출처 | LG CNS
머신러닝 흐름
전체적인 머신러닝 과정에 대한 글이다. 흐름은 다음과 같다.
데이터셋 분할 ➜ ML모델 정의 ➜ .fit() 으로 학습 ➜ 변환값 적용 ➜ 테스트
그리고 조금 주목해야할 점은 4번 변환값 적용인데,
비지도 학습의 경우 보통 .transform()을,
지도 학습의 경우 보통 .predict()를 활용해 변환값을 적용한다.
knn.fit(X_train, y_train): fit은 x트레인으로 y트레인
y_pred = knn.predict(X_test): predict는 x테스트로 y_pred
accuracy = accuracy_score(y_test, y_pred): 예측이랑 정답지랑 비교해서 acc 구해
코드 보면 코드 이해가 술술될 수 있도록 하자
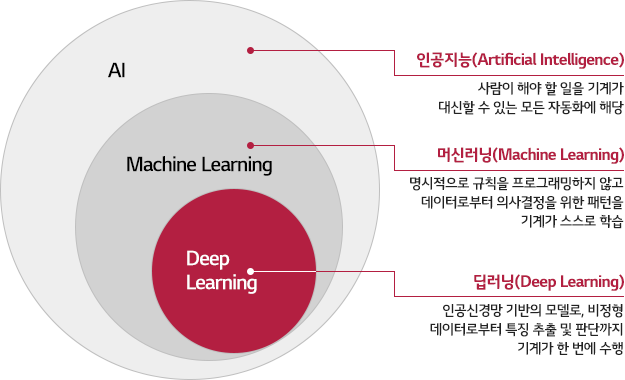
머신러닝
기계가 스스로 데이터 속의 규칙성을 발견하는 알고리즘
비지도학습
-
군집화 (Clustering)
‣ 군집화 알고리즘: K-Means Clustering, DBSCAN -
차원축소 (Dimension Reduction)
‣ 차원이 너무 큰 경우, 차원 축소를 통해 정답 데이터를 잘 설명할 수 있는 주요 특성만 남김
‣ 차원축소 알고리즘: PCA, t-SNE
지도학습
-
과소적합: 훈련 데이터와 테스트 데이터 모두에서 준수하지 못한 성능이 나오는 것
-
과대적합: 모델이 훈련 데이터에서는 준수한 성능을 보이나 테스트 데이터에서는 그렇지 못한 경우
-
분류(Classification)와 회귀(Regression)
‣ 모델: K-NN, Decision Tree, Random Forest, SVM, Naive Bayes, XGB
Scikit-Learn 머신러닝
- 머신러닝 라이브러리
- 데이터 전처리, 모델 평가 및 선택, 모델 최적화 등의 작업을 지원
머신러닝 간단한 과정
#Scikit-Learn에서 제공하는 여러 데이터셋 불러오기
from sklearn import datasets
from sklearn.model_selection import train_test_split
#Scikit-Learn에서 제공하는 기본 데이터셋 불러오기
iris = datasets.load_iris()
X = iris.data
y = iris.target
#k-nearest neighbors 모델 생성
knn = KNeighborsClassifier(n_neighbors=3)
#X_train으로 y_train
knn.fit(X_train, y_train)
#X_test데이터를 이용한 y_pred 예측값 도출
y_pred = knn.predict(X_test)
#모델의 acc계산
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)1. 데이터셋 분할
#훈련 / 테스트 데이터 나누기
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# test_size는 1을 기준으로 계산됩니다. 0.2인 경우 20%를 테스트 데이터로 활용하겠다는 의미
#X_train, X_test, y_train, y_test 순서로 지정2. sklearn에서 모델 불러오고 정의하기
#분류를 위한 K-NN 알고리즘 불러오기
from sklearn.neighbors import KNeighborsClassifier
from sklearn.metrics import accuracy_score
knn = KNeighborsClassifier(n_neighbors=3)3. .fit() 함수로 모델 학습시키기
knn.fit(X_train, y_train)
# 학습은 모델을 데이터에 적합(fit)시키는 과정4. .transform() 또는 .predict()함수로 변환값 적용하기
- 비지도학습: .transform()
- 지도학습: .predict()
y_pred = knn.predict(X_test)
#모델에 따라 사용하는 함수가 다름
비지도 학습의 경우 보통 .transform()을
지도 학습의 경우 보통 .predict()를 활용합니다.from sklearn.linear_model import LogisticRegression
#로지스틱 회귀 모델을 생성하고 예측
model = LogisticRegression()
model.fit(X_train, y_train) # 학습 데이터를 사용하여 모델 훈련
predicted_labels = model.predict(X_test) # 테스트 데이터에 대한 예측5. 테스트 데이터로 성능 평가
accuracy = accuracy_score(y_test, y_pred)
print("Accuracy:", accuracy)
#지도 학습의 경우, 분류와 회귀 문제로 나뉘는데
이때 활용할 수 있는 성능 평가 함수가 달라질 수 있음
#비지도 학습의 경우 이 과정이 필요없는 경우가 많음+위 머신러닝 흐름에서 특성 공학, 하이퍼파라미터 튜닝 등 세부적인 작업이 추가됨
[출처 | 딥다이브 Code.zip 매거진]
