TIL
1.TIL 211002
: 결정에 다다르기 위해 예/아니오 질문을 이어 나가면서 학습 (스무고개)\-> 계층적으로 영역을 분할해가는 알고리즘노드: 질문이나 정답을 담은 네모 상자리프: 마지막 노드루트 노드: 맨 위의 노드 (전체 데이터 포함)순수 노드: 타깃 하나로만 이루어진 리프 노드결정
2.TIL 211003
.png)
1. 배깅, 엑스트라 트리, 에이다부스트 (2.3.7) : scikit-learn이 제공하는 다른 앙상블 알고리즘 1. 배깅 Bagging : 중복을 허용한 랜덤 샘플링으로 만든 훈련 세트(부트스트랩 샘플)를 사용하여 분류기를 각기 다르게 학습시킴 분류기가 predi
3.TIL 211004
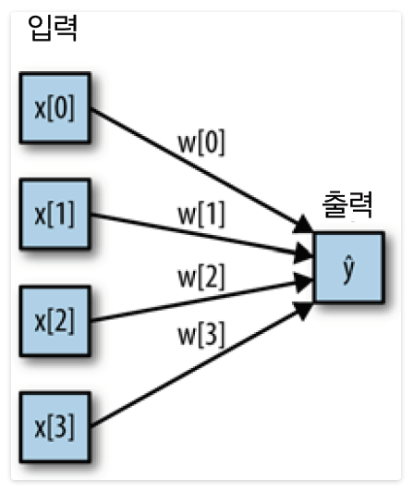
: 알고리즘 中 하나 -> 딥러닝다층 퍼셉트론 Multilayer perceptrons, MLP: 딥러닝 알고리즘의 출발점:여러 단계를 거쳐 결정을 만들어냄왼쪽 노드: 입력 특성을 나타내며 연결선은 학습된 계수를 표현오른쪽 노드: 입력의 가중치 합 = 출력\-> MLP
4.TIL 211025

요즘 코드를 보면서 느낀 게,분명 저번에 푼 문제에서 비슷하게 변형하면 되는데 그 응용력이 조금 떨어지는 느낌이랄까.: 문제는 쉬웠다. 배열이 주어진다. 이 배열에서 0과 9사이의 숫자 중 없는 숫자를 더해 그 합을 도출하는 것이다.사실 이 문제는 보고이것만 보고 바로
5.TIL 211107

드디어 Chapter 4!!!사실 앞의 지도 학습, 비지도 학습은 들어봤는데, 이 데이터 표현과 특성 공학은 처음 들어봐서 무엇을 배울지 기대된다~!그럼 시작!지금까지 다룬 데이터: 연속형 특성일반적인 데이터: 범주형 특성 = 이산형 특성 (보통 숫자값 X)BUT,데이
6.TIL 211112

어짜피 적어야 하는 팀블로그 !!!그래서 팀블로그 말투로 적기로 하였다 !!!(이쯤 드는 생각이 velog는 GDSC 준비를 위해 쓰는 게 아닐까...)지난 주에는kaggle (https://www.kaggle.com/arthurtok/introduction-
7.TIL 211114
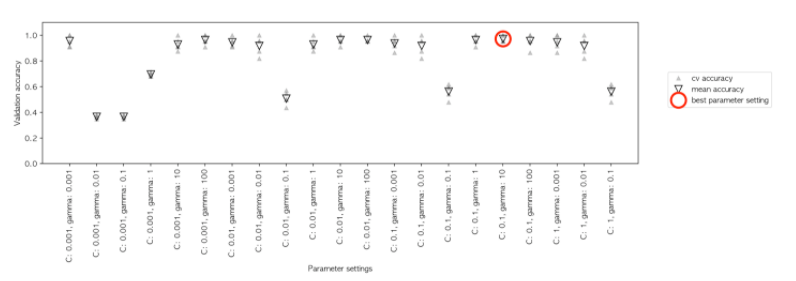
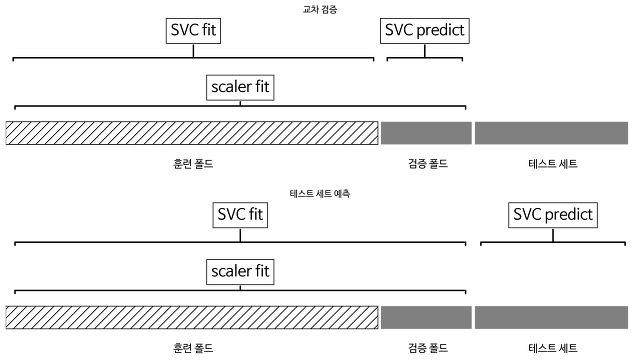
원래 어제 쓰려고 했는데 너무 피곤해서 그만...그 사이에 토리가 책을 좀 찢어놨다...여튼 다시 팀블로그 기록 시작!앞서 우리는 모델의 성능을 평가하는 방법을 배웠습니다. 그럼 그 평가 점수를 기반으로 우리는 더 좋은 성능을 낼 수 있는 모델을 만들어야겠죠? 이때 매
8.TIL 211121
팀플 뿌쎠버리고 싶다 ~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!너무너무 싫다 ~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!~!팀플 때문에 할 일도 밀렸다 ~!~!~!~!~!~!~!~!~!~!~!~!
9.2.2 일반화, 과대적합, 과소적합
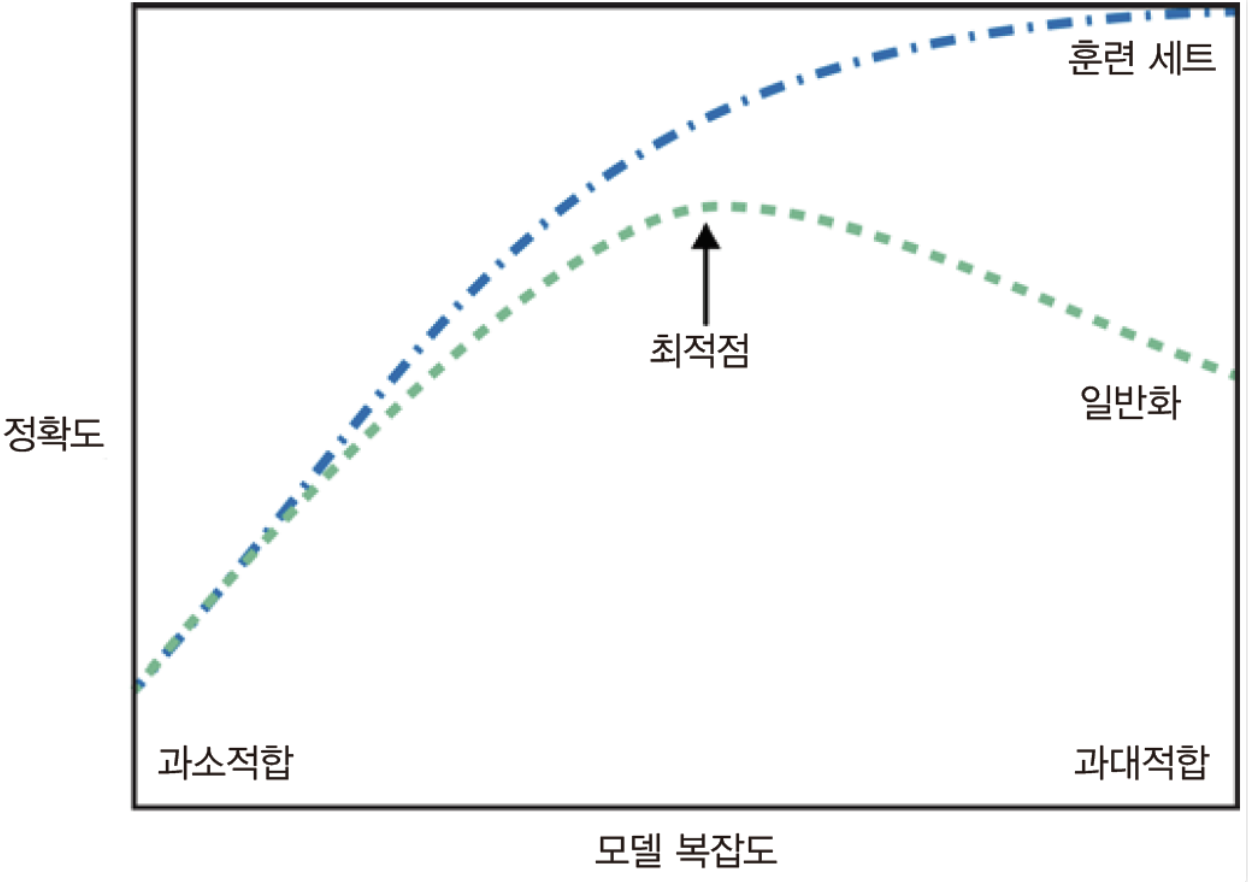
일반화: 모델이 처음 보는 데이터에 대해 정확하게 예측할 수 있으면 이를 훈련 세트에서 테스트 세트로 일반화 되었다고 함과대적합: 모델이 훈련 세트의 각 샘플에 너무 가깝게 맞춰져서 새로운 데이터에 일반화되기 어려울 때 나타남과소적합: 너무 간단한 모델을 선모델 복잡도
10.250730 TIL: Debug 모드에서의 ModuleNotFoundError

앞으로 (거의 무조건) 평일에는 TIL을 작성해볼까 한다. 학부생 때 동아리 하면서는 한 번씩 했는데, 정말 눈코 뜰새 없이 바빠지니까 그것마저 힘들다는 걸 핑계로 안한 것 같다. 그런데 내가 무얼 배웠는지, 분명 본 오류인데 해결하지 못할 때마다 회의감이 들었다. 다시 배웠다는 그 마음으로 날 채워보자! 작성 시점은 하루 지난 31일이지만 ... 30일...