ML
1.[ML] 파이썬 자주쓰는 연산자 & 함수

제곱 (\*\*)나눗셈 몫(//)나눗셈 나머지(%)리스트는 대괄호 활용해 생성len() 으로 길이 확인, member3 등 으로 리스트 내의 요소 인덱싱 가능튜플은 소괄호 활용해 생성len() 으로 길이 확인, member3 등 으로 리스트 내의 요소 인덱싱 가능키와
2.[ML] 파이썬 데이터 핸들링(DataFrame 생성 ~ 시각화)
Pandas 데이터 핸들링 Pandas는 데이터의 형태가 기본적인 리스트가 아닌 배열 (Array) 형태로 되어 있음 일반적인 연산 방법과 조금 다름 데이터 프레임 생성 import pandas as pd #빈 데이터 프레임 생성 df = pd.DataFrame(
3.[ML] 머신러닝
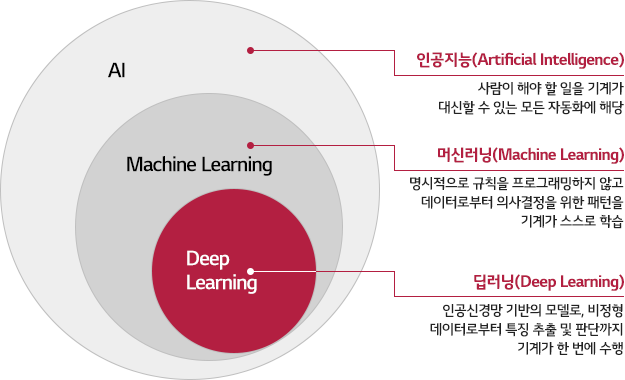
기계가 스스로 데이터 속의 규칙성을 발견하는 알고리즘군집화 (Clustering) ‣ 군집화 알고리즘: K-Means Clustering, DBSCAN 차원축소 (Dimension Reduction) ‣ 차원이 너무 큰 경우, 차원 축소를 통해 정답 데이터를 잘 설
4.[ML] 비지도학습
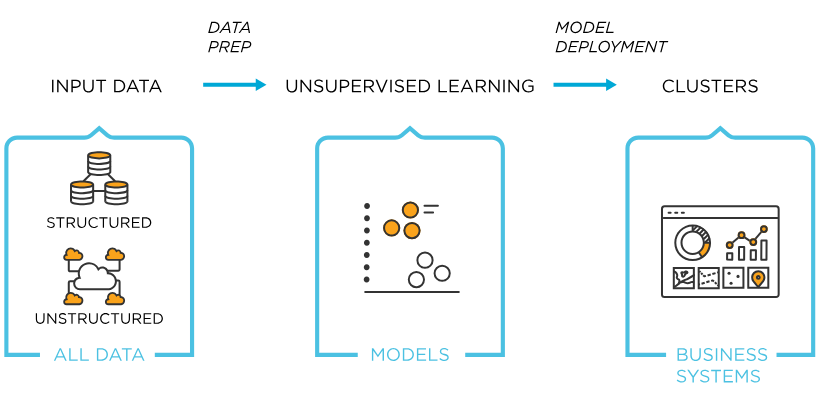
데이터 포인트과 중심점 사이의 거리를 기반으로 각 군집의 기준을 설정K는 군집의 개수, Means는 군집에 선택된 데이터 포인트들의 평균(중심점)초기 개수 설정에 따라 결과가 많이 달라짐정답 레이블이 없어서, 최적의 군집을 알기 어려움여러번 실험을 반복해 최적의 군집을
5.[ML] 지도학습
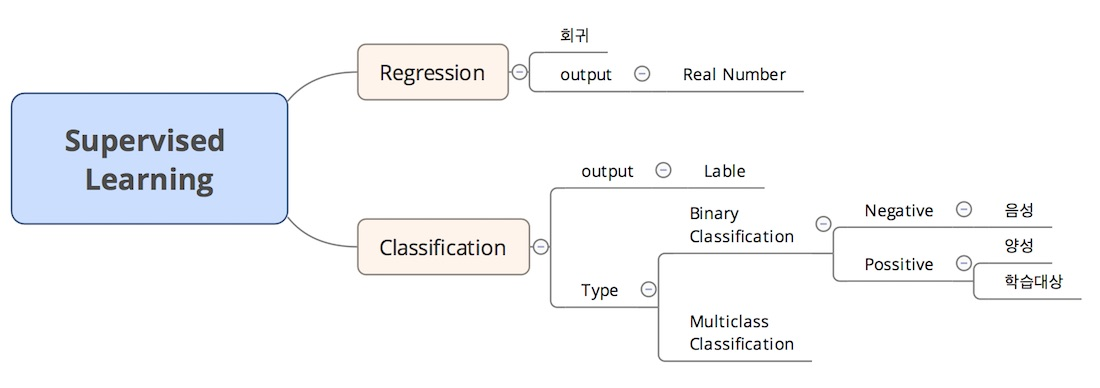
지도학습 정답 label을 적절하게 예측하도록 학습하는 머신러닝 방법 분류(Classification)와 회귀(Regression) 특성 공학(Feature Engineering) GIGO(Garbage In, Garbage Out) 데이터나 변수들을 중복되지 않고,
6.[ML] Scikit-Learn 실습: FIFA22 축구 선수 포지션 분류 예제
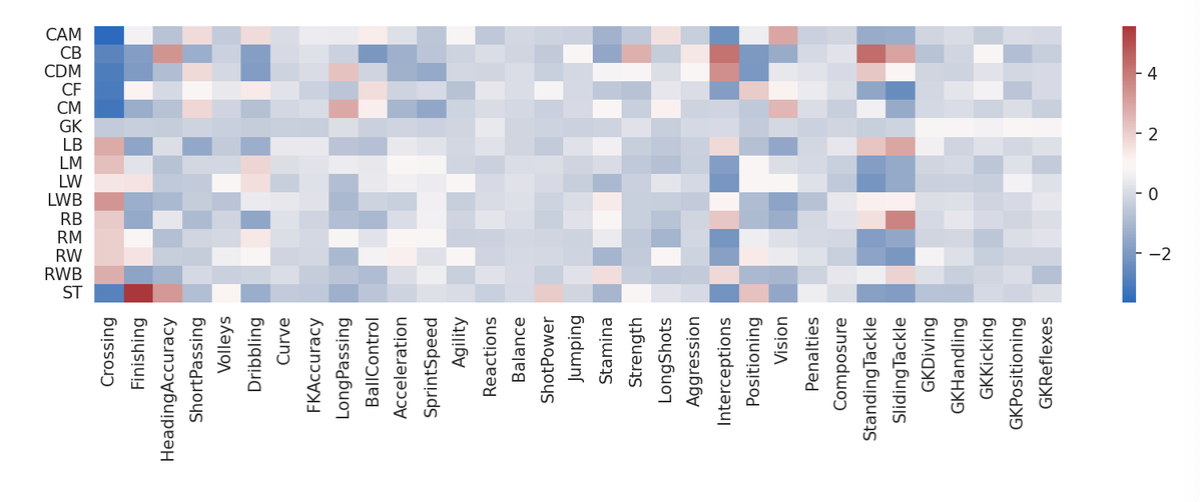
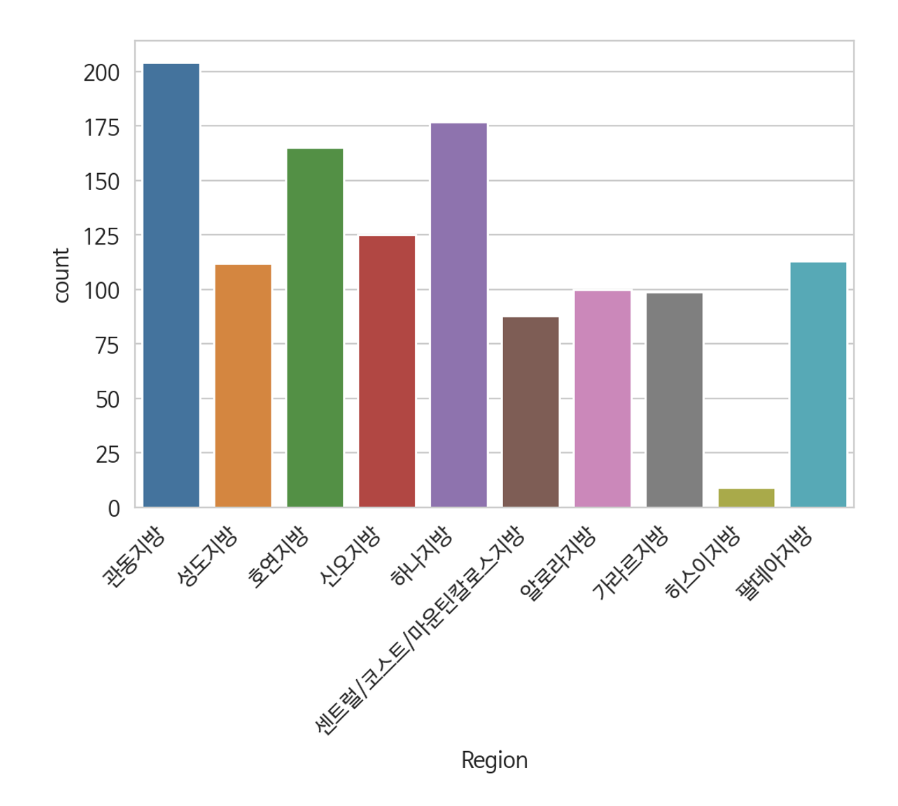
1. EDA 1.1 라이브러리 임포트 시각화를 도와줄 라이브러리를 불러옴 를 통해 시각화 결과물에 대한 기본 설정 가능 1.2 데이터 임포트 를 지정 축구선수별로 기본적인 정보와 능력치 등 65개의 컬럼 존재, 데이터는 16710개 를 통해 데이터 타입과 결측치 확