드디어 Chapter 4!!!
사실 앞의 지도 학습, 비지도 학습은 들어봤는데, 이 데이터 표현과 특성 공학은 처음 들어봐서 무엇을 배울지 기대된다~!
그럼 시작!
지금까지 다룬 데이터: 연속형 특성
일반적인 데이터: 범주형 특성 = 이산형 특성 (보통 숫자값 X)
BUT,데이터의 특성보다 어떻게 표현할지가 머신러닝 모델의 성능에 주는 영향이 큼
특성공학: 특정 애플리케이션에 가장 적합한 데이터 표현을 찾는 것 (매개 변수 선택보다 더 중요함!)
1. 범주형 변수 (4.1)
- 원-핫-인코딩
: 범주형 변수를 표현하는 데 가장 널리 쓰이는 방법
= one-out-of-N encoding 혹은 가변수 (범주형 변수를 0 또는 1 값을 가진 하나 이상의 새로운 특성으로 바꾼 것)
ex. ABCD의 속성이 있음 -> 내가 A의 속성이라면 A = 1, 나머지는 0
- 범주형 데이터 문자열 확인하기: value_counts()를 통해 유일한 값이 얼마나 나오는지 확인 (male, female -> gender)
= pandas에서는 get_dummies(객체 타입이나 범주형을 가진 열을 자동으로 변환) 함수를 사용해 데이터를 매우 쉽게 인코딩할 수 있음
- 숫자로 표현된 범주형 특성
- get_dummies를 사용하면 문자열 특성만 인코딩되며 숫자 특성은 바뀌지 않음!
- 만약 숫자로 표현된 특성도 가변수로 만들고 싶다면?
-> columns 매개변수에 인코딩하고 싶은 열을 명시해야 함!
demo_df['숫자 특성'] = demo_df['숫자 특성'].astype(str)
pd.get_dummies(demo_df, columns = ['숫자 특성', '범주형 특성']))2. OneHotEncoder와 ColumnTransformer: scikit-learn으로 범주형 변수 다루기 (4.2)
- OneHotEncoder
from sklearn.preprocessing import OneHotEncoder
# 원-핫-인코딩- sparse = False 하면 NumPy 배열 반환
- 변환된 특성에 해당하는 원본 범주형 변수 이름을 얻으려면 get_feature_names 메서드 사용
- ColumnTransformer
: OneHotEncoder는 모든 특성을 범주형이라고 가정하기 때문에 바로 적용할 수 없음 -> ColumnTransformer가 필요한 이유!
- 입력 데이터에 있는 열마다 다른 변환을 적용할 수 있음 (연속/범주형에 따라!)
from sklearn.compose import ColumnTransformer
from sklearn.preprocessing import StadardScaler
ct = ColumnTransformer(
[("scaling", StandardScaler(), ['age', 'hours-per-week']),
("onehot", OneHotEncoder(sparse = False),
['workclass', 'education', 'gender', 'occupation'])])- age, hours-per-week는 연속형 변수이므로 StandardScaler에 따라!
- workclass, education, gender, occupation은 범주형 변수이므로 OneHotEncoder에 따라!
3. make_column_transformer로 간편하게 ColumnTransformer 만들기 (4.3)
- ColumnTransformer는 일일이 열을 다 지정해줘야 하므로... 너무 귀찮다.... -> make_column_transformer
from sklearn.compose import make_column_transformer
ct = make_column_transformer(
(StandardScaler(), ['age', 'hours-per-week]),
(OneHotEncoder(sparse = False), ['workclass', 'education', 'gender', 'occupation']))4. 구간 분할, 이산화 그리고 선형 모델, 트리 모델 (4.4)
- 데이터 표현 방법은 어떤 모델을 사용하느냐에 따라 달라짐!
-> 연속형 데이터에 아주 강력한 선형 모델을 만드는 방법 = 구간 분할 (한 특성을 여러 특성으로 나눔)
-> KBinsDiscretizer 클래스에 이런 방법들이 구현
from sklearn.preprocessing import KBinsDiscretizer
kb = KBinsDiscretizer(n_bins = 10, strategy = 'uniform')
kb.fit(X)
print("bin edges: \n", kb.bin_edges_)
# kb.bin_edges_는 특성별로 경곗값이 저장되어 있음 -> 길이가 1인 배열 출력- transform 메서드를 사용하면 각 데이터 포인트를 해당되는 구간으로 인코딩 (KBinsDiscretizer은 구간에 원-핫-인코딩 적용)

- 첫 번째 데이터 -0.753은 네 번째 구간, 두 번째 데이터 2.704는 열 번째 구간에 포함... 이런 식으로 계속 됨!
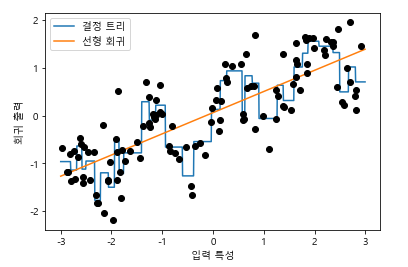
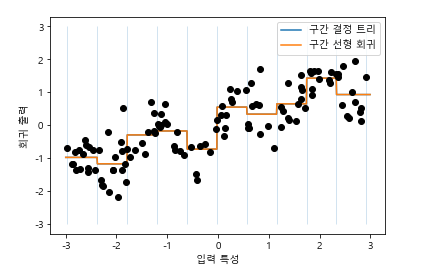
- 선형 회귀 모델과 결정 트리가 같은 예측을 만들어내서 파선과 실선이 완전히 겹쳐짐! 선형 모델은 훨씬 유연해졌지만, 결정 트리는 덜 유연해졌음
- 결정 트리는 데이터셋에서 예측을 위한 가장 좋은 구간을 학습한다고 볼 수 있음 -> 따지고 보면 선형 모델이 이득....
5. 상호작용과 다항식 (4.5)
- 특성을 풍부하게 나타내는 또 하나의 방법 -> 상호작용, 다항식 추가
- 상호작용
- 4번에서 학습한 데이터의 선형 모델은 절편도 학습할 수 있지만 기울기도 학습할 수 있음
-> 기울기를 추가하는 방법: 구간으로 분할된 데이터에 원래 특성을 다시 추가하는 것 (11차원의 데이터)

- 학습된 기울이는 양수
- 모든 구간에 걸쳐 동일
- 각 구간에서 다른 기울기는 가져야지! -> 데이터 포인트가 있는 구간과 x축 사이의 상호작용 특성 추가 (구간 특성과 원본 특성의 곱)
X_product = np.hstack([X_binned, X * X_binned])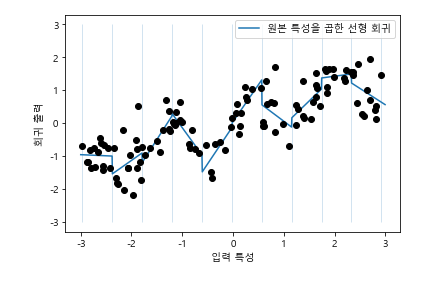
- 다항식
: 상호작용말고 다항식의 방법도 있음!
from sklearn.preprocessing import PolynomialFeatures
ploy = PloynomialFeatures(degree = 10, include_bias = False)
ploy.fit(X)
X_poly = ploy.transform(X)-> 다항식 특성을 선형 모델과 함께 사용하면 전형적인 다항 회귀
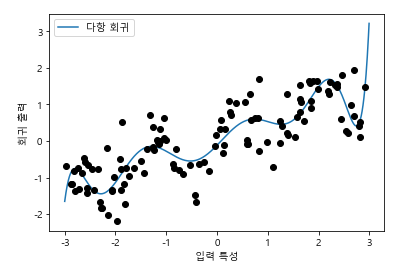
여기서 아무런 변환도 거치지 않은 원본 데이터에 커널 SVM 모델 학습을 시켜 추가하면,
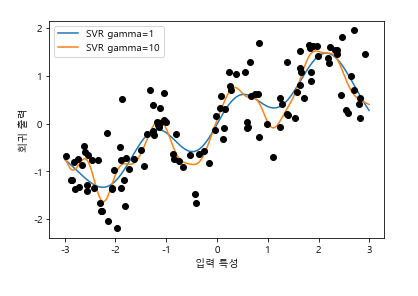
6. 일변량 비선형 변환 (4.6)
- 수학 함수를 적용하는 방법도 특성 변환에 유용!
- 대부분의 모델은 각 특성이 정규분포와 비슷할 때 최고의 성능을 냄
- exp, log를 사용하여 정규분포와 비슷하게 만들어줄 수 있음! (이상치가 거의 보이지 않게 됨!)
- 구간 분할, 다항식, 상호작용은 선형 모델이나 나이브 베이즈 모델 같은 덜 복잡한 모델일 때 성능에 큰 영향을 줄 수 있음! (SVM, 최근접 이웃, 신경망 같은 모델도 이득이 있지만 그렇게 크지는 않음)
7. 특성 자동 선택 (4.7)
- 특성이 추가되면 모델은 더 복잡해지고 과대적합이 될 가능성도 높아짐
- 새로운 특성을 추가할 때나 고차원 데이터셋을 사용할 때, 가장 유용한 특성만 선택하고 나머지는 무시해서 특성의 수를 줄이는 것이 좋음! (일반화 성능 UP! UP!)
★ 모두 지도 학습 방법
- 일변량 통계 (분산 분석 ANOVA)
: 개개의 특성과 타깃 사이에 중요한 통계적 관계가 있는지 계산
-> 핵심: 각 특성이 독립적으로 평가 일변량
- 분류: f_classif(기본값) 선택
- 회귀: f_regression 선택
-> 계산한 p-value에 기초하여 특성을 제외하는 방식!
- 매우 높은 p-value를 가진 특성을 제외할 수 있도록 임계값을 조정하는 매개변수 사용 ~!
- 임계값 계산: 가장 간단한 SelectKBest는 고정된 k개의 특성을 선택 / SelectPercentile은 지정된 비율만큼 특성 선택
- 모델 기반 특성 선택
: 지도 학습 머신러닝 모델을 사용하여 특성의 중요도를 평가하여 가장 중요한 특성들만 선택
- 특성 선택 모델과 지도 학습 모델이 같을 필요는 없음! -> just 전처리!
- 사용된 모델이 상호작용을 잡아낼 수 있다면 상호작용 부분을 반영할 수 있음! (일변량 통계와 다른 점!)
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import RandomForestClassifier
select = SelectFromModel(
RandomForestClassifier(n_estimators = 100, random_state = 42),
threshold = "median")- 중요도가 지정한 임계치보다 큰 모든 특성 선택
- 반복적 특성 선택
: 특성의 수가 각기 다른 일련의 모델이 만들어짐
1) 특성을 하나도 선택하지 않은 상태로 시작해서 어떤 종료 조건이 될 때까지 특성을 하나씩 제거해가는 방법 = 재귀적 특성 제거 RFE
from sklearn.feature_selection import RFE
select = RFE(RandomForestClassifier(n_estimators = 100, random_state = 42),
n_features_to_select = 40)- 다른 코드보다 훨씬 오래 걸림
- 특성 자동 선택도 있음!
8. 전문가 지식 활용 (4.8)
- 시계열 데이터를 이용한 예측 작업은 과거 데이터에서 학습하여 미래를 예측하는 방식 사용

정말 알아?