EMR(Elastic MapReduce)란?
AWS에서 제공하는 완전관리형 빅데이터 플랫폼
하둡, 스파크, Hive, 제플린 등 오픈소스 프레임워크를 가지고 클러스터를 쉽게 구축해주는 서비스이다
EMR 구조
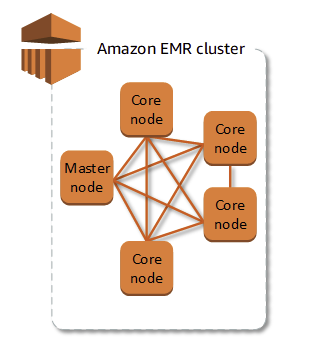
클러스터
- 클러스터는 EC2 인스턴스의 모음. 클러스터에 있는 각 인스턴스를 노드라고 한다
노드
1. 마스터 노드
- 처리를 위해 다른 노드 간 데이터와 작업의 배포를 조정하는 소프트웨어 구성 요소를 실행하여 클러스터를 관리하는 노드
- 작업 상태를 추적하고 클러스터 상태를 모니터링 한다
- 모든 클러스터에는 마스터 노드가 있으며, 마스터 노드만으로도 단일 노드 클러스터를 생성할 수 있다
2. 코어 노드
- 클러스터의 하둡 분산 파일 시스템(HDFS)에서 작업을 실행하고 데이터를 저장하는 소프트웨어 구성 요소가 있는 노드
- 다중 노드 클러스터에는 1개 이상의 코어 노드가 있다
3. 작업 노드
- 작업만 실행하고 HDFS에 데이터를 저정하지 않는 소프트웨어 구성 요소가 있는 노드
시작하기
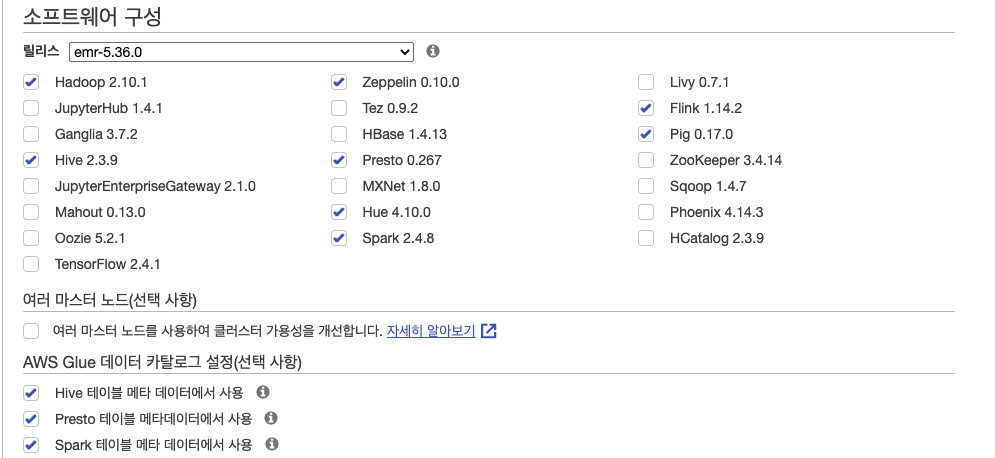
- 소프트웨어는 Spark와 Flink는 기본적으로 모두 실습할 것 이기 때문에 포함. Presto는 사용할 지 모르겠지만, AWS Athena가 Presto 기반이기 때문에 일단 넣어준다
- 또한 Glue에서의 데이터 카탈로그 사용을 위해 메타 데이터 설정은 다 넣어준다 (필요 없을 수도 있음)

-
단계별로 클러스터에 작업을 제출하는 기능으로 확인된다
-
하드웨어 단계에서는 일단 기본값 설정 그대로 사용한다
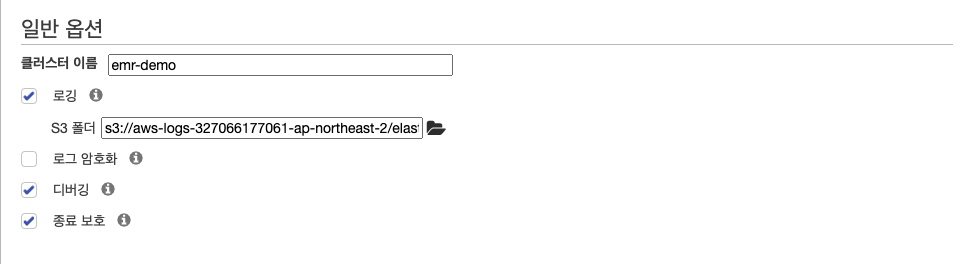
- 클러스터 이름만 변경한 후 다음으로 넘어간다
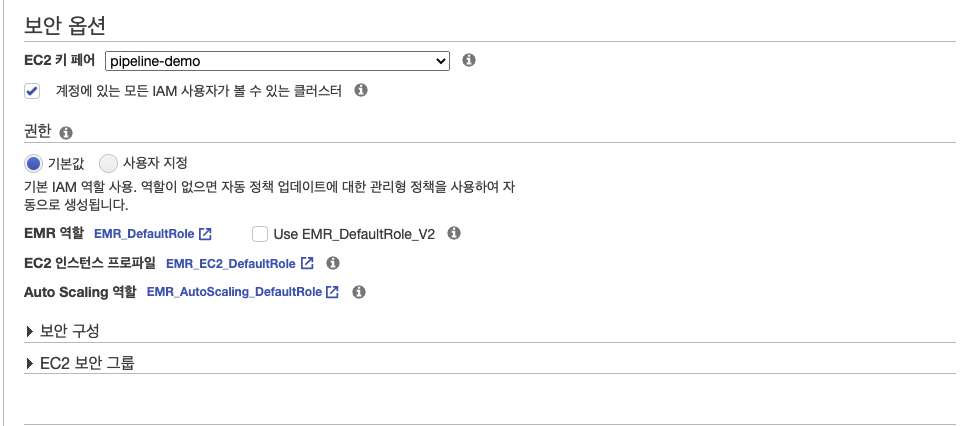
- 키페어만 설정하면 EMR 생성은 마무리가 된다
EMR 설정이 마무리가 되면, 실습을 위한 Zeppelin 사용을 위해 Application user interface의 연결을 설정해준다

화면에 나온대로 터미널을 입력하면 되지만, 맨 처음 마스터 노드에 접속하고자 하면 SSH 에러가 발생한다.
터미널에,sudo nano /etc/ssh/sshd_config를 입력한 뒤,
PasswordAuthentication 을 yes로,
ChallengeResponseAuthentication 을 no로 설정한 뒤 웹 연결 설정을 다시 하면 서버가 켜지는 것을 확인할 수 있다.
이제 가동중인 EMR의 애플리케이션을 모두 사용할 수 있다

데이터 엔지니어로 전향중인 백엔드 개발자입니다