1. 결정트리(2.3.5)
: 결정에 다다르기 위해 예/아니오 질문을 이어 나가면서 학습 (스무고개)
-> 계층적으로 영역을 분할해가는 알고리즘
- 노드: 질문이나 정답을 담은 네모 상자
- 리프: 마지막 노드
- 루트 노드: 맨 위의 노드 (전체 데이터 포함)
- 순수 노드: 타깃 하나로만 이루어진 리프 노드
from sklearn.tree import DecisionTreeClassifier특징
- 결정 트리 학습 = 정답에 가장 빨리 도달하는 예/아니오 질문 목록(테스트)을 학습
- X[1] 행 방향 X[0] 열 방향
- 결정 트리의 리프가 한 개의 타깃 값을 가질 때까지 반복됨
- 새 데이터 포인트에 대한 예측: 주어진 데이터 포인트가 특성을 분할한 영역들 중 어디에 놓이는가? (루트 노드에서 시작)
- 회귀 문제에도 사용 가능(찾은 리프 노드의 훈련 데이터의 평균값이 출력값)
- 복잡도 제어: 트리 만들기를 모든 리프 노드가 순수 노드가 될 때까지 진행하면 모델이 매우 복잡 + overfitting
- 트리 생성을 일찍 중단하는 전략 (사전 가지치기) -> 트리의 최대 깊이나 리프의 최대 개수를 제한, 노드가 분할하기 위한 포인트의 최소 개수를 지정 (scikit-learn은 사전 가지치기만 지원)- 트리를 만든 후 데이터 포인트가 적은 노드 삭제 or 병합 (사후 가지치기 = 가지치기)
분석
- 트리 모듈의 export_graphviz 함수를 이용해 시각화 가능 (.dot - 그래프 저장용 텍스트 파일 포맷)
from sklearn.tree import export_graphviz
exprot_graphviz(tree, out_file = "tree.dot", class_names=["악성", "양성"],
feature_names = cancer.feature_names, impurity = False, filled = True)- .dot 파일 읽을 때
import graphviz
with open ("tree.dot") as f:
dot_graph = f.read()
display(graphviz.Source(dot_graph))특성 중요도
: 트리를 만드는 결정에 각 특성이 얼마나 중요한지를 평가하하는 것
- 0과 1 사이의 숫자 (1은 완벽하게 타깃 클래스를 예측했다는 뜻)
- 전체 중요도의 합은 1
- 항상 양수
- 어떤 클래스를 지지하는지 모름
★ DecisionTreeRegressor로 구현된 회귀 결정 트리에서도 비슷하게 적용
-> 훈련 데이터의 범위 밖의 포인트에 대해 예측 불가 = 외삽 X
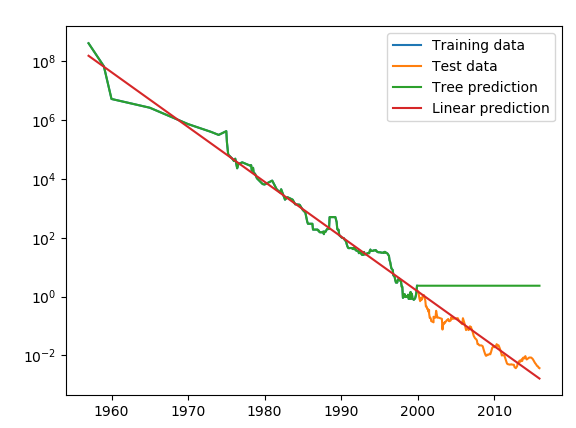
- 트리 모델은 훈련 데이터를 완벽하게 근사 (복잡도에 제한 X)
- 훈련 데이터 밖의 새로운 데이터를 예측할 능력 X
장단점
- 장점
- 만들어진 모델을 쉽게 시각화 할 수 있어 비전문가도 이해하기 쉬움
- 데이터의 스케일에 구애받지 않음
- 단점
- 사전 가지치기를 사용함에도 불구하고 과대적합
2. 결정트리의 앙상블 (2.3.6)
: 머신러닝 모델을 연결하며 더 강력한 모델을 만드는 기법
- 랜덤 포레스트
- 그레이디언트 부스팅
1. 랜덤 포레스트
: 조금씩 다른 여러 결정 트리의 묶음
-> 서로 다른 방향으로 과대적합된 트리를 많이 만들어 그 결과를 평균냄 무작위성
from sklearn.ensemble import RandomForestClassfier구축
- 데이터셋
트리를 만들기 위해 먼저 데이터의 부트스트랩 샘플 생성 (n_samples개의 데이터 포인트 중 무작위로 데이터를 n_sammples 획수만큼 반복 추출 - 한 샘플이 여러 번 추출될 수 있음) - 특성
각 노드에서 후보 특성을 무작위로 선택한 후 이들 중 최선의 테스트를 찾음 (전체 특성 고려 X) - 매개변수: max_feature
- max_features를 n_features로 설정하면 트리의 각 분기에서 모든 특성을 고려 (특성 선택에 무작위성 X)
- max_features의 값을 크게 하면 랜덤 포레스트의 트리들은 매우 비슷
- max_features의 값을 작게 하면 랜덤 포레스트의 깊이가 매우 깊어짐
장단점
- 장점
- 현재 가장 널리 사용되는 머신러닝 알고리즘
- 랜덤 포레스트의 트리가 많을수록 random_state 값의 변화에 따른 변동이 적음
- 같은 결과를 만들어야 한다면 random_state 값 고정
- 단점
- 텍스트 데이터 같은 차원이 높고 희소한 데이터에는 잘 작동하지 않음
- 선형 모델보다 많은 메모리 사용
- 훈련과 예측이 느림
- 매개변수
- n_estimators, max_features, max_depth(사전 가지치기)
- n_estimators: 클수록 좋음 -> 더 많은 트리를 평균하여 과대적합을 줄임
- max_features: 기본값을 쓰자!
2. 그레이디언트 부스팅 회귀
: 머신러닝 모델을 연결하며 더 강력한 모델을 만드는 기법 -> 분류와 회귀 모두에 사용 가능
★ 이전 트리의 오차를 보완하는 방식으로 순차적으로 트리를 만듦 ★
from sklearn.ensemble import GradientBoostingClassifier특징
- 무작위성이 없음 (오차를 보완하는 방식이니까 ~~)
- 강력한 사전 가지치기
- 하나에서 다섯 정도의 깊지 않은 트리를 사용 = 메모리 사용이 적고 예측도 빠름
- 근본 아이디어: 얕은 트리 같은 간단한 모델을 많이 연결
- 매개변수: learning_rate
- 학습률이 크면 트리는 보정을 강하게 함
- n_estimators 값을 키우면 앙상블에 트리가 더 많이 추가되어 모델의 복잡도가 크짐
- 훈련 세트에서의 실수를 바로잡을 기회가 더 많아짐
- 비슷한 종류의 데이터에서 그레이디언트 부스팅과 랜덤 포레스트 둘 다 잘 작동하지만 랜덤포레스트를 먼저 적용
(마지막 성능까지 쥐어짜야할 때 그레이디언트 부스팅 ^^...)
장단점
- 장점
- 지도 학습에서 가장 강력하고 널리 사용하는 모델 중 하나
- 특성의 스케일을 조정하지 않아도 됨
- 이진 특성이나 연속적인 특성에서도 잘 작동 O
- 단점
- 매개변수를 잘 조정해야 함
- 훈련 시간이 김
- 트리 기반 모델의 특성상, 희소한 고차원 데이터에서는 잘 작동 X
- 매개변수
- n_estimators: 트리의 개수를 정함 -> 클수록 모델 복잡 + overfitting
- learning_rate: 이전 트리의 오차를 보정하는 정도
-> learning_rate를 낮추면 비슷한 복잡도의 모델을 만들기 위해 더 많은 트리를 추가해야함 - max_depth(or max_leaf_nodes): 매우 작게 설정 (5보다 깊어지지 않게 설정)
(+추가)
- scikit_learn 0.20 버전에서는 GredientBoostingClassifier와 GredientBoostingRegressor에 조기 종료를 위한 매개변수 n_iter_no_change와 validation_ftaction이 추가
끝
분명 개념은 쉬운데 뭔가 너무 어렵다... ~~... ~~... ~~..... 역시 공부는 끝이 없는 것인가

정말 알아?