그동안 복습한 내용들을 바탕으로 머신러닝 실습을 진행해볼 것이다.
피파 선수들의 능력치를 바탕으로 Best Position을 예측하는 실습이다.
항상 느끼는 건, 내가 뭘 하고자 하는지를 정확하게 알고 가는 것이 중요하다는 것이다. 가장 중요한 Target을 설정하는 부분은 제대로 머릿속에 담고 가면서 분석을 해야한다. 휘황찬란한 분석 방법때문에 내가 뭘 해야하는지 놓치고 가면, 산으로 가버린다. 그래서 차분히 EDA를 하는 과정이 꼭 필요한 것 같다.
그리고 분석을 해가면서 가장 필요성을 느낀 부분은, 모델학습을 할 때 먼저 Pipeline을 만들어 제대로 적용해야한다는 점이다. 보통 훈련 데이터의 성능을 높이는 방향으로 많이 진행하는데, 결국엔 train과 test데이터에 동일한 전처리를 진행해야 의도한 결과가 나오기 때문에 Pipeline을 설계하는 것이 편리하고 중요하다. 또한, 다양한 하이퍼파라미터튜닝법을 통해 분석을 쪼개서 제대로 하고, 성능을 높이는 것도 정말 필요한 과정이라고 생각이 들었다.
1. EDA
1.1 라이브러리 임포트
- 시각화를 도와줄 라이브러리를 불러옴
sns.set_style('whitegrid')를 통해 시각화 결과물에 대한 기본 설정 가능
# 기본적으로 필요한 시각화 라이브러리를 불러오기
from matplotlib import font_manager, rc, rcParams
import matplotlib.pyplot as plt
import seaborn as sns
# 시각화 설정
sns.set_style('whitegrid')
# Pandas 및 정규표현식 불러오기
import pandas as pd
import re
1.2 데이터 임포트
path를 지정- 축구선수별로 기본적인 정보와 능력치 등 65개의 컬럼 존재, 데이터는 16710개
import os
path = '/content/drive/MyDrive/...'
filename = 'FIFA22_official_data.csv'
df = pd.read_csv(os.path.join(path, filename) , encoding = 'utf-8'); df
df.info()를 통해 데이터 타입과 결측치 확인 가능
1.3 데이터 탐색
- Target 설정 데이터: 포지션 예측
- 컬럼에 포지션 관련 정보 2개 존재
# 포지션 예측을 위한 컬럼 확인
df[['Name','Position','Best Position']]-
Best Position을 예측하기로 결정 -> Target -
포지션 확인
print(df['Best Position'].unique(), '포지션 개수', len(df['Best Position'].unique()), '개')
>>>
['CAM' 'CM' 'ST' 'LB' 'CDM' 'CB' 'RB' 'LM' 'RW' 'LW' 'CF' 'LWB' 'RM' 'RWB' 'GK']
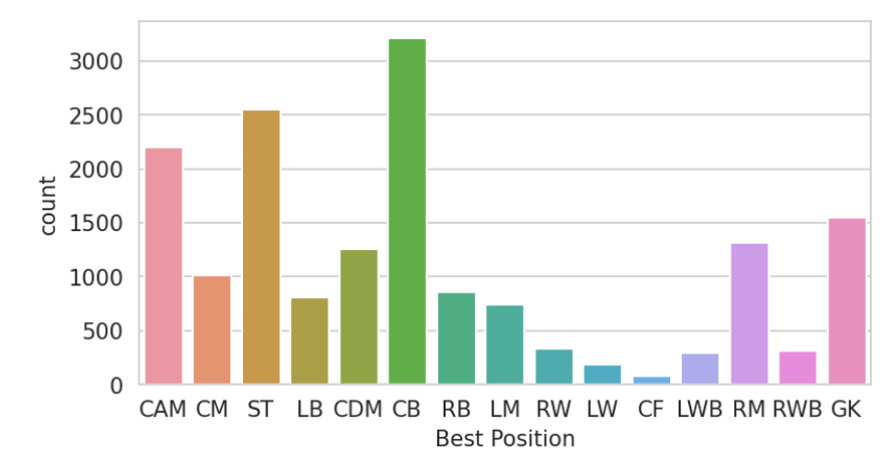
포지션 개수 15 개- 포지션별 카운트 및 시각화 ⇒ 데이터가 전체적으로 불균형함을 알 수 있음
# 포지션별 카운트
plt.figure(figsize = (6,3), dpi = 150)
sns.countplot(x = df['Best Position'], data = df)
plt.show()
2. 데이터 전처리
2.1 데이터 인코딩
- 분류문제 해결을 위해 클래스명을 숫자로 변환
- 사이킷런에서 제공되는
LabelEncoder사용
# 데이터 레이블 인코딩
from sklearn.preprocessing import LabelEncoder
encoder = LabelEncoder() # 레이블 인코더는 정수 인덱스로 바꿈
# 정답 레이블 인코딩
y = encoder.fit_transform(df['Best Position']);y
# 정답 레이블을 정수 인덱스로 반환함
# 다시 정수를 문자열로 알아보고 싶다면 encoder.inverse_transform(y)를 실행
- 세미콜론(;)은 파이썬에서 여러 문장을 한 줄에 작성할 때 사용할 수 있는 구분자
- 세미콜론을 사용하지 않고 코드를 여러 줄로 나누어 작성해도 동일한 결과를 얻음
- 학습 데이터 설정
⇒df.info()를 통해 확인 가능 - 27번부터 61번까지가 선수 능력에 관한 컬럼임을 확인
⇒ 인덱스 기능을 활용해27:61까지 학습데이터로 설정
# 컬럼 인덱스 확인하기
for i, v in enumerate(df.columns):
print(i, v)
# 학습 데이터 생성
x = df.iloc[:,27:61]; x
- 결측치 개수 확인
# 결측치 개수 확인
x.isnull().sum()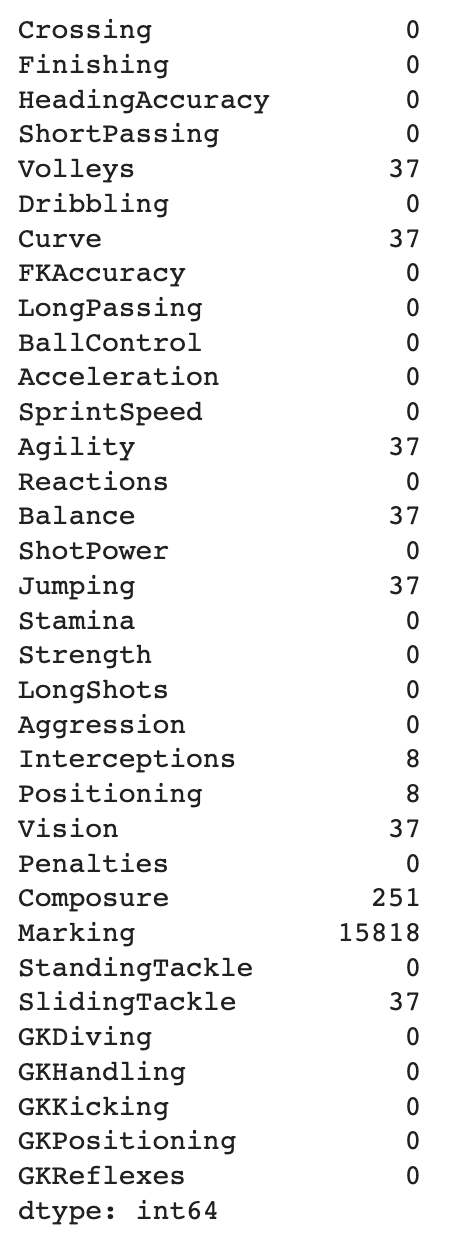
- 너무 많은 결측치를 가지고 있는
Marking은 분석에 방해가 되므로axis 1로 제거 inplace = True중요!!axis=0은 행 방향으로 동작하고,axis=1은 열 방향으로 동작
inplace = True는 기존 데이터 프레임에 변경된 설정으로 덮어쓰겠다는 의미
# 컬럼 제거
x.drop('Marking', axis = 1, inplace = True)
- 다른 결측데이터인 'Volleys' 확인
# 결측 데이터 확인
df[df['Volleys'].isnull()]
# 은최한 선수임을 알 수 있음2.2 데이터 보간
- 결측 데이터가 있으면 분석에 영향을 줌
- 다양한 보간(Interpolation) 방법 존재
- Pandas에서 사용되는 "선형 보간법" 적용
axis = 1열로 보간
# 결측 데이터 보간
x.interpolate(axis = 1, inplace = True)□ 선형 보간법 ⇢ 두 포인트 사이의 직선 상에 있는 값을 추정하여 보간하는 방법
import pandas as pd
data = {'x': [0, 2, 4, 6, 8],
'y': [1, None, 9, None, 25]}
df = pd.DataFrame(data)
df.interpolate()
>>>
x y
0 0 1.0
1 2 5.0
2 4 9.0
3 6 17.0
4 8 25.0
2.3 학습-훈련 데이터셋 분리
- 사이킷런 패키지 중
train_test_split를 활용 x변수와y변수를 따로 지정하여 총 4개의 변수를 구함
⇒x_train, x_test, y_train, y_test- 전체 데이터 중 test 데이터셋의 크기를 30%로 지정함
# 학습-훈련 데이터셋 분리
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size = 0.3, random_state = 319)
3. 모델 학습
3.1 스케일링
- 데이터 전처리 결과를 데이터 자체에 반영할 수도 있지만, 모델 파이프라인을 만들어 적용할 수 있음
- 보통 훈련 데이터의 성능을 높이는 방향으로 전처리하지만, 동일한 전처리 방법을 테스트 데이터에도 적용해야 의도한 결과가 나올 수 있다.
- 이를 위해 전처리부터 학습까지 하나의 모델로 적용할 수 있는 파이프라인을 설계하는 것이 편리
⇒ Scaling으로 더 많은 함수들을 적용할 수도 있지만, 여기서는 빠른 훈련을 위해 데이터를 표준화하는 함수만 반영함
□ 데이터 표준화 ⇢ 사이킷런에서 제공하는 StandardScaler()를 활용
- Standard Scaling은 데이터 전체 평균을 빼고 표준편차로 나누는 정규화 과정을 반영하는 것, 이를 통해 모든 특성의 스케일을 동일하게 만들며, 데이터를 정규 분포에 가깝게 만듦
# 파이프라인 설정_여기서는 StandardScaler() 사용
pipeline = Pipeline([('scaler', StandardScaler()),
('lr', LogisticRegression(solver = 'lbfgs', max_iter = 1000))
])
- 'scaler'라는 이름을 가지고, StandardScaler()를 사용
- 'lr'이라는 이름을 가지고, LogisticRegression 모델을 설정
'lbfgs' 최적화 알고리즘과 최대 반복 횟수 1000으로 설정
3.2 Logistic Regression
- 표준화된 데이터를 모델에 적용
Logistic Regression은 각 특성별로 가중치를 결정하고 각각의 가중치와 특성을 가중합하여 결정을 내립니다. 아마도 Logistic Regression의 이런 특징 때문에 성능이 높게 나오지 않았을까 싶습니다.
# Logistic Regression
from sklearn.linear_model import LogisticRegression
pipeline.fit(x_train, y_train)
y_pred = pipeline.predict(x_test)
acc = accuracy_score(y_test, y_pred)
print('Logistic Regression 모델의 정확도:', '%.4f'%acc)
>>> Logistic Regression 모델의 정확도: 0.7578
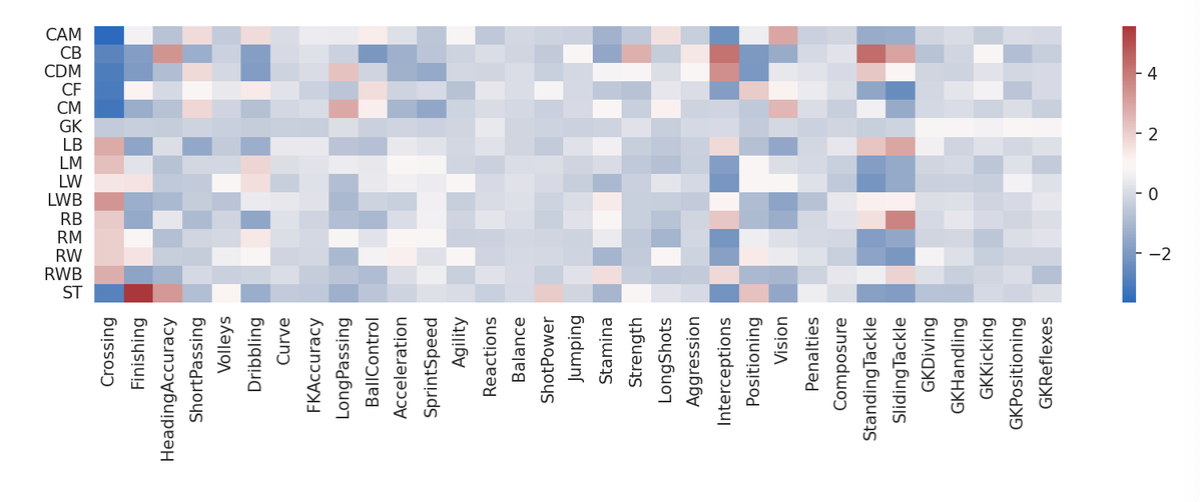
3.2 Logistic Regression 가중치 시각화
- 파이프라인에서 'lr'이라는 이름으로 지정된 로지스틱 회귀 모델의 계수(coefficients)를 추출하고, 데이터프레임으로 변환하는 과정을 거침
pipeline['lr'].coef_: 로지스틱 회귀 모델의 계수
x_train.columns: 입력 특성들의 이름
encoder.inverse_transform(range(15))는 레이블 역변환을 통해 '0'에서 '14'까지의 클래스 레이블을 다시 원래의 범주형 레이블로 변환한 것
⇒ 예측값이 15개임
# Logistic Regression의 계수
# 'lr'이라는 이름으로 파이프라인에서 로지스틱 회귀 모델의 계수를 추출하고, 데이터프레임으로 변환
matrix = pd.DataFrame(pipeline['lr'].coef_, columns = x_train.columns,
index = encoder.inverse_transform(range(15)))
plt.figure(figsize = (13,3), dpi = 150)
# 'matrix'는 계수 데이터프레임, 'cmap'는 사용할 색상 맵
sns.heatmap(matrix, cmap = 'vlag')
plt.show()
4. 하이퍼파라미터 튜닝
4.1 GridSearch
- 하이퍼파라미터는 연구자가 직접 조절해야 할 파라미터를 의미
GridSearch는 일일이 수작업으로 해야 하는 것을 변수만 넣으면 쉽게 작동하도록 만든 모델임
# 하이퍼파라미터 설정
solvers = ['newton-cg', 'lbfgs', 'liblinear', 'sag', 'saga']
c_values = [100, 10, 1.0, 0.1, 0.01]
# GridSearch 적용
grid = dict(lr__solver = solvers, lr__C = c_values)
- solvers 리스트: 로지스틱 회귀 모델의 최적화 알고리즘인 solver에 대한 여러 옵션을 포함
- c_values 리스트: 로지스틱 회귀 모델의 규제 강도를 나타내는 하이퍼파라미터인 C에 대한 여러 가능한 값들을 포함
- grid 딕셔너리: 그리드 탐색을 설정하기 위한 파라미터 그리드를 정의
➣ 가능한 모든 하이퍼파라미터 조합을 시도하여 최적의 조합을 찾음
➣ 딕셔너리의 키는 파이프라인에서 사용한 모델의 이름과 하이퍼파라미터 이름을 조합한 것임
➣lr__solver는 로지스틱의 최적화 알고리즘(solver)을 나타내며,lr__C는 규제 강도(C)를 나타냄
➣ 각 키에 대한 값은 해당 하이퍼파라미터에 대한 여러 가능한 값들을 리스트로 지정함.
4.2 Cross Validation
- 교차검증은 모델의 성능을 평가하는 방법 중 하나
- 주어진 데이터를
train_test_split하고, 이를 반복해서 모델의 성능을 검증 - 모델의 일반화 성능 측정 & 과적합 예방
□ K-Fold Cross Validation
⇢ 데이터를 K개의 Fold로 분할하고, 각 Fold 를 한번씩 테스트셋으로 이용하면서 나머지 (K-1)개의 폴드를 훈련 데이터로 사용
⇢ 이 과정을 K번 반복하여 K개의 성능 추정치를 얻게 됨
⇢ K개의 성능 추정치의 평균을 최종 성능 추정치로 사용
□ Stratified K-Fold 교차 검증
⇢ 각 클래스의 비율이 훈련-테스트 데이터셋에서 동일하게 유지되도록 폴드를 구성하는 방식
⇢ 불균형한 분포를 가진 데이터셋에 특히 유용함
# CrossValidation 설정
cv = StratifiedKFold(n_splits=3, random_state = 319, shuffle = True)
# GridSearchCV 학습
grid_search = GridSearchCV(estimator=pipeline, param_grid=grid, n_jobs=-1, cv=cv, scoring='accuracy', error_score=0)
grid_result = grid_search.fit(x_train, y_train)
4.3 하이퍼파라미터 튜닝 결과
K-Fold Cross Validation으로 구한 결과 중에서 가장 높은 값을 보인 파라미터가 C = 1.0 solver = ‘lbfgs’입니다.
# 결과 요약
print("Best: %f using %s" % (grid_result.best_score_, grid_result.best_params_))
means = grid_result.cv_results_['mean_test_score']
stds = grid_result.cv_results_['std_test_score']
params = grid_result.cv_results_['params']
for mean, stdev, param in zip(means, stds, params):
print("%f (%f) with: %r" % (mean, stdev, param))
>>> Best: 0.799094 using {'lr__C': 1.0, 'lr__solver': 'lbfgs'}
[출처 | 딥다이브 Code.zip 매거진]
