힘들고 힘들었던 ELK + Kafka 도입기
1.Reading을 분리하자! - CQRS 도입기

필자뿐만 아니라 주니어 및 개발을 막 공부한 사람들은 JPA 및 MariaDB, Mysql 하나에서 CRUD를 완벽하게 하는 것도 벅찰 것이다!!필자도 완벽하게 JPA와 RDB의 다양한 기술을 완전히 익힌 것이 아니다. 누가 보기엔 오버 스펙으로 공부한다 생각하겠지만,
2.Kafka란 무엇인가? - CQRS 도입기

Kafka에 자세히 들여다 보자! Kafka에 대한 소개는 이전 글과 그리고 이전 TechTalk에서 설명한바가 있기에 생략하겠다. 더 깊은 내용을 자세히 알아보는 시간이다. Kafka에 대한 알기 전에 CDC에 대해 알아보자, 결국 우리는 이것을 위해 Kafka를 쓰
3.Infra 구축 - CQRS 도입기
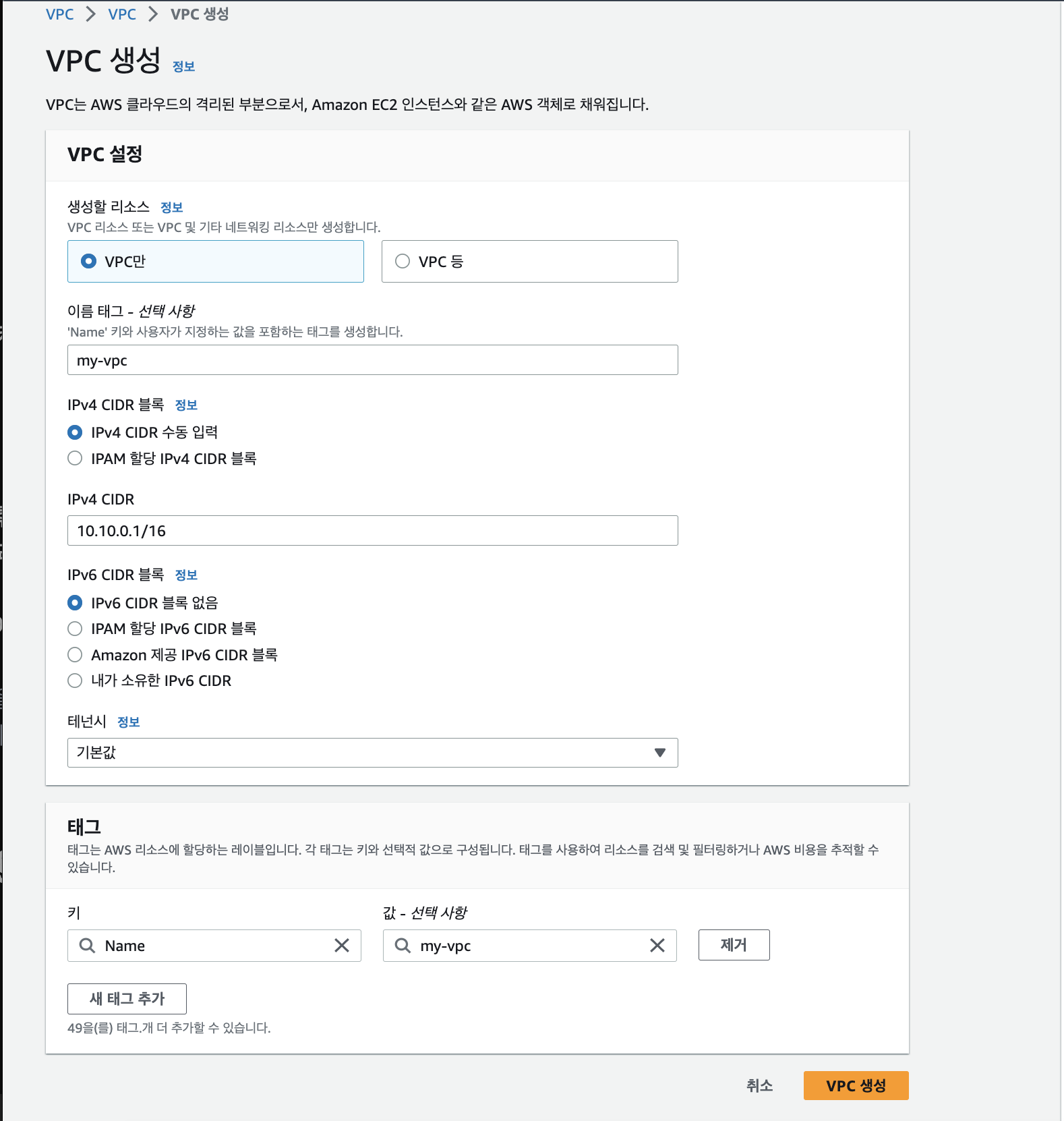
저번글에서 이론적으로 Kafka에 대한 정리를 마치고, 드디어 CQRS를 위한 Infra Setting을 시작으로 Pipeline을 구축하고자 합니다.필자가 활용한 것은 아래와 같습니다.AWS EC2VPCSubnetRouterAWS Elastic SearchMSK(Ka
4.MSK 생성하기 - CQRS 도입기
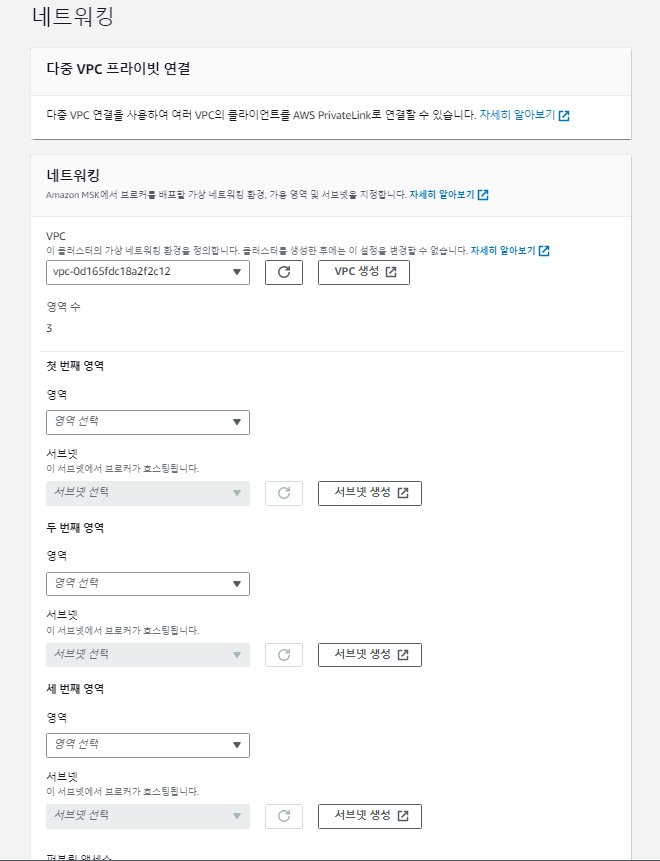
Kafka를 띄워보자!! 필자는 AWS의 환경에서 Kafka를 띄우기로 하여 AWS에서 제공해주는 Kafka Cluster인 MSK를 활용하였습니다. MSK의 설정하는 과정을 아래의 그림과 함께 설명해드리겠습니다. 필자는 사용자 지정 생성 방식으로 MSK를 생성하였습
5.Kafka를 구동시켜보자 - CQRS 도입기
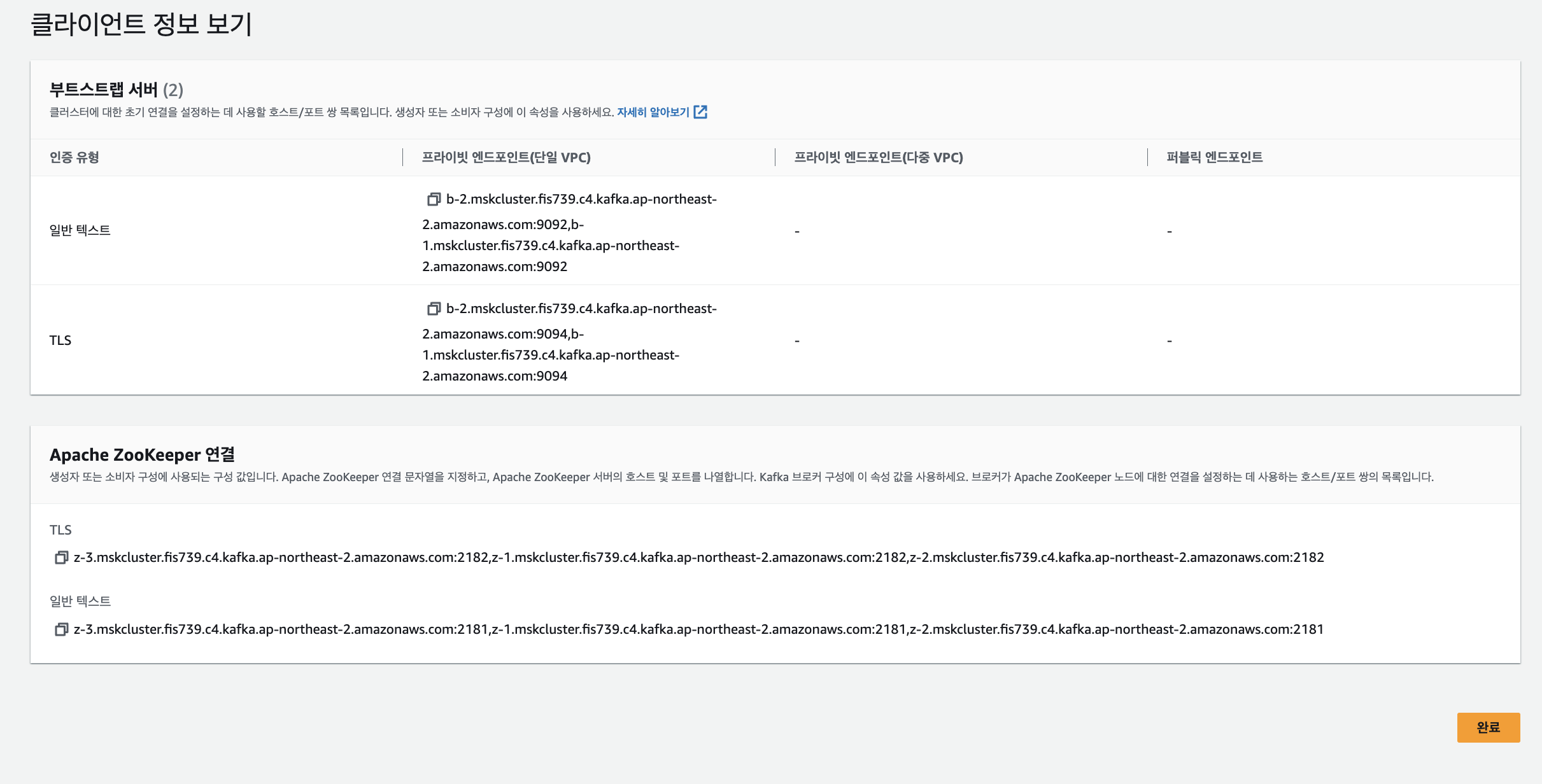
Kafka를 구동시켜보자!! 필자는 저번 글에 MSK를 AWS를 활용하여 구축하는 것을 보여드렸습니다. 이제는 CUD 서버를 구축하여 Producer와 Consumer끼리 메세징을 잘 받는지 확인하려고 하였습니다. 하지만 Docker에서 Kafka를 띄울때는 Sprin
6.CUD 서버를 띄우다 - CQRS 도입기
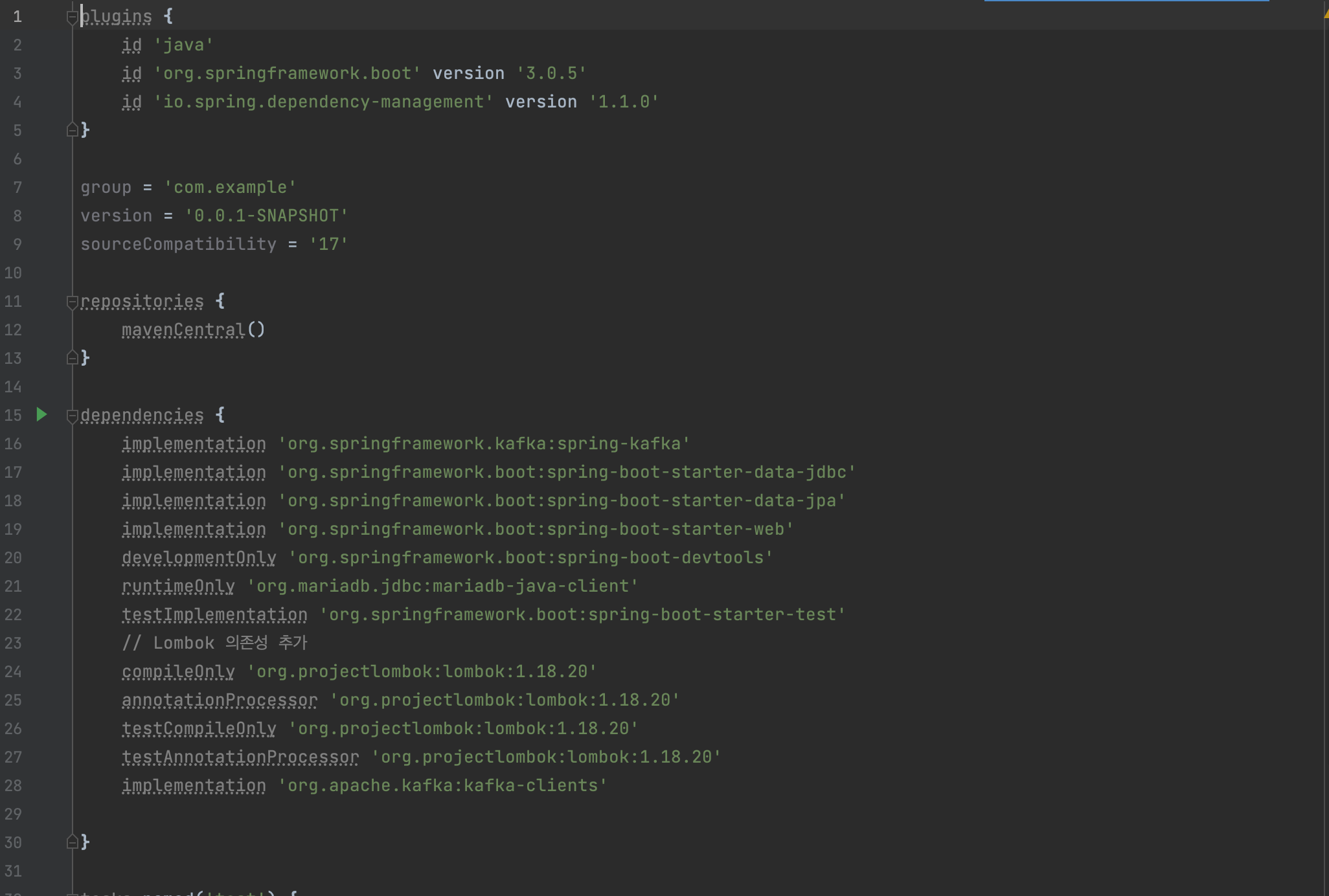
저번 글에서 MSK의 연결 여부 및 동작 여부를 Kafka Client를 통해서 확인해 보았습니다.이번 글에서는 CUD Spring Boot를 구축함과 동시에 데이터 동기화를 위해 CUD에 저장되는 데이터들을 Reading Server로 넘기기 위한 작업을 진행하고자
7.ELK Stack(1) - CQRS 도입기
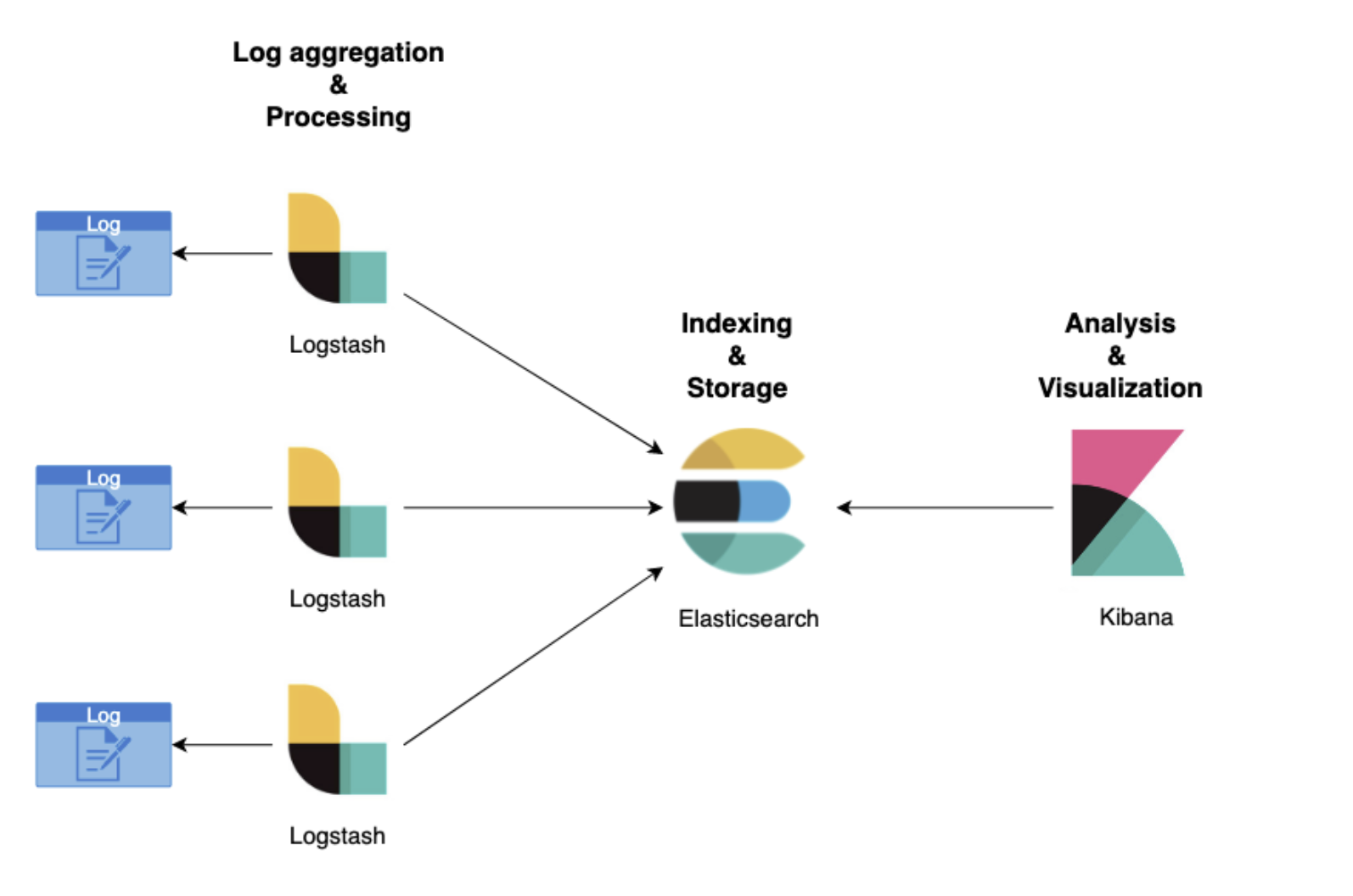
저번 글을 끝으로 CUD 서버와 Kafka의 셋팅을 마쳤습니다. 이제부터는 Reading쪽에 관한 모든 것을 정리하고 시작하고자 합니다.간단한 플로우를 보여드리면 아래와 같습니다.왜 ELK를 택하셨습니까???늘 해당 기술 스택을 쓸 때 내가 왜 쓰는지??그리고 어떤 장
8.ELK Stack(2) - CQRS 도입기
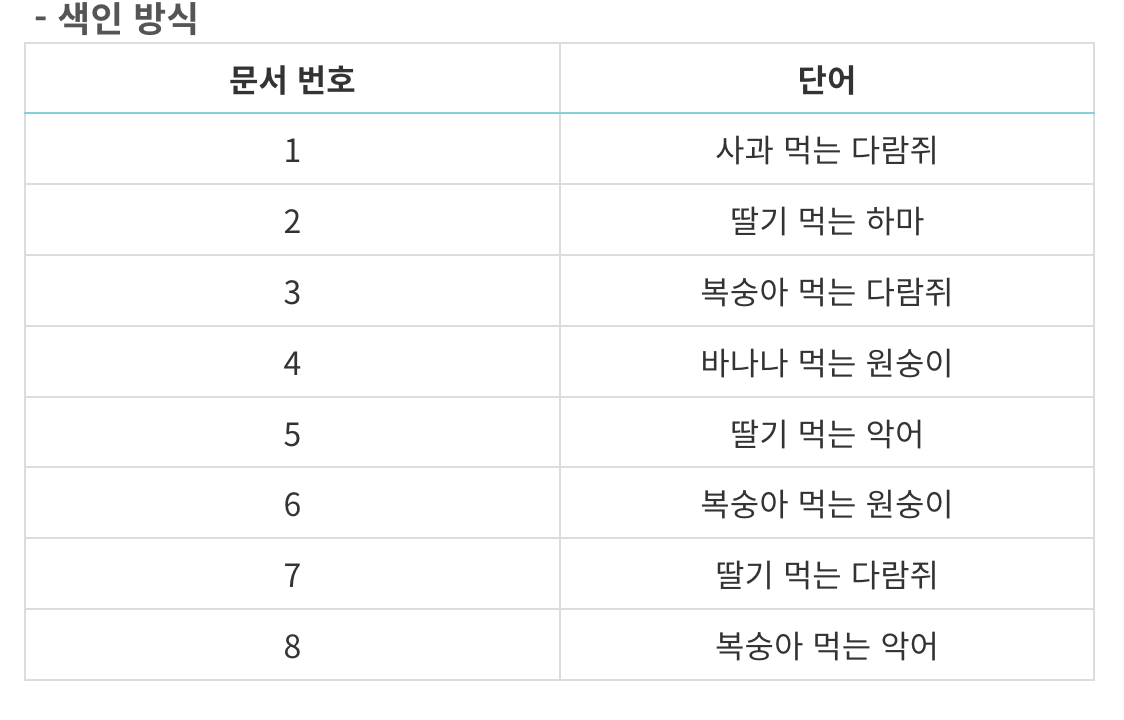
ElasticSearch는 간단하게 말씀 드리면 검색 및 분석엔진으로써 대용량의 데이터를 신속하게 검색하고 분석하는 데 사용되는 오픈 소스 솔루션입니다.근데 여기서 중요한 점!! 그러면 기존 RDB와 NoSql DB들과의 차이점이 무엇이고 장점이 무엇인지???DataM
9.Reading Server 구축 - CQRS 도입기
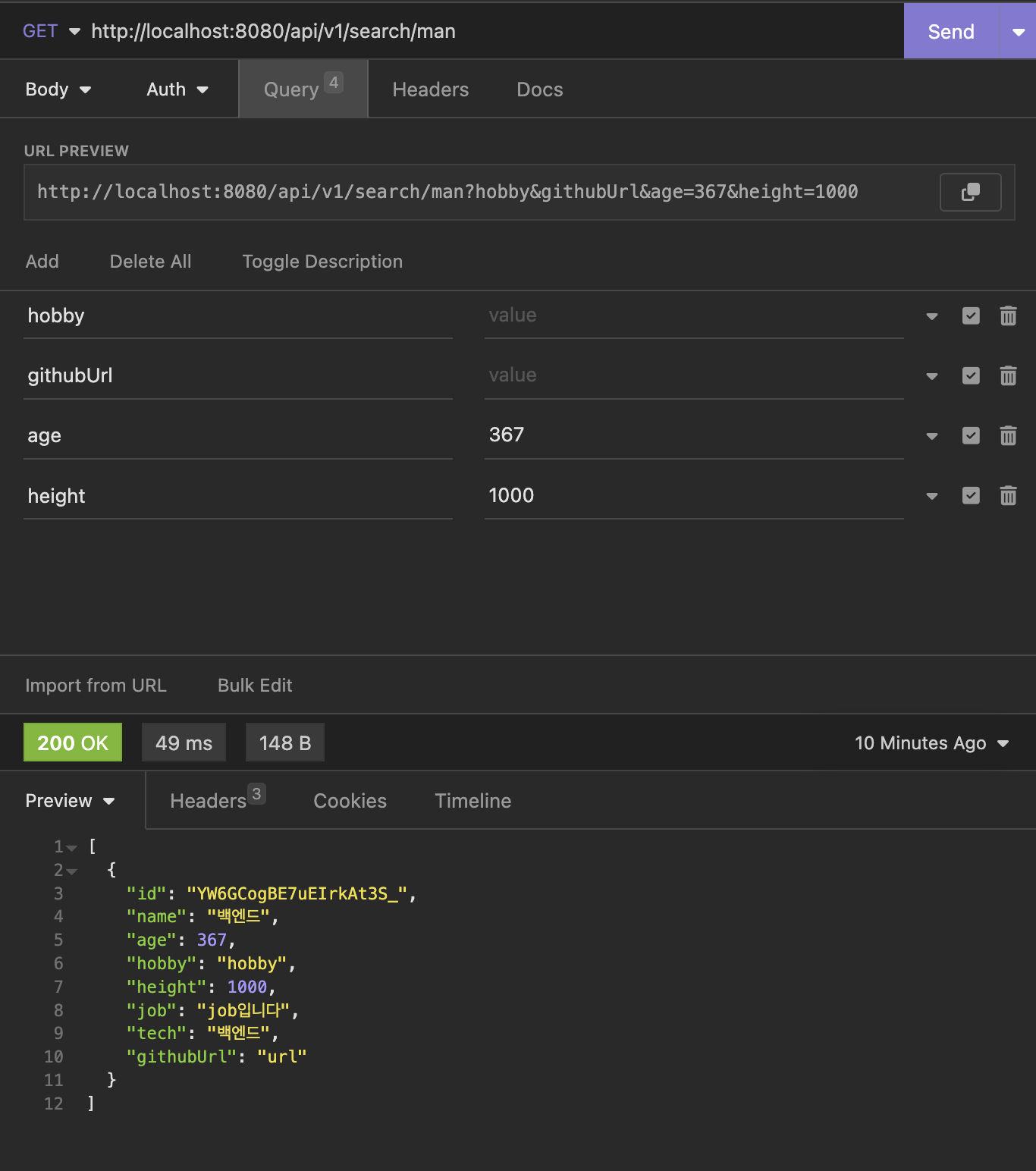
우리는 CUD서버와 ELK 스택 구축까지 마무리하였습니다. 이제 마지막으로 CQRS 구조에서 Reading을 담당하는 Server를 구축하는 것만 남았습니다.필자는 Spring boot를 통해 구축하였습니다!!spring boot에서는 ElasticSearch에 접근하