어짜피 적어야 하는 팀블로그 !!!
그래서 팀블로그 말투로 적기로 하였다 !!!
(이쯤 드는 생각이 velog는 GDSC 준비를 위해 쓰는 게 아닐까...)
지난 주 과제
지난 주에는
의 두 가지 과제가 있었습니다! 타이타닉에서 벗어날 수 없는 우리 ML...
이번 주에는 Chapter5의 모델 평가와 성능 향상을 다루어볼 예정입니다.
지금까지 우리는 지도 학습, 비지도 학습 이론과 특성 공학에 대해 배웠습니다. 비지도 학습을 평가하는 일은 매-우 정성적인 작업이므로, 이 파트에서는 지도 학습(회귀, 분류)에 집중해보겠습니다.
지금까지 우리는 지도 학습 모델을 평가하기 위해,
- train_test_split 함수를 사용하여 데이터셋을 훈련 세트와 테스트 세트로 나누고,
- 모델을 만들기 위해 훈련 세트에 fit 메서드를 적용하고,
- 모델을 평가하기 위해 테스트 세트에 score 메서드를 사용했습니다!
이 파트에서는 이러한 평가 방법을 조금 더 확장해볼 예정입니다.
1. 교차검증
데이터를 여러 번 반복해서 나누고 여러 모델을 학습하는 방법
가장 널리 쓰이는 교차 검증은 k-겹 교차 검증입니다.
보통 5, 10을 k로 사용합니다. 만일 5-겹 교차 검증이라면, 데이터를 폴드(Fold) 라고 하는 부분 집합 5개로 나누게 됩니다. 그 후 모델을 선정하여 첫 번째 폴드를 테스트 세트로 사용하고 나머지 폴드를 훈련 세트로 사용하여 학습합니다. 그 후 두 번째 폴드는 두 번째 모델의 테스트 세트로 사용되게 됩니다. 이런 식으로 모델의 학습과 테스트가 반복됩니다.

1. scikit-learn의 교차 검증
from sklearn.model_selection import cross_val_scorescikit-learn에서의 교차검증은 위와 같이 model_selection에 cross_cal_score 함수로 구현되어 있습니다.
cross_cal_score의 매개변수는 평가하려는 모델, 훈련 데이터, 타깃 레이블 입니다.
iris = load_iris()
logreg = LogisticRegression(max_iter = 1000)
scores = cross_val_score(logreg, iris.data, iris.target)scikit-learn 0.22 버전부터 3-겹 교차 검증에서 5-겹 교차 검증으로 바뀌었습니다. 폴드의 개수는 cv 매개변수를 사용해서 바꿀 수 있습니다. (최소 5-겹 교차 검증을 사용하는 것이 좋습니다!)
교차 검증에는 cross_validate 함수를 사용할 수도 있습니다. 이 함수는 cross_val_score 함수와 인터페이스가 비슷하지만, 분할마다 훈련과 테스트에 걸린 시간을 담은 딕셔너리를 반환합니다.
2. 교차 검증의 장점
-
교차 검증은 훈련 세트와 테스트 세트가 여러 개가 나오게 됩니다. 이는 세트들의 임의성을 높혀줄 수 있고, 결국 테스트 세트의 정확도에 영향을 미치는 정도가 적어질 수 있을 것이라고 볼 수 있습니다.
-
또, 데이터를 여러 개로 나눔으로써 모델이 훈련 데이터에 얼마나 민감한지 알 수 있습니다. 이는 최악의 경우와 최선의 경우를 짐작할 수 있게 한다는 장점이 있습니다.
-
마지막으로 분할을 한 번 했을 때보다 데이터를 더 효과적으로 사용할 수 있다는 점입니다. train_test_split을 사용하면 데이터 중 75%를 훈련 세트에 사용하고 25%를 평가에 사용합니다. 하지만 k-겹 교차 검증을 사용하면 (k-1)/k를 모델 학습에 사용하므로 더 정확한 모델을 만들어낼 수 있습니다.
-
하지만 교차 검증 역시 한 가지 단점이 있습니다. 바로 연산 비용이 늘어난다는 점입니다. 모델을 k개나 만들어야 하므로 데이터를 한 번 나눴을 때보다 대략 k배 더 느립니다.
3. 계층별 k-겹 교차 검증과 그 외 전략들
k-겹 교차 검증은 데이터셋을 나열 순서대로 k개의 폴드로 나누게 됩니다. iris와 같이 첫 번째 1/3은 클래스 0, 두 번째 1/3은 클래스 1 과 은 데이터를 3-겹 교차 검증을 한다고 생각해보겠습니다. 그럼 첫 번째 폴드의 테스트 세트는 클래스 0, 훈련 세트는 클래스 1,2가 됩니다. 즉, 이 정확도는 '0'이 되겠죠?
이러한 문제를 해결하기 위한 방법이 바로 계층별 k-겹 교차 검증입니다. 아래의 사진과 같이 폴드 안의 클래스 비율이 전체 데이터 셋의 클래스 비율과 동일하도록 데이터를 나눕니다.
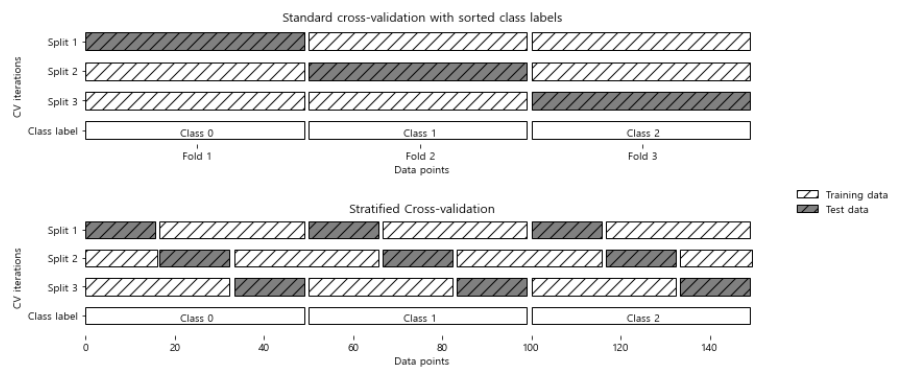
분류에서는 이러한 계층별 K-겹 교차 검증을 많이 사용하기는 합니다만, 회귀에서는 기본 K-겹 교차 검증을 사용합니다. 물론 회귀에서도 계층별 k-겹 교차 검증을 사용할 수는 있지만, 일반적인 방법은 아닙니다.
1. 교차 검증 상세 옵션
scikit-learn에서는 cv 매개변수에 교차 검증 분할기를 전달하여 데이터를 분할할 때 더 세밀하게 제어할 수 있습니다. 대부분의 경우, 기본값이 잘 작동하지만, 가끔! 전략이 필요할 수 있습니다.
예를 들면, 다른 사람의 결과를 재현하기 위해 분류 데이터셋에 기본 k-겹 교차 검증을 사용해야 할 때입니다. 이렇게 하려면 model_selection 모듈에서 KFold 분할기를 import하고 원하는 폴드 수를 넣어 객체를 생성해야 합니다.
from sklearn.model_selection import KFold
kfold = KFold(n_splits = 3)
print("교차 검증 점수: \n", cross_val_score(logreg, iris.data, iris.target, cv = kfold)아까 분꽃 데이터에서 기본 k-겹 교차 검증을 사용하면 말도 안되는 정확도가 나온다고 했습니다. 물론 계층별 폴드를 만들 수도 있지만, 이 문제를 해결하는 다른 방법은 데이터를 섞어 샘플의 순서를 뒤죽박죽으로 만드는 것입니다. 바로 shuffle 매개변수를 True로 바꾸어주면 됩니다. 이때 random_state를 고정해서 똑같은 작업을 재현할 수 있습니다.
from sklearn.model_selection import KFold
kfold = KFold(n_splits = 3, shuffle = True, random_state =0)
print("교차 검증 점수: \n", cross_val_score(logreg, iris.data, iris.target, cv = kfold)2. LOOCV
LOOCV, Leave-one-out cross-validation 역시 또 다른 교차 검증 방법입니다. LOOCV는 각 반복에서 하나의 데이터 포인트를 선택해 테스트 세트로 사용합니다. 폴드 하나에 샘플 하나만 들어 있는 k-겹 교차 검증으로 생각하면 쉬울 것 같습니다. 이는 작은 데이터셋에서 유용한 결과를 만들어 냅니다.
3. 임의 분할 교차 검증
임의 분할 교차 검증은 매우 유연한 또 하나의 교차 검증 전략으로 알려져 있습니다. 이 교차 검증에서는 train_size만큼의 포인트로 훈련 세트를 만들고, test_size만큼의 테스트 세트를 만듭니다. 이때 두 세트의 데이터 포인트는 중복되지 않습니다. 이러한 분할은 n_splits 횟수만큼 반복됩니다.
아래의 그림은 샘플이 10개인 데이터 셋을 5개의 훈련 세트, 2개의 테스트 세트로 선택한 것입니다.

from sklearn.model_selection import ShuffleSplit
shuffle_split = ShuffleSplit(test_size = 5, train 5, n_splits = 10)위의 그림처럼 선택되지 않는 데이터들도 있고, 코드와 같이 50%의 비율로 선택할 수도 있습니다.
3. 그룹별 교차 검증
데이터 안에 매우 연관된 그룹이 있을 때도 교차 검증을 널리 사용합니다. 예를 들어 표정을 인식하는 시스템을 만들기 위해 100명의 얼굴 사진을 모았다고 합시다. 한 사람이 각기 다른 표정으로 여러 장을 찍었고, 이 데이터셋에 없는 사람의 표정을 정확히 구분할 수 있는 분류기를 만드는 것이 목표입니다.
물론 계층별 k-겹 교차 검증을 사용할 수도 있지만, 이렇게 되면 테스트 세트에 같은 얼굴이 들어갈 수 있습니다. 이렇게 되면 모델의 정확도는 높일 수 있지만, 우리의 궁극적인 목표는 새로운 얼굴에 대한 식별이므로 일반화 성능을 높이는데 집중 해야합니다.
이를 위해 사진의 사람이 누구인지를 기록한 배열 groups 매개변수로 전달받을 수 있는 GroupKFold를 사용할 수 있습니다. (groups 배열과 클래스 혼동하지 않기!)
from sklearn.model_selection import GroupKFold
X, y = make_blobs(n_samples = 12, random_state = 0)
groups = [0, 0, 0, 1, 1, 1, 1, 2, 2, 3, 3, 3]
score = cross_val_score(logreg, X, y, groups = groups, cv = GroupKFold(n_splits = 3))이를 그림으로 나타내면 아래와 같습니다.

4. 반복 교차 검증
만일 데이터셋이 크지 않다면 안정된 검증 점수를 얻기 위해 교차 검증을 반복해서 수행할 수 있습니다. 이를 위해 scikit-learn 0.19 버전부터 RepeatedKFold(회귀)와 RepeatedStratifiedKFold(분류) 분할기가 추가되었습니다. 이 클래스의 객체를 cross_val_score에 cv 매개변수로 전달하여 교차 검증을 반복할 수 있습니다.
- 분할 폴드 수: n_splits 매개변수 (기본값 = 5)
- 반복 횟수: n_repeats 매개변수 (기본값 = 10)
(반복할 때마다 데이터를 다시 섞습니다.)
여기까지가 5.1 내용이다!~!~ 이번 주 kaggle 필사에서 cross_validate가 나왔는데 이거 구글링 하면서 애먹었는데 그냥 책공부 먼저할걸................ 중간에 KFold 쓰는 이유도 알게 되고 여러모로 도움이 많이 된 챕터였다!
