데이터프레임을 형성하고, 시각화하는 과정을 담은 글이다.
나는 인덱싱하는 부분이 조금 헷갈려서 더 정리를 해보았다.
df.loc[:, ['#', 'Name', 'Type']] 은 컬럼의 이름으로 뽑아와서 df만드는 것이고,
df.iloc[:, [0, 1, 3 ]]은 컬럼의 순서로 뽑아와서 df은 만드는 것인데, 이때 처음 열인 index는 컬럼으로 안치니까 빼고 0번째 열로 세야한다.
sns.plot(data = '데이터 프레임', x = '컬럼명1', y = '컬럼명2') 이건 seaborn시각화의 기본적인 구조이고 우선 데이터를 볼때 pairplot을 그리고 시작하는 것도 방법이라는 것
sns.pairplot( df[ ['a'], ['b'],['c'],,, ] 이런건 외워두자~!!
Pandas 데이터 핸들링
Pandas는 데이터의 형태가 기본적인 리스트가 아닌 배열 (Array) 형태로 되어 있음
1. 데이터 프레임 생성
import pandas as pd
#빈 데이터 프레임 생성
df = pd.DataFrame()
#빈 괄호 안에 리스트, 튜플, 딕셔너리 형태의 데이터가 들어갈 수 있음- 리스트 / 튜플 형태
#리스트: 각 element가 []로 저장
pokemon_list = [[1, '이상해씨', '관동지방', '풀 독', 318],
[2, '이상해풀', '관동지방', '풀 독', 405],
[3, '이상해꽃', '관동지방', '풀 독', 525]]
#튜플: 각 element가 ()로 저장
pokemon_tuple = [(1, '이상해씨', '관동지방', '풀 독', 318),
(2, '이상해풀', '관동지방', '풀 독', 405),
(3, '이상해꽃', '관동지방', '풀 독', 525)]
#pd.DataFrame(데이터, columns=[ , , , ]) 형식임
df = pd.DataFrame(pokemon_list, columns = ['#', 'Name', 'Region', 'Type', 'Total'])
df = pd.DataFrame(pokemon_tuple, columns = ['#', 'Name', 'Region', 'Type', 'Total'])- 딕셔너리 형태
- 인덱스인 '#'도 맨 처음으로 포함해서 작성
pokemon_dict = {'#': [1, 2, 3],
'Name': ['이상해씨', '이상해풀', '이상해꽃'],
'Region': ['관동지방', '관동지방', '관동지방'],
'Type': ['풀 독', '풀 독', '풀 독'],
'Total': [318, 405, 525]}
df = pd.DataFrame(pokemon_dict)2. 데이터 정보 확인
#null 값과 데이터 타입 확인
df.info()
#df의 간략한 통계정보
df.describe()3. 인덱싱
- df.loc[ ] 로 인덱싱하기
#loc은 location(위치) 의미
#: 는 전체 범위 의미
df.loc[:, ['#', 'Name', 'Type']] >> 저 3개의 열을 가진 df만 추출- df.iloc[ ] 로 인덱싱하기
#i는 integer를 의미
df.iloc[:, [0, 1, 3 ]] >> index는 컬럼으로 안치므로 0번째 열, 1번째 열, 3번째 열만을 가진 df만 추출- df[[’컬럼명1’, '컬럼명2']] 로 컬럼 인덱싱하기
df[['#', 'Name', 'Type']]
#만약 컬럼만 필요한 경우에는 Key 값을 검색하듯이 찾을 수 있음.
df['Name']
#컬럼 하나만 추출하고 싶은 경우4. 중복값 제거
중복값 확인
#중복값 확인, 열(subset)이 #인 애들의 중복값 확인
df.duplicated(subset = ['#']) >>> True, False로 반환중복값 제거: df.duplicated(subset = ['#'])
#중복값 제거
df.drop_duplicates() # 아무것도 삭제되지 않음
df.drop_duplicates(subset = ['#'])5. 컬럼
컬럼명 변경
#컬럼명 확인 및 변경
print(df.columns) # 현재 컬럼명이 출력됩니다.
df.columns = ['#', 'Name', 'Region', 'Type', 'Total']컬럼 연산
#벡터 연산 가능
df['물리능력'] = df['공격'] + df['방어']
df['특수능력'] = df['특수공격'] + df['특수방어']6. Seaborn 시각화
-
EDA를 위한 시각화
-
Seaborn 라이브러리는 파이썬에서 지원하는 시각화 라이브러리
-
matplotlib.pyplot 위에서 작동
-
Pandas 데이터프레임을 간편하게 시각화
import matplotlib.pyplot as plt import seaborn as sns
(1) Seaborn의 기본적인 구조
-
df 와 df.colums만 입력 하면 된다
sns.plot(data = '데이터 프레임', x = '컬럼명1', y = '컬럼명2')
(2) Countplot | sns.countplot(x=, data=)
- df 와 df.colums만 입력 하면
- x로 지정한 컬럼 내의 값들을 자동으로 카운트
#카운트 막대 그래프
sns.countplot(x = 'Region', data = df)
plt.show() 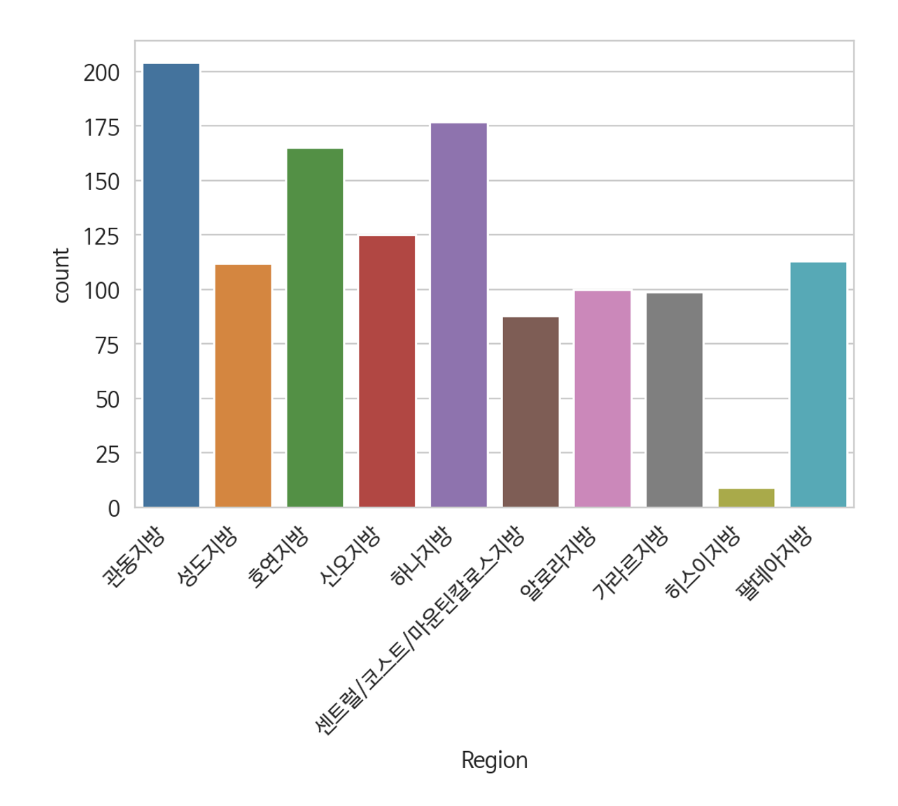
(3) Boxplot | sns.boxplot(x=, y=, data=)
- x와 y값 모두 필요
#박스 플롯
sns.boxplot(x = 'Type_1', y = 'Total', data = df)
plt.show()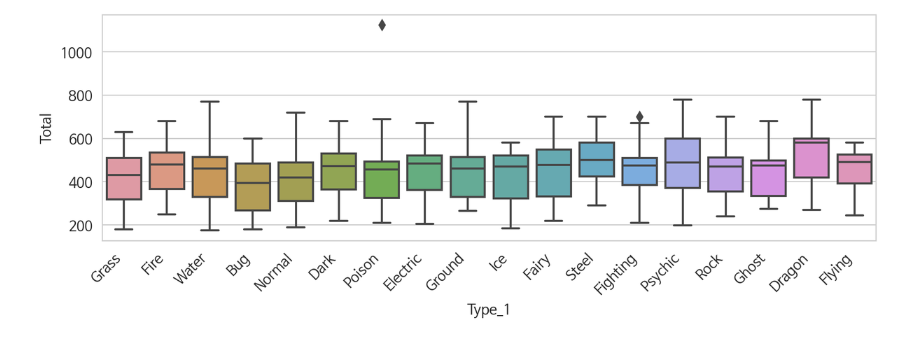
(4) Scatterplot | sns.scatterplot(x=, y=, data= )
- 스캐터 플롯을 그릴 때는 x, y의 변수가 모두 연속형이어야 합니다.
#산포도(스캐터 플롯, Scatter Plot)
sns.scatterplot(x = 'Defense', y = 'Speed', data = df)
plt.show()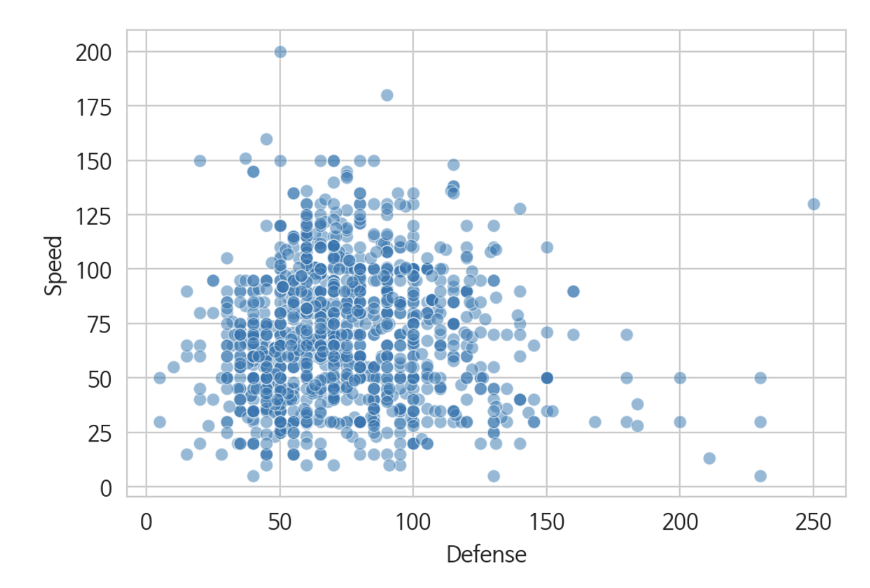
(5) Pairplot | sns.pairplot( df[ ['a'], ['b'],['c'],,, ]
- pairplot은 일일이 연속형 변수를 지정하지 않아도, 자동으로 변수의 형태를 찾아 산포도와 히스토그램을 그림
- 우선 pairplot을 그리고 시작하는 것도 방법임
#연속형 데이터의 산포도와 히스토그램
sns.pairplot( df[ ['HP', 'Attack', 'Defense', 'Sp. Atk', 'Sp. Def', 'Speed'] ] ) 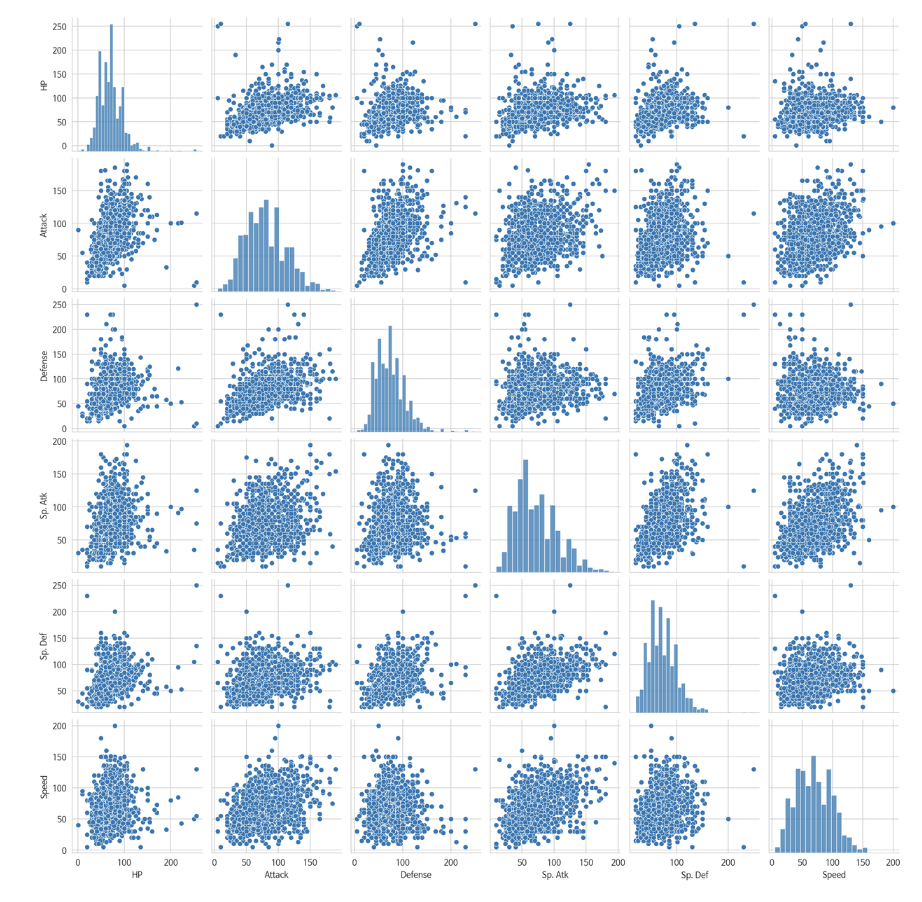
[출처 | 딥다이브 Code.zip 매거진]

@fragrance_0의 개발로그