AWS Redshift란?
- 대용량 데이터를 처리할 수 있는 완전 관리형 데이터 웨어하우스 서비스
- MPP (Mass Parallel Processing) : 대규모 병렬 컴퓨터
--> 많은 독립적인 노드들이 네트워크로 서로 연결된 하나의 커다란 분산 메모리 컴퓨팅 시스템
Redshift 특징
- 여러 컴퓨팅 노드가 병렬로 작동하고 모든 쿼리를 처리한 최종 집계 결과를 얻는다
- 데이터를 병렬로 처리할 수 있도록 테이블의 컬럼들을 컴퓨팅 노드에 배포한다
- Redshift는 데이터를 압축하여 디스크 I/O 요구사항을 줄여 쿼리 성능을 향상시킨다
- Redshift는 최근 쿼리 결과를 리더 노드의 메모리에 버퍼링한다.
- Redshift의 리더 노드는 클러스터의 사용 가능한 모든 노드에 최적화된 컴파일 코드를 배포한다
- 쿼리를 컴파일하면 인터프리터 관련 오버헤드가 제거되므로 유저 쿼리 속도가 빨라진다
Redshift 구성
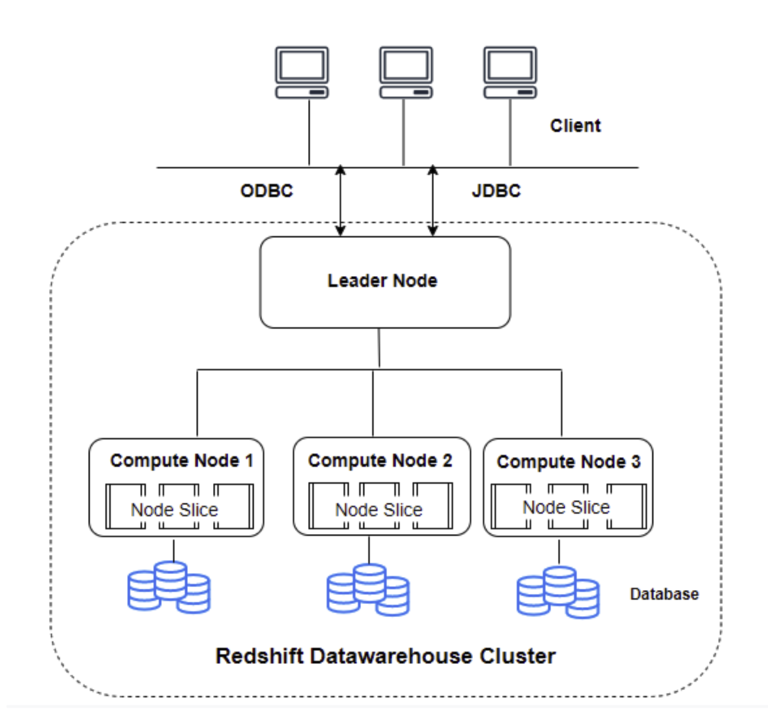
클러스터(Cluster)
- 하나 이상의 컴퓨팅 노드 집합
- 단일 컴퓨팅 노드의 경우 컴퓨팅 노드와 리더 노드 역할을 동시 수행
리더 노드(Leader Node)
- 엔드포인트로써, 클라이언트와 통신을 처리하고 컴퓨팅 노드를 관리한다
- 쿼리가 수행되면 실행 계획을 생성하고 컴파일한 후 컴퓨팅 노드에 전달한다
- 리더 노드는 메타 데이터만 관리하고, 테이블에 데이터가 저장될 때 컴퓨팅 노드에 분할하여 저장
주요 책임 : 코드 컴파일, 외부 응용 프로그램 및 클라이언트 응용 프로그램 상호작용
컴퓨팅 노드(Computing Node)
- 각 컴퓨팅 노드에는 기본적으로 노드 유형에 따라 결정되는 자체 전용 CPU, 메모리 및 스토리지가 있다
- 리더 노드로부터 받은 컴파일된 코드의 실행을 수행하고 중간 결과를 리더 노드로 다시 보내 클라이언트 애플리케이션의 요청에 대한 최종 결과를 집계한다
노드 슬라이스(Node Slices)
- 컴퓨팅 노드는 다수의 슬라이스로 분할되고, 각 슬라이스는 노드의 메모리 및 디스크 공간을 할당 받는다
- 리더 노드를 통해 각 슬라이스에 데이터가 배포되고 수행될 쿼리 또한 할당된다 (이 때 슬라이스는 병렬로 작업 처리)
내부 네트워크(Internal Network)
- 내부 네트워크는 리더 노드와 컴퓨팅 노드 간의 통신을 통해 다양한 데이터베이스 작업을 수행한다
데이터베이스(Database)
- 클러스터에는 하나 이상의 데이터베이스가 포함된다
- 사용자 데이터는 컴퓨팅 노드에 저장된다

데이터 엔지니어로 전향중인 백엔드 개발자입니다