원래 어제 쓰려고 했는데 너무 피곤해서 그만...
그 사이에 토리가 책을 좀 찢어놨다...
여튼 다시 팀블로그 기록 시작!
2. 그리드 서치
앞서 우리는 모델의 성능을 평가하는 방법을 배웠습니다. 그럼 그 평가 점수를 기반으로 우리는 더 좋은 성능을 낼 수 있는 모델을 만들어야겠죠? 이때 매개변수를 튜닝하여 일반화 성능을 개선해보도록 하겠습니다.
많이 하는 작업이라, scikit-learn에서는 이를 위한 메서드가 준비되어 있습니다. 그리드 서치는 그 중에서도 가장 많이 사용하는 방법인데요, 정의는 다음과 같습니다.
관심 있는 매개변수들을 대상으로 가능한 모든 조합을 시도해보는 작업
1. 간단한 그리드 서치
두 매개변수 조합에 대해 분류기를 학습시키고 평가하는 간단한 그리드 서치를 for 문을 사용해 만들 수 있습니다.
SVC 파이썬 클래스에 구현된 RBF 커널 SVM에서는 gamma와 C가 중요한데, 이를 for 문을 통해 구현해보면,
best_score = 0
for gamma in [0.001, 0.01, 0.1, 1, 10, 100]:
for C in [0.001, 0.01, 0.1, 1, 10, 100]:
svm = SVC(gamma = gamma, C = C)
svm.fit(X_train, y_train)
score = svm.score(X_test, y_test)
if score > best_score:
best_score = score
best_parameters = {'C': C, 'gamma':gamma}2. 매개변수 과대적합과 검증 세트
앞서 소개한 방법은 이 방법이 새로운 데이터에 이어지지 않을 수 있습니다. 매개변
수를 조정하기 위해 테스트 세트를 이미 사용했기 때문에 모델이 얼마나 좋은지 평가할 수 없습니다. 즉, 평가를 위해서는 모델을 만들 때 사용하지 않은 독립된 데이터셋이 필요합니다.
이 문제를 해결하기 위해 우리는 데이터를 세 세트로 나눌 수 있습니다.
- 훈련 세트
- 검증 또는 개발을 목적으로 한 세트 (매개변수 선택)
- 테스트 세트 (매개변수 성능 평가)
이렇게 훈련 세트, 검증 세트, 테스트 세트의 구분은 실제 머신러닝 알고리즘을 적용하는 데 아주 중요합니다. 테스트 세트 정확도에 기초해 어떤 선택을 했다면, 테스트 세트의 정보를 모델에 누설한 것입니다. 그렇기 때문에 최종 평가에만 사용하도록 테스트 세트를 분리하는 것이 중요한 것이죠.
3. 교차 검증을 사용한 그리드 서치
데이터를 위와 같이 세 세트로 나눈 방법은 매우 민감합니다. 일반화 성능을 더욱이 잘 평가하기 위해서는 훈련 세트와 검증 세트를 한 번만 나누지 않고 앞서 배운 교차 검증을 사용하여 각 매개변수 조합의 성능을 평가할 수 있습니다.
for gamma in [0.001, 0.01, 0.1, 1, 10, 100]:
for C in [0.001, 0.01, 0.1, 1, 10, 100]:
svm = SVC (gamma = gamma, C = C)
scores = cross_val_score(svm, X_trainval, y_trainval, cv = 5)
score = np.mean(scores)
if score > best_score:
best_score = score
best_parameters = {'C': C, 'gamma': gamma}여기서 5-겹 교차 검증과 C, gamma를 다양한 변수로 설정하였으므로 총 36 * 5 = 180 개의 모델을 만들어야 합니다. 단점은 앞선 모델 평가 방식보다 시간이 더 걸린다는 점이겠죠.

이 그림은 최적의 매개변수를 설정하는 방법을 보여줍니다. 여기서 교차 검증 정확도, 즉 validation accuracy가 가장 높은 매개변수를 동그라미로 표시하였습니다. 책의 추가 설명을 빌리자면, 교차 검증은 데이터셋에 대해 주어진 알고리즘을 평가하는 방법입니다. 하지만 그리드 서치와 같은 매개변수 탐색 방법과 합쳐서 많이 사용합니다. 그래서 많은 사람이 교차 검증이란 용어를 교차 검증을 사용한 그리드 서치라는 의미로 주로 사용합니다.
앞서 설명한 내용을 도식화 하면 아래와 같습니다.

scikit-learn의 좋은 점 중 한 가지는 널리 사용하는 방법을 친절히 제공해준다는 것입니다. 교차 검증을 사용한 그리드 서치를 매개변수 조정 방법으로 널리 사용하기 때문에, 추정기 형태로 구현된 GridSearchCV를 제공하고 있습니다.
from sklearn.model_selection import GridSearchCV
from sklearn.svm import SVC
param_grid = {'C': [0.001, 0.01, 0.1, 1, 10, 100], 'gamma': [0.001, 0.01, 0.1, 1, 10, 100]}
grid_search = GridSearchCV(SVC(), param_grid, cv=5, return_train_score = True)매개변수가 과대적합이 되길 방지하기 위해서는 훈련 세트와 검증 세트를 나누는 것이 좋겠죠?
가끔은 만들어진 실제 모델에 직접 접근해야 할 때가 있는데요, 예를 들면 계수나 특성 중요도를 살펴보려고 할 때입니다. 최적의 매개변수에서 전체 훈련 세트를 사용하여 학습한 모델은 bestestimator 속성에서 얻을 수 있습니다. (모델 평가를 위해 best_estimator을 사용할 필요는 없습니다.)
1. 교차 검증 결과 분석
교차 검증의 결과를 시각화 하면 검색 대상 매개변수가 모델의 일반화에 영향을 얼마나 주는지 이해하는 데 도움이 됩니다. 그리드 서치는 연산 비용이 커, 비교적 간격을 넓게 하여 적은 수의 그리드로 시작하는 것이 좋습니다. 그리드 서치의 결과는 검색과 관련한 여러 정보가 함께 저장되어 있는 딕셔너리인 cvresults 속성에 담겨 있습니다.
import pandas as pd
pd.set_option('disply.max_columns', None)
results = pd.DataFrame(grid_search.cs_results_)
display(np.transpose(results.head())results의 행 하나에는 특정한 하나의 매개변수 설정에 대응합니다. 각 설정에 대해 교차 검증의 모든 분할의 평균값, 표준편차를 포함한 결과가 기록되어 있습니다. 매개변수 그리드가 2차원이므로 히트맵으로 시각화 하기 좋습니다.
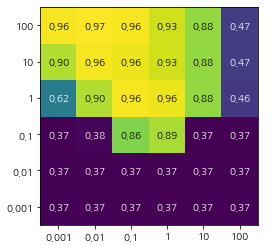
여기서 교차 검증의 정확도가 높으면 밝은 색으로 낮으면 어두운 색으로 나타내었습니다. 이 그래프를 보면 SVC가 매개변수 설정에 매우 민감함을 알 수 있습니다.
여기서 알 수 있는 사실은 매개변수 조정에 따라 정확도가 크게 달라지고, 각 매개변수의 최적값이 그래프 끝에 놓이지 않도록 매개변수의 범위가 충분히 넓게 설정해야 한다는 점입니다.
만약 매개변수의 범위를 넓게 설정하지 않는다면,

이와 같은 결과를 볼 수 있습니다.
2. 비대칭 매개변수 그리드 탐색
어떤 경우에는 모든 매개변수의 조합에 대해 GridSearchCV를 수행하는 것이 좋지 않을 수 있습니다. 예를 들면 SVC는 kernel 매개변수를 가지고 있는데 어떤 커널을 사용하는지에 따라 관련 있는 매개변수들이 결정됩니다.
- linear = C
- rbf = C, gamma
시간 낭비하는 것을 줄이기 위해서 우리는 조건부 매개변수 조합을 적용하여야 합니다. 이는 GridSearchCV에 전달할 param_grid를 딕셔너리의 리스트로 만들어주면 됩니다. 이때, 각 딕셔너리를 독립적인 그리드로 적용됩니다.
param_grid = [{'kernel': ['rbf'],
'C': [0.001, 0.01, 0.1, 1, 10, 100],
'gamma': [0.001, 0.01, 0.1, 1, 10, 100]},
{'kernel': ['linear'],
'C': [0.001, 0.01, 0.1, 1, 10, 100]}]3. 그리드 서치에 다양한 교차 검증 적용
cross_val_score와 비슷하게, GridSearchCV는 분류에는 기본적으로 계층형 k-겹 교차 검증을 사용하고 회귀에는 k-겹 교차 검증을 사용합니다. 또, 훈련 세트와 검증 세트로 한 번만 분할하려면 n_splits = 1로 하고 ShuffleSplit나 StratifiedShffleSplit를 사용합니다. 이런 방법은 데이터셋이 매우 크거나 모델 구축에 시간이 오래 걸릴 때 유용합니다.
4. 중첩 교차 검증
GridSearchCV를 사용할 때 여전히 데이터를 훈련 세트와 테스트 세트로 한 번만 나누기 때문에, 결과가 불안정하고 테스트 데이터의 분할에 크게 의존합니다. 여기서도 물론 교차 검증 분할 방식을 사용할 수 있습니다. 이를 중첩 교차 검증이라고 합니다.
중첩 교차 검증에서는 바깥쪽 루프에서 데이터를 훈련 세트와 테스트 세트로 나눕니다. 그 후 각 훈련 세트에 대해 그리드 서치를 실행합니다. 마지막으로 분할된 테스트 세트의 점수를 최적의 매개변수 설정을 사용해 각각 측정합니다.
이 방법은 모델이나 매개변수 설정이 아닌 테스트 점수의 목록을 만들어줍니다. 그래서 중첩 교차 검증은 미래의 데이터에 적용하기 위한 예측 모델을 찾는 데는 거의 사용하지 않습니다.
5. 교차 검증과 그리드 서치 병렬화
그리드 서치는 데이터 용량이 크고 매개변수 수도 많을 때는 상당한 연산 부하를 일으킵니다. 하지만 쉽게 병렬화할 수 있다는 장점이 있습니다. 하나의 교차 검증 분할에서 특정 매개변수 설정을 사용해 모델을 만드는 일은 다른 매개변수 설정이나 모델과 전혀 상관없이 진행할 수 있기 때문입니다. GridSearchCV와 cross_val_score에서 n_jobs 매개변수에 사용할 CPU 코어 수를 지정할 수 있습니다. n_jobs = -1이면 가능한 모든 코어를 사용합니다.
