1. 신경망 Deep Learning (2.3.9)
: 알고리즘 中 하나 -> 딥러닝
- 다층 퍼셉트론 Multilayer perceptrons, MLP: 딥러닝 알고리즘의 출발점
1. 신경망 모델
:여러 단계를 거쳐 결정을 만들어냄
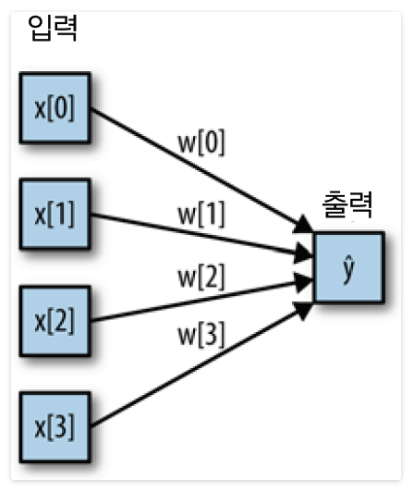
- 왼쪽 노드: 입력 특성을 나타내며 연결선은 학습된 계수를 표현
- 오른쪽 노드: 입력의 가중치 합 = 출력
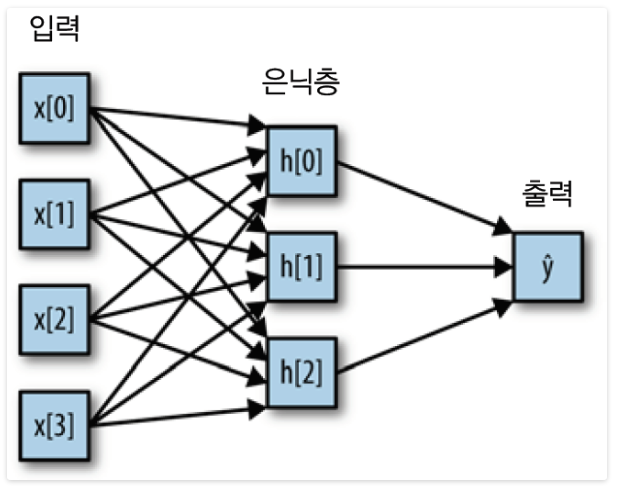
-> MLP에서는 가중치 합을 만드는 과정(y hat)이 여러번 반복
- 은닉 유닛: 중간 단계 -> 다시 가중치의 합을 계산
이것만 보면 선형 모델이랑 비슷하기 때문에, 더 강력하게 만들기 위해서
렐루 or 하이퍼볼릭 탄젠트 (비선형 함수)를 적용
★ 우리가 정해야할 중요 매개변수: 은닉층의 유닛 개수
-> 많은 은닉층으로 구성된 대규모의 신경망 = 딥러닝!
2. 신경망 튜닝
from sklearn.neural_network import MLPClassifier특징
- MLP 기본값 = 은닉 유닛 100개 -> 작은 데이터셋에는 과분한 크기
- 기본 비선형 함수 = 렐루
- 은닉층이 하나이므로 결정 결계를 만드는 함수는 직선 10개가 합쳐져서 구성
(?? REAL 모르겠다...)
-> hidden_layer_sizes = [,] 괄호 안의 콤마로 은닉층 구분(??) - 매끄러운 결정경계를 원한다면?
- 은닉 유닛 추가
- 은닉층 추가
- tanh 함수 사용
- 은닉층이 하나이므로 결정 결계를 만드는 함수는 직선 10개가 합쳐져서 구성
- L2 패널티를 사용해서 가중치를 0에 가깝게 감소시킴 like 선형 분류기, 리지 회귀 -> alpha 매개변수
- 기본값이 매우 낮게 되어 있음 (거의 규제 X)
- 학습 시작 전, 가중치를 무작위로 설정 -> 같은 매개변수를 사용하더라도 초깃값이 다르면 모델이 많이 달라짐!
- MLP 정확도를 높이기 위해 모든 입력의 특성을 평균 0, 분산 1이 되도록 변형
#훈련 세트 평균 계산
mean_on_train = X_train.mean(axis=0)
#훈련 세트 표준 편차 계산
std_on_train = X_train.std(axis=0)
#표준정규분포로 만들기
X_train_scaled = (X_train - mean_on_train) / std_on_train
#테스트 세트도 표준정규분포로 만들기
X_test_scaled = (X_test - mean_on_train) / std_on_train
mlp = MLPClassifier(random = 0)
# 반복횟수가 100이 기본값이기 때문에 max_iter 매개변수를 이용해 늘려줘야 함
# 안 그럼 오류!
mlp.fit(X_train_scaled, y_train)
print("훈련 세트 정확도: {:.3f}".format(mlp.score(X_train_scaled, y_train)))
print("테스트 세트 정확도: {:.3f}".format(mlp.score(X_test_scaled, y_test)))- 일반화 성능을 더 올리기 위해 모델의 복잡도 by alpha
- 분류 MLPClassifier 회귀 MLPRegressor
- 딥러닝을 위한 라이브러리 多........
장단점
- 장점
- 머신러닝 분야의 많은 애플리케이션에서 최고의 모델로 다시 떠오르고 있음
- 대량의 데이터에 내재된 정보를 잡아냄
- 매우 복잡한 모델을 만들 수 있음
- 단점
- 종종 학습이 오래 걸림
- 데이터의 전처리에 주의 -> 다른 종류의 특성을 가진 데이터라면 결정 트리
복잡도 추정
- 매개변수: ★ 은닉층의 개수 + 은닉층의 유닛 수 ★ + alpha
아래는 2.4절의 분류 예측의 불확실성 추정!
- scikit-learn에서 많이 사용하는 인터페이스: 분류기에 예측의 불확실성을 추정할 수 있는 기능
- decision_function- predict_proba
(대부분의 분류 클래스는 이 중 하나 or 두 함수 모두 제공)
- predict_proba
2. 결정 함수 (2.4.1)
: 이진 분류에서 decision_function 반환값의 크기는 (n_samples,)
-> 각 샘플이 하나의 실수 값을 반환
정말 역대급으로 이해 못하겠음 ^^... 이 값이 의미하는 바가 무엇인가?
결정 함수만 따로 공부해야겠다
3. 예측 확률 (2.4.2)
: predict_proba의 출력은 각 클래스에 대한 확률 -> decision_function의 출력보다 이해하기 쉬움 (오예!)
-
반환값 = (n_samples, 2)
- 첫 번째 원소: 첫 번째 클래스의 예측 확률
- 두 번째 원소: 두 번째 클래스의 예측 확률
-> 확률이기 때문에 predic_proba의 출력은 항상 0과 1 사이의 값 (확률의 합 = 1)
끝
지도 학습이 끝났다 ~!~!~!~! 신경망에서는 들어본 단어 (다중 퍼셉트론 등등...)이 많아서 공부하는데 재미있었는데, 그 뒤에 새로운 관문이 기다리고 있었다 ^^... 분류 예측의 불확실성 추정...... 멀지 않은 미래에 정복하러 오겠다 !!!

정말 알아?