
Kafka에 자세히 들여다 보자!
Kafka에 대한 소개는 이전 글과 그리고 이전 TechTalk에서 설명한바가 있기에 생략하겠다. 더 깊은 내용을 자세히 알아보는 시간이다. Kafka에 대한 알기 전에 CDC에 대해 알아보자, 결국 우리는 이것을 위해 Kafka를 쓰고 있으니....
- CDC란?
- CDC = > Change Data Capture!
- Database의데이터에 대한 변경 사항을 식별 및 캡처한 다음 이러한 변경 사항을 실시간으로 Down Stream 또는 System에 전달하는 Process 를 나타냅니다.
- Source Database의 Transaction에서 모든 변경 대상을 캡쳐해서 실시간으로 데이터를동기화합니다
CDC 기능에 필요한 것들?
- Data의 변화를 캡처하고 동기화를 위해 필요한 것들이 무엇이 있을까요?
- 순서 보장(Transaction의 순서를 보장 못한다면 데이터의 동기화는 뒤죽박죽 일 것이다.
- 변경 데이터는 실시간으로 동기화 되어야한다.(데이터 일관성 유지)
- 그리고 이 모든 과정에 대한 로깅 수집과 모니터링!
Why Kafka?

이전 글들에서 몇번 언급했었지만, 한번 더 짚고 넘어갑시다!!
1. 데이터의 정합성이 제일 중요하다 생각했다.그렇기에 반영구적으로 저장의 기능을 가지고 있는 Kafka의 장점이 돋보였다.
2. Consumer에게 제대로 전달이 되었는지 확인 할 수 있는 Ack의 기능
3. Broker 및 Partition을 통한 순서 보장과 병렬 처리가 가능함에 따른 대용량 파일 처리에 유리한 점
4. Java로 이뤄져있기에 직접 Log를 읽고 분석할 수 있다는 점
5. 모니터링 및 로깅 기능을 제공하기에 에러 분석이 가능하다는 점
Producer?
이제부터 Kafka를 하나씩 뜯어보면서 이해해보자!! 그것의 첫번째가 바로 Producer이다.
그 전에 간단한 Kafka의 내부 구조를 그림으로 보면서 이해해보자!!
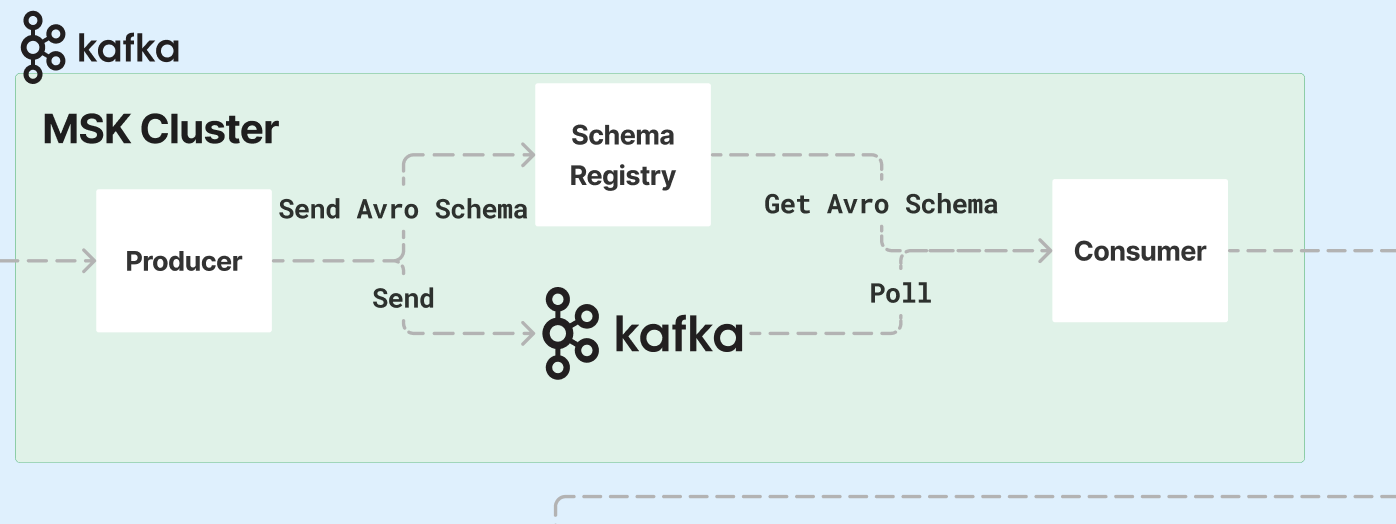
위의 그림처럼 Kafka는 Producer라는게 존재합니다. 바로 이벤트(Message)를 생성하는 주체입니다.
Producer는record의 형식으로 데이터를 만들어서 보낼 수 있는데,record의 형태는 json,avro의 타입을 가질 수 있습니다.
Broker 그리고 Zookeeper?
Producer가 데이터를 보냈습니다. 그러면 이 데이터를 저장하고,Serializer을 해서 Consumer에게 전달해야할 주체가 필요합니다. 바로 이것이 이뤄지는 곳이 Broker입니다.

위의 그림처럼 Kafka Broker는 메세지 전달 및 저장에 중추 역할을 하며 Kafka 그 자체입니다.
Broker를 단일 Node로 쓸 수도 있지만 대부분 Cluster를 구축하여 활용합니다. 하지만 브로커들로만 클러스터를 구성할 수 없습니다. 브로커의 여러가지 메타데이터를 저장하고 관리해주는 주키퍼(ZooKeeper)가 필요하기 때문입니다.
ZooKeeper는 현재 Kafka와 필연적을 함께 구축되어야 하는 것이므로, 간단하게 설명하고 넘어가겠습니다.
- 주 역할은 분산 시스템의 메타 정보를 관리하고, 필요시에는 분산 시스템의 마스터를 선출합니다. 예를 들면, 카프카 클러스터를 구성하면 주키퍼에는 카프카 클러스터의 식별 정보부터 현재 살아있는 브로커 정보, 나아가 권한 정보 등이 저장됩니다. 또한, 카프카 브로커들 중 일종의 지휘자 역할을 하는 컨트롤러(Controller) 브로커를 뽑는 역할을 담당합니다
Broker에서 설정해야할 중요한 3가지만 언급하고 넘어가겠습니다.
- broker.id
broker.id 는 같은 카프카 클러스터에서 현재 브로커를 식별하기 위한 숫자입니다/ - log.dirs
log.dirs 설정은 브로커가 프로듀서로부터 받는 메시지들을 저장할 위치 경로를 지정하는 설정입니다 - zookeeper.connect
zookeeper.connect 는 카프카 클러스터의 메타 정보를 저장할 주키퍼에 관한 호스트 연결 정보를 가집니다.Topic과 Partition?
Topic은 필자가 생각하기에 Kafka에서 보여지는 데이터 중 가장 큰 그룹이라고 생각할 수 있다.
Topic은Event Stream의 집합을 표시하며 개발자들은 이를 자기가 원하는 그룹으로 묶어서 구분하는데 바로 그것이 Topic이다.
이제굳이 비교를 하자면 RDB에서의 Table과 유사한 성격을 가지고 있다고 할 수 있다.
아래의 그림을 보면 좀 더 이해하기 편할 것이다.

Partition에 대해 설명하고자 합니다.Topic을Table에 비유 했었는데Topic은 RDB의Column또는 그안에 있는Data라고 생각할 수 있습니다. 그렇기에Topic은 꼭 한개 이상의Partition을 가져야합니다.그렇기에 Partition은 Producer가 생성한 record를 저장하는 가장 작은 단위입니다. 그리고 각각의 Partiton은 record를
Append only방식으로 기록합니다.(Append는 배열에 하나씩 쌓아나간다고 생각하시면 편합니다.)

그러면 어떻게 순서를 보장해?? Offset?
필자가 Kafka를 쓰는 이유 중 하나는 "순서를 보장한다" 였습니다. 그렇다면 여기서 의문이 듭니다. 어떻게 순서를 보장하고 있는가???
Kafka는 이것에 대한 해답을 줍니다. 바로 데이터로 불리는 record에 Offset이라는 식별자를 부여함으로 파티션내에서 순서를 유지하게 합니다.
하지만 필자가 Kafka에 대해 공부하는 도중에 Kafka는 순서를 보장하지 않는다라는 블로그글을 보았습니다. 읽어보면 엄연히 맞는 말입니다. 왜냐하면
Partition안에선record사이의 순서를 보장하지만Partition끼리의 순서는 보장하지 않기 때문입니다.
아래의 그림을 보면서 좀 더 쉽게 이해해봅시당!!

Replication???
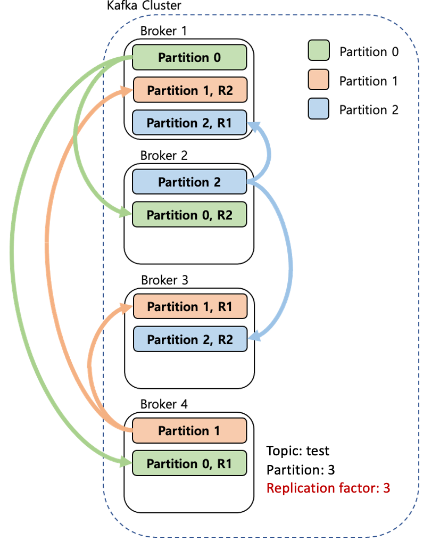
Kafka는 에러 발생 및 분산 처리를 위해 Replica기능을 제공합니다. 이를 통해서 가용성을 높입니다. Replication은 각 Topic의 Partition들을 Kafka Cluster내의 다른 Broker들로 복제하는 것을 말하며 Topic생성 시 Replication의 수를 지정할 수 있습니다.
아래의 그림과 코드를 보면 좀 더 쉽게 이해하실 수 있습니다.

Consumer??
이제 생성하고 등록하는 과정을 다 봤습니다. 그러면 이제 Consumer가 과연 어떻게 데이터를 소비하고 읽어내는지 알아보겠습니다.
- pub/sub 모델과는 달리, Kafka 는 메시지를 Consumer 에 전달 (push) 하지 않는다. 대신, Consumer 가 카프카의 파티션으로부터 메시지를 읽어 (poll) 가야 한다. 컨슈머는 브로커의 파티션과 연결해, 메시지들이 쓰여진 순서대로 메시지를 읽는다.
즉 Consumer는 record의 Offset을 추적하며 읽어내며, 그 읽어낸 record를 저장합니다. 그렇기에 연결이 끊기거나 장애가 생겨도 다시 읽었던 Offset을 찾아내 그 다음부터 읽을 수 있는 것입니다.

근데 Producer는 어떻게 잘 전달했는지 판단할까?? Ack??
데이터 전송도 중요하지만 데이터의 유실은 결국 구축하는 Service에서의 큰 악영향을 미치기에 데이터의 일관성과 유실 방지도 중요합니다.
-
과연 그러면 Kafka는 이것을 어떻게 해결해내는지 알아봅시다.
사실 Consumer는 데이터를 직접 읽어가기 때문에 데이터 유실에 대해서는 걱정할 필요가 없다고생각합니다(필자의 판단).
하지만 Producer는 데이터가 kafka의 Topic에 잘 들어갔는지 어떻게 알 방법이 없습니다!!!그래서 Kafka는
Ack을 활용하여 Producer에게 데이터가 잘 들어갔는지 알려줍니다.
Kafka는 Acks의 세가지 모드를 가지게 하는데 각 모드에 대해 알아봅시다. -
acks = 0
이 옵션일 경우에는 메세지를 보내는 속도는 제일 빠르지만 메세지가 유실될 확률은 제일 높습니다. 그 이유를 그림과 함께 이해 해봅시다.
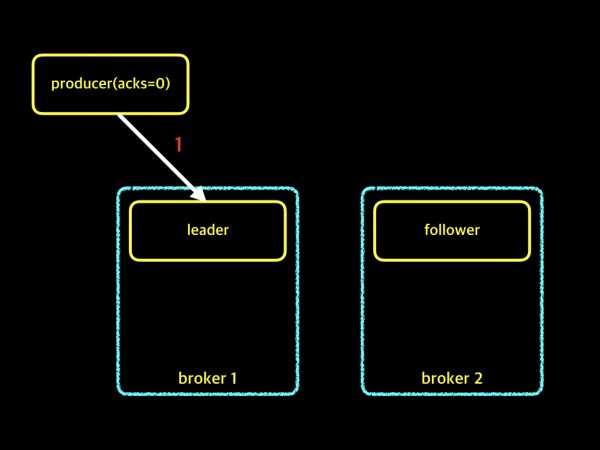
위의 그림을 보면 producer는 broker중 leader Partition에게 단지 데이터를 전달해주기만 합니다. 그렇기에 과연 Leader의 Partition이 Replication을 잘 수행하여 Follower에게 잘 전달했는지 알 수 있는 방법은 없습니다. 하지만 단순히 전달하기만 하면 Flow가 끝나기에 메세지 전달속도는 제일 빠릅니다.
-
acks = 1
이 옵션일 경우는 acks = 0인 경우보다 속도는 느리지만 메세지의 유실률을 줄일 보다 줄일 수 있다는 점이 있습니다.
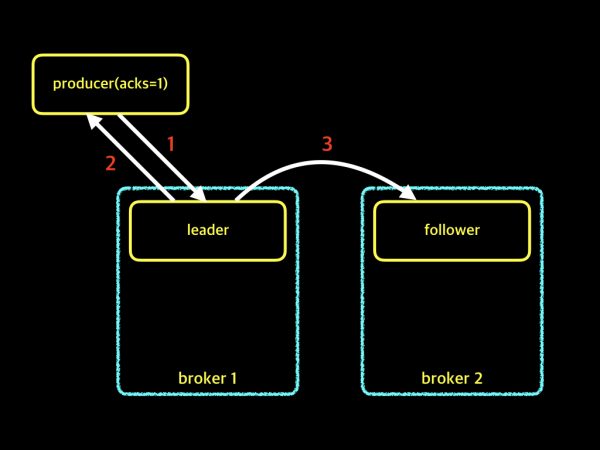
위의 그림을 보시면 이전 보다 다른 것을 확인 할 수 있습니다. 위의 경우를 설명해 드리자면, producer는 Leader에게 데이터를 전송하고 Leader는 잘 받았다는 응답을 전달합니다. 그 후 Follower들에게 Replication 작업을 실시합니다. 이렇기에 기존에 단지 메세지만 전달하는 경우보다 유실률을 줄 일 수 있지만, 잘 받았다는 응답을 기다려야 Flow가 종료되기 때문에 전송 속도는 보다 느릴 수 있습니다.
-
그러면 akcs = 1인 경우에는 언제 유실이 생길지 의문이 드실 껍니다. 바로 Leader는 제대로 받았지만 그 후에 Leader가 Down되는 경우가 생기면서 Follower가 Leader로 바뀌는 상황입니다. 그러면 Producer가 전달한 메세지를 새로운 Leader는 가지지 않고 있기에 유실이 생깁니다!
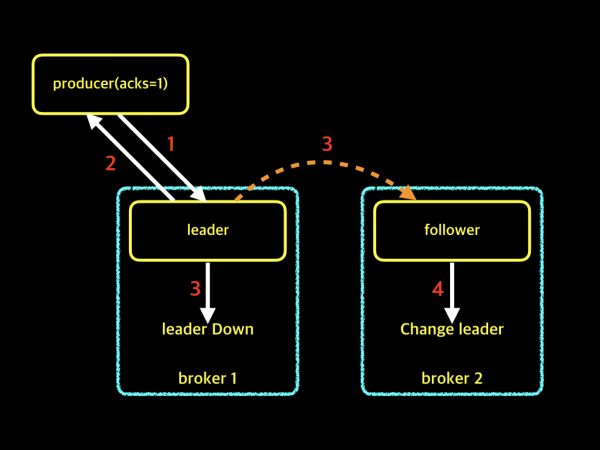
하지만 위의 상황이 빈번하게 일어나지 않을 뿐더러, 메세지 전송 속도 Service에서 중요한 스펙이기에 대부분 acks=1을 많이 채택합니다.
- acks = -1(all)
이제 위에 모드 두개를 보셨으면, acks = -1은 어느 정도 감이 오셨을 것입니다. 생각하신게 아마 맞으실껍니다!! 바로 Replication까지 이뤄진 것을 확인하고 Producer에게 응답해주는 것입니다.
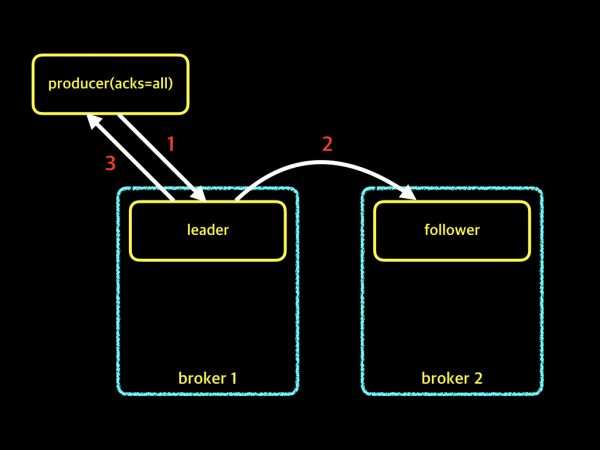
이 경우에는 데이터 유실은 거의 0에 가깝다고 볼 수 있습니다. 하지만 그에 비해 메세지 전송속도는 더 느려질 수 밖에 없는 Trade-off를 경험하게 됩니다. 만약 구축하고자 하는 Service가 데이터 유실이 매우 큰 크리티컬하다면 이 모드를 택하시는게 옳을 것입니다!!
Registry Schema??
위의 글을 읽으면서 혹시 이런 의문이 들지 않나요????
"Producer가 메세지 보내는 형태를 바꾸면 Consumer는 어떻게 할까??"
정답은 못 읽어낸다!!!입니다.
왜냐하면 Consumer와 Producer는 Broker를 통해 메세지를 주고 받기에 서로에 대해 알지 못합니다. Consumer는 그저 Topic을 구독하여 소비할 Message를 가져오기 때문입니다.
"여기서 또 의문??? 그냥 가져와서 잘 읽으면 되는거 아닌가??"
그렇게 생각할 수 있습니다. 필자도 그렇게 생각했었습니다. 하지만 Kafka는 Record의 자료형태를 Serializer 변환을 거치고 Consumer는 Desrializer 변환을 거쳐야합니다. 그래서 기존 Topic의 Message에 맞는 Serializer,Deserializer Class를 생성합니다. 이처럼 내부적으로는 결국 강한 의존 관계를 가지게 되는 것입니다.
이런 의존 관계를 극복하고자 개발자들은 Registry Schema라는 것을 도입합니다.
위의 그림처럼 Schema Register에 등록되어있는 스키마를 읽고 스키마가 바뀌어도 등록되어있는 스키마라면 읽어낼 수 있게끔 하는 것입니다.

위의 글과 그림만 보면 이해하기 힘들기에 Schema Registry의 호환성 강제 규칙에 대해 간다하게 그림과 함께 이해하고 넘어가봅시다.
-
운영자는 스키마를 등록하여 사용할 수 있지만, 스키마 버전 별 호환성을 강제함으로써 일종의 개발 운영 규칙을 세우는 것입니다. 스키마 호환성은 크게 Backward, Forward, Full, None 이 있습니다. 간단히 버전 1,2 스키마를 예를 들어 설명하면 다음과 같습니다.
-
Backward :
컨슈머는 2번 스키마로 메시지를 처리하지만 1번 스키마도 처리할 수 있습니다
필드 삭제 혹은 기본 값이 있는 필드 추가인 경우 -
Forward :
컨슈머는 1번 스키마로 메시지를 처리하지만 2번 스키마도 처리할 수 있습니다.
필드 추가 혹은 기본 값이 있는 필드 삭제 -
Full :
Backward와 Forward를 모두 가집니다.
기본 값이 있는 필드를 추가 혹은 삭제 -
None :
스키마 호환성을 체크하지 않습니다.

글을 마무리 지으며
Kafka에 대해 전반적으로 필수 요소 및 개념들에 대해 정리해보았습니다. 아마 이보다 훨씬 많은 개념과 어려운 내용들이 있을 것이지만, 그것은 직접 프로젝트 및 체험해보길 바랍니다. Kafka에 대한 이해도 중요하지만!! 왜 이것을 써야하는지??? 그것을 생각하면서 공부하시길 바랍니다. 필자도 아직 부족하기에 틀린 내용이 있다면 댓글로 알려주시면 감사하겠습니다 ㅎㅎ
다음 글은 Kafka를 셋팅하는 과정과 Spring Boot와 연동하는 과정을 보여드릴 예정입니다. 오늘도 먼가를 배우고 성장하는 하루이길 바랍니다!
Reference
https://always-kimkim.tistory.com/entry/kafka101-schema-registry
https://always-kimkim.tistory.com/entry/kafka101-broker
https://magpienote.tistory.com/251
