AWS Athena란?
S3에 저장된 로그 데이터를 쉽게 분석하는 기능을 제공해주는 SQL 쿼리 서비스
AWS Athena는 CSV, JSON, Avro, parquet, text 로그등의 데이터를 분석하는데 도움을 준다. Athena는 메타 데이터 스토어의 역할을 하는 AWS Glue Data Catalog와 결합하여 사용된다.
(이전 블로그 참고)
Athena에서는 테이블과 데이터베이스는 단순히 메타데이터에 대한 정의를 저장하고 있는 저장소일 뿐이다. 일반적인 데이터베이스나 테이블 처럼 직접 데이터를 저장하지 않는다. 데이터셋 별로 테이블이 존재해야 하고, 이 테이블의 스키마를 기준으로 쿼리를 사용할 수 있다.
데이터베이스
- 일반적인 데이터베이스나 테이블 처럼 직접 데이터를 저장하지 않는다
- 데이터셋 별로 테이블이 존재해야 하고, 테이블의 스키마를 기준으로 쿼리를 사용할 수 있다.
테이블
Athena는 Data Catalog에 스키마를 저장한 후, query 실행할 때 꺼내서 사용한다
- 실제 데이터를 테이블에 저장하는게 아니라, 메타데이터만 가지고 있다. 컬럼 이름, 데이터 타입, 테이블 이름과 같은 schema 정보와, 데이터 parse 방식, 그리고 데이터 소스 s3 위치를 저장하고 있다.
- 테이블은 메타데이터 저장소일 뿐이므로 스키마를 변경한다고 원본 데이터가 변경되지 않는다.
- schema-on-read: query를 날리는 그 순간에, 스키마가 원본 데이터에 적용된다
-> schema를 변경했다면, s3에 저장된 원본 데이터가 동일하고, query도 동일하더라도 다른 결과를 내려줄 수 있다
데이터 카탈로그
데이터베이스와 테이블등에 저장된 메타데이터를 관리하는 장소
- Athena는 AWS Glue Data Catalog를 기본적으로 지원한다
- Athena에서 제공하는 Aws Data Catalog를 데이터 소스로 선택한 후, 데이터베이스와 테이블을 생성하면, AWS Glue 서비스의 Data Catalog 아래 databases와 Table에도 생성이 된다 → 연결되어 있다.
작업 그룹
- 작업 그룹별로 사용자나 팀, 어플리케이션 등의 단위 별로 처리 가능한 데이터 양을 지정할 수 있다
- 작업 그룹 별로 cloud watch에서 쿼리 실행과 관련된 메트릭도 볼 수 있다.
-> cloud watch와 연동하여 alarm, SNS topic 연동 등 다양한 연결 작업이 가능하다 - 작업 그룹 별로 쿼리와 관련된 설정을 독립적으로 적용 가능
- 작업 그룹 별로 query 결과를 저장할 S3 버킷 지정 가능
- 작업 그룹 별로 Saved query 지정 가능 및 쿼리 히스토리 조회 가능
쿼리
Athena에서는 AWS Glue Data Catalog로 등록된 스키마 뿐만 아니라, Athena Fedarated Query feature를 통해 등록된 다양한 데이터 소스(Hive metastore, Amazon DocumentDB)에 대한 쿼리 사용이 가능하다. 쿼리는 S3에 있는 데이터를 조회할 뿐만 아니라, S3에 데이터의 저장도 가능하다 .
- 쿼리 결과는 S3 버킷에 저장된다. 이 버킷은 원본 데이터가 저장된 s3 버킷과는 다른 설정 값이다
- 쿼리를 실행하기 전에 쿼리 결과를 저장해둘 S3 버킷을 지정해줘야 한다.
지정 방식
- Work Group에서 값은 지정한 후, client setting을 override 하도록 설정해 준 후 사용
- Client setting에서 설정
Athena 사용
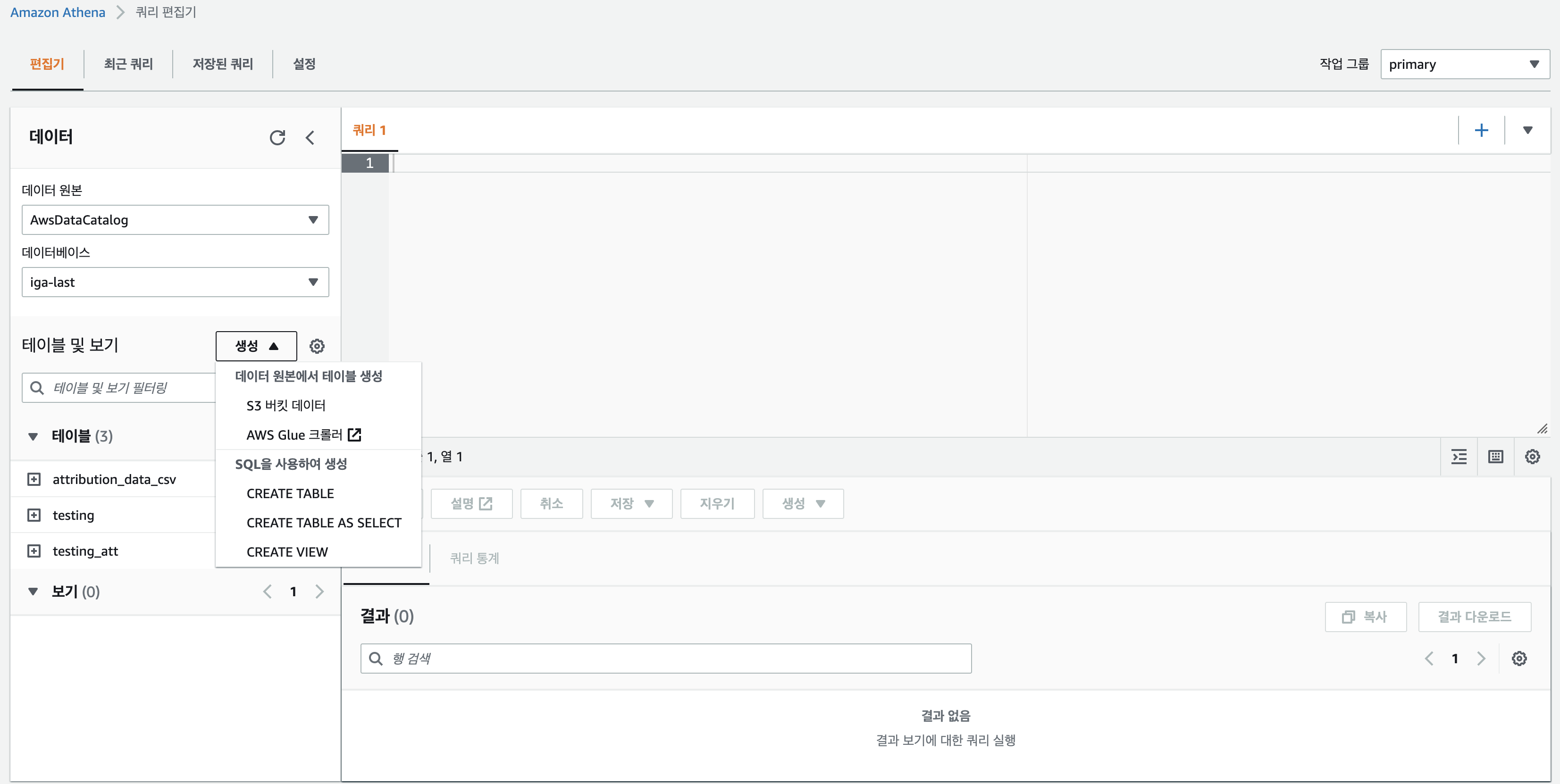
Amazon Athena에 들어가면, 바로 쿼리 편집기를 사용할 수 있다. 데이터베이스는 이전 포스트에서 만들어두었던 데이터베이스를 이용하고, 테이블은 parquet로 저장해두었던 파일을 사용하기 위해 S3 버킷 데이터에서 테이블을 생성하도록 한다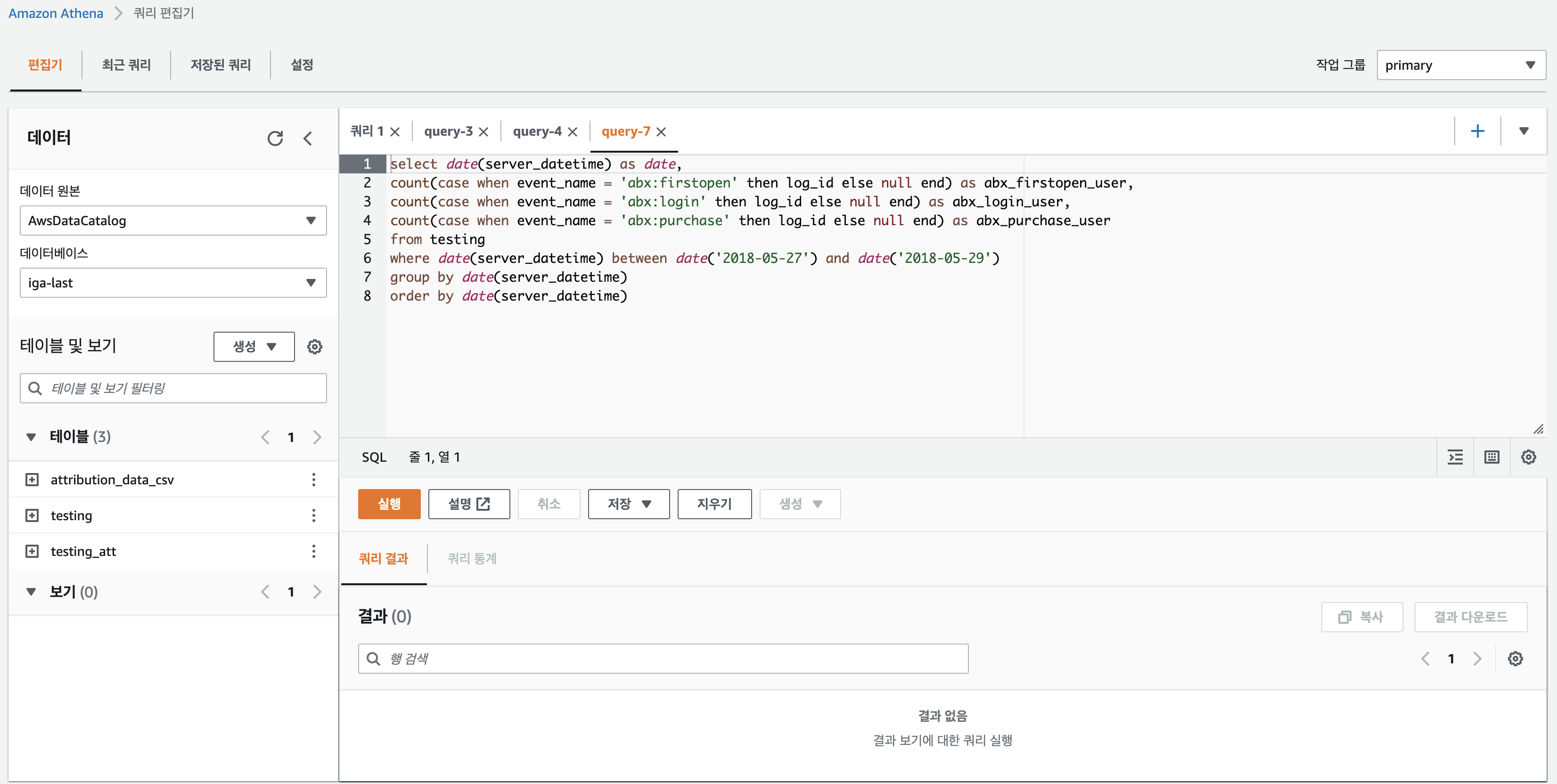
작성하고자 하는 쿼리를 작성하고 실행을 하면, 원하는 결과를 얻을 수 있다
