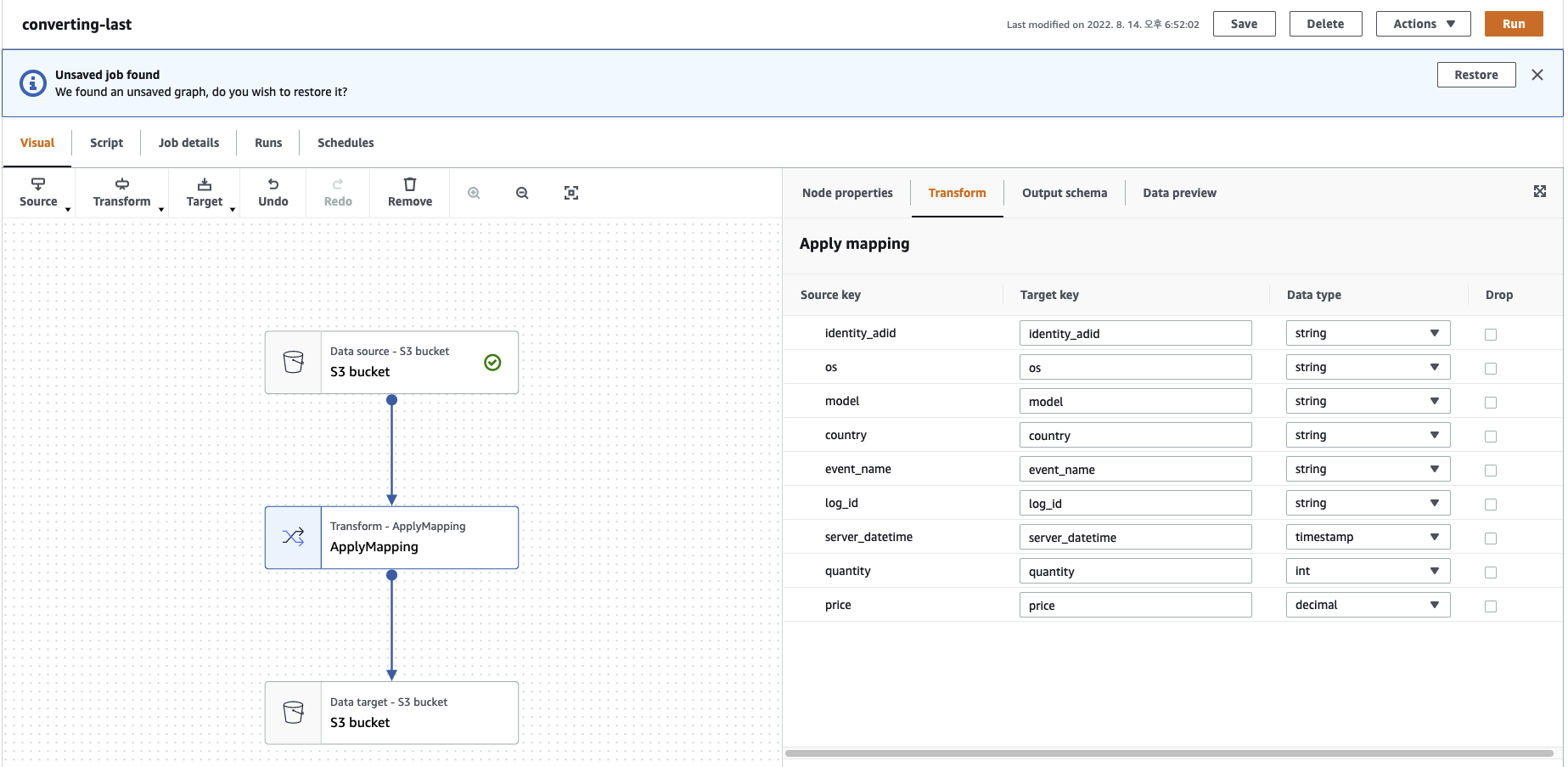
- 적용되는 스키마를 확인, 변경
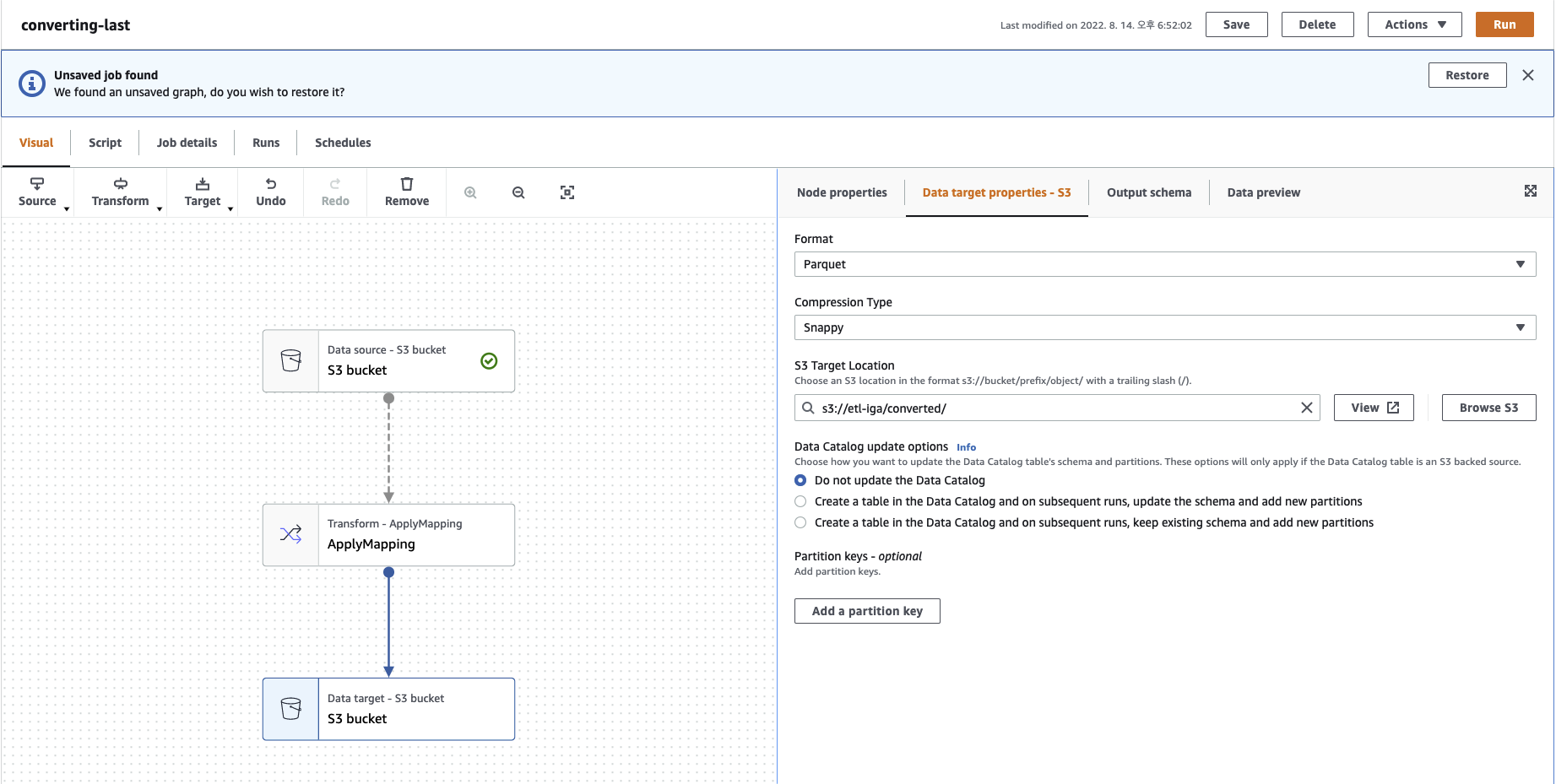
- Parquet로 저장하므로 Parquet 설정, Compression Type은 Snappy
- S3 Target Location은 해당 작업이 진행되고 저장할 디렉토리
- Partition keys는 그 안에서 다시 분기할 테이블 지정(날짜별, 유저별 등등)
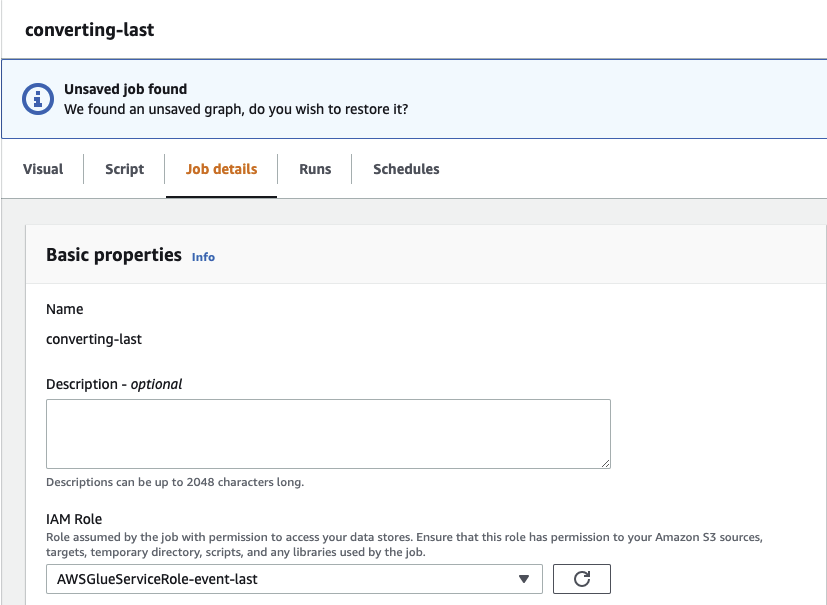
- Job details 탭에 들어가 세부내용 변경
- IAM Role은 크롤러를 만들 때 만들었던 Role로 설정
- Advanced properties -> 각 Script, Spark UI logs, Temporary path는 작업하고 있는 디렉토리 내에 새로운 폴더 만들어서 저장할 수 있도록 설정
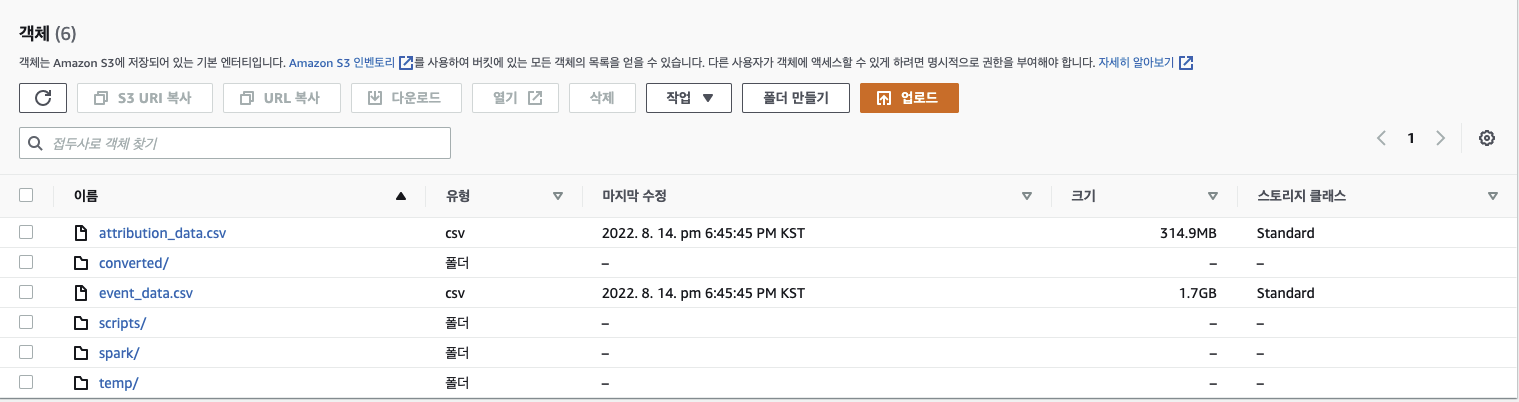
위의 모든 작업들이 끝나면 아래의 그림과 같이 설정한대로 폴더와 파일들이 생성되는 것을 볼 수 있다.

데이터 엔지니어로 전향중인 백엔드 개발자입니다