ElasticSearch란??
ElasticSearch는 간단하게 말씀 드리면 검색 및 분석엔진으로써 대용량의 데이터를 신속하게 검색하고 분석하는 데 사용되는 오픈 소스 솔루션입니다.
근데 여기서 중요한 점!! 그러면 기존 RDB와 NoSql DB들과의 차이점이 무엇이고 장점이 무엇인지???
- DataModel의 차이
- RDBMS는 Table이라는 Schema를 가집니다.
- 그에 반에 ElasticSearch는 NoSql과 같이 스키마가 없어 자유롭습니다.
- 데이터 쿼리
- RDBMS는 SQL을 통해 쿼리가 수행됩니다!
- NoSQl은 특화된 API를 통해 쿼리가 수행됩니다.
- ElasticSearch는 REST API를 사용하여 데이터를 쿼리합니다.
- 검색
- Text를 검색할 때 기존 RDBMS Like 연산을 통해서 해당 단어가 포함된 Text를 검색해옵니다. 이 때 RDBMS는 1000개의 data가 있으면 1000개의 데이터를 다 조회하면서 Like 연산을 진행합니다.
- NoSql의 경우는 자체 함수와 정규식을 활용하는데요, 에를 들어 Mongo DB는 find라는 함수와 정규식을 통해 찾아냅니다.
- ElasticSearch는 역인덱스화(역색인)라는 것을 통해 매우 빠르게 찾아 냅니다.간단히 말씀을 드리면 키워드를 통해 문서를 찾아내는 방식입니다. 그림과 함께 이해 봅시다.
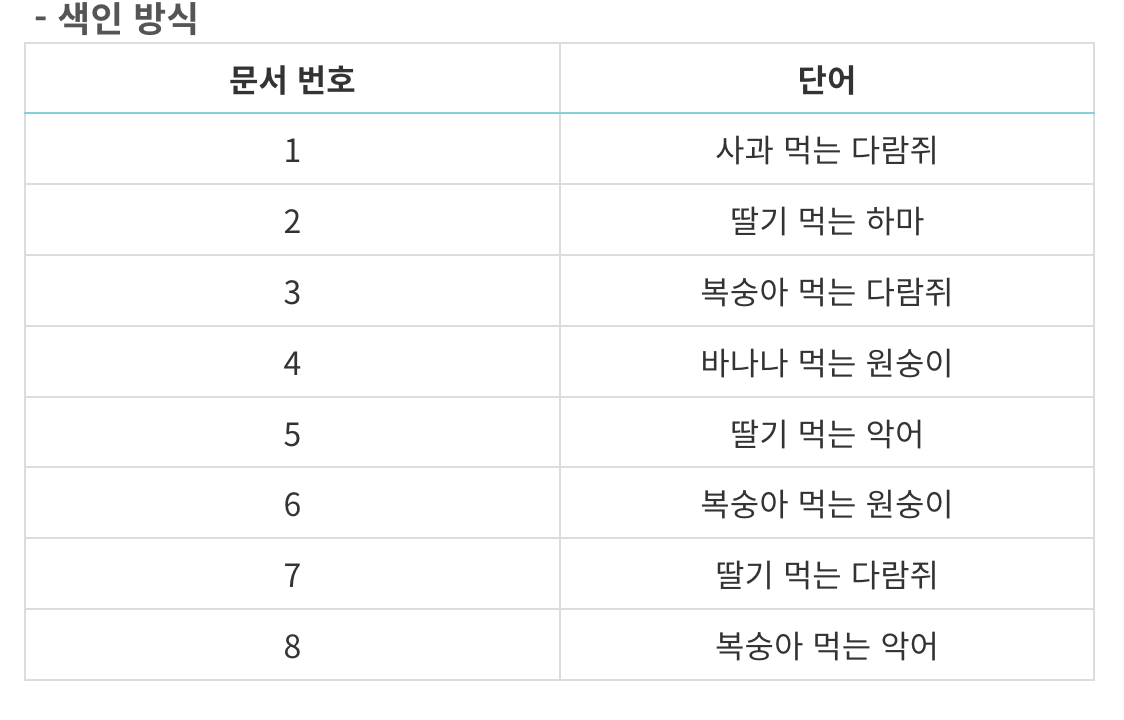
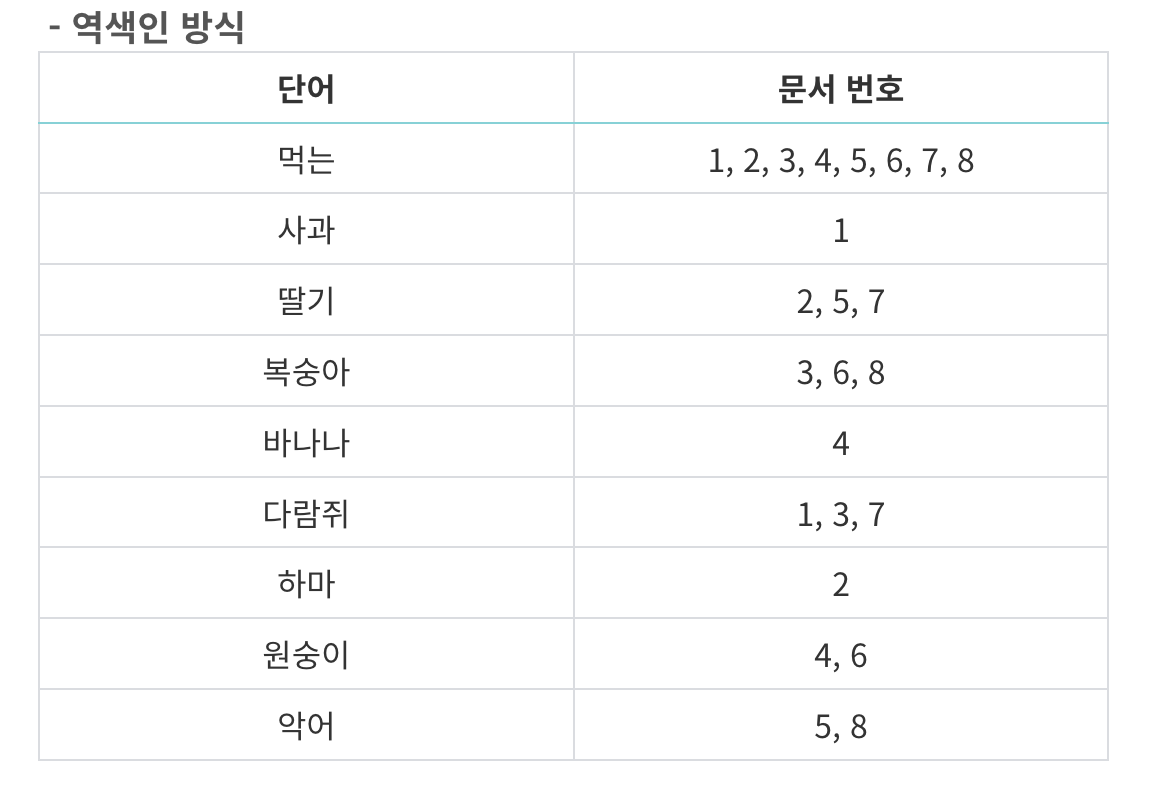
추가적으로 Elasticsearch는 score를 알려줍니다. score는 검색한 대상이 일치 정도를 점수로 반환해주는데 이를 통해 검색을 했을 때 정확도 순 등 다양하게 활용할 수 있습니다.
- 확장성
- RDBMS는 Schema의 자유로움이 없기에 확장을 할 때 주로 Scale up을 택합니다. 하지만 대용량 데이터 처리에서는 무작정 Scale up보다 Scale out이 유리합니다.
- ElasticSearch는 애초에 Cluster와 노드로 구축되어있으며 인덱스 내부에 샤딩으로 처리가 되어있습니다. 그렇기에 Scale out을 통해 대용량 처리에 매우 유리합니다.
ElasticSearch의 세부 내용!!
우리는 위에서 간단히 ElasticSearch를 왜 쓰는지 장점이 무엇인지에 대해 가볍게 정리해 봤습니다. 이제 부터는 ElasticSearch에 대한 세부 적인 내용을 알아보고자 합니다.
데이터 구조
ElasticSearch는 엄연히 Database는 아니지만 Database의 역할도 합니다. 그러면 기존의 DB와 다르게 어떻게 구성되었는지 보고 넘어갑시다.
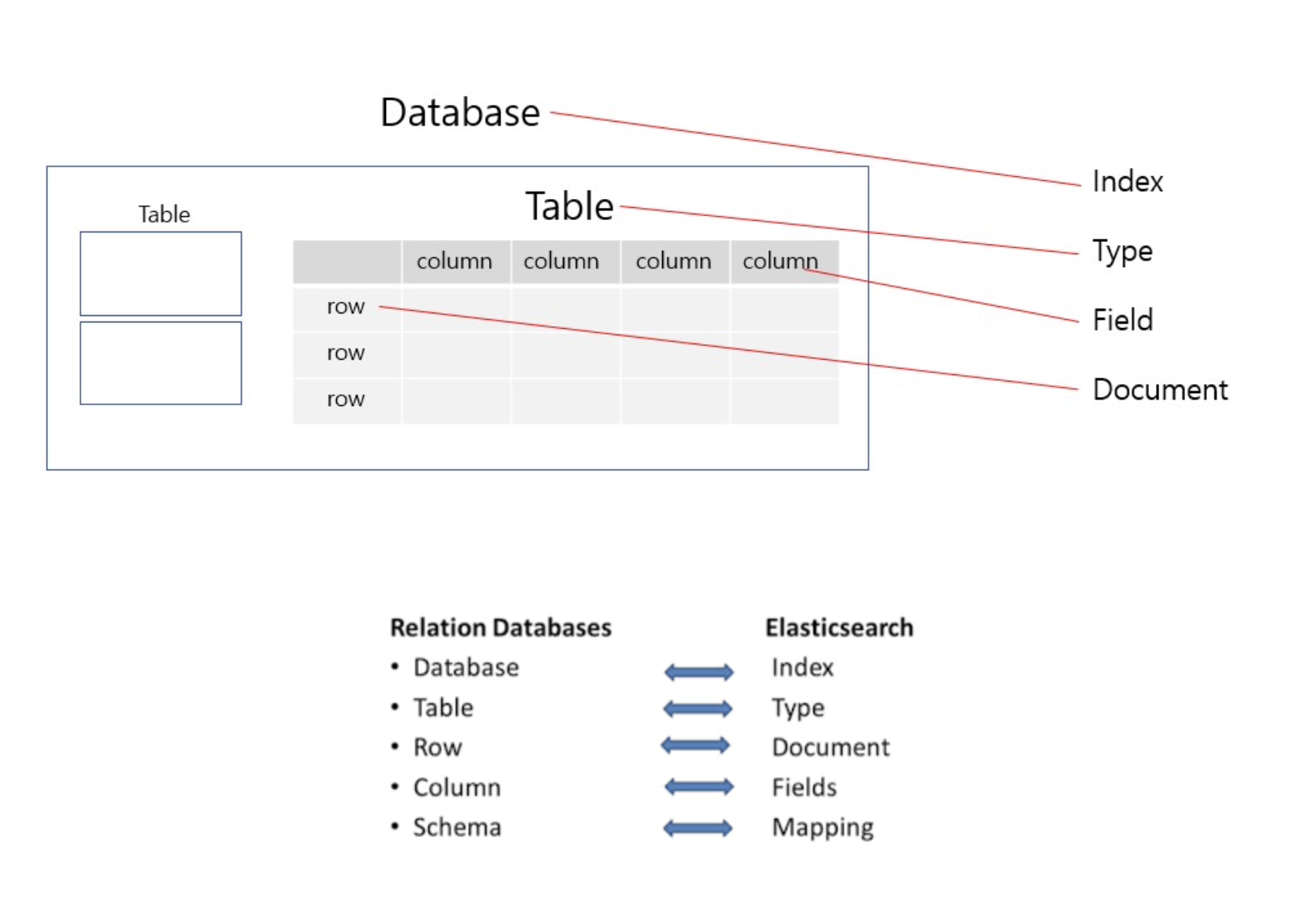
위에서 최근 7.x 버전 이상부터는 Type은 사라지고 Index가 그 역할까지 대신합니다.
전체적인 구조
위에서 간단히 말씀드린 것처럼 ElasticSearch는 클러스터와 노드 그리고 Index를 샤딩해놓은 구조를 가진다고 말씀드렸던 적이 있습니다. 아래의 그림과 같은 구조를 가진다고 생각하시면 편합니다.
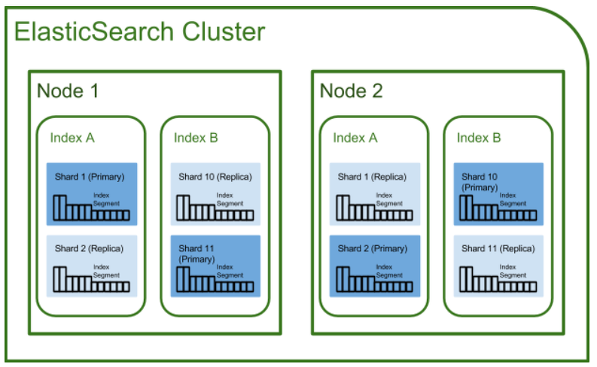
그러면 위의 구조들을 하나씩 알아봅시다.
Cluster?
ElasticSearch에서 가장 큰 단위로, 노드들의 집합이라 생각하시면 됩니다.(Kubernetes의 클러스터와 비슷한 개념인거 같습니다.)
서버들은 클러스터를 여러 개를 생성하므로 Scale out이 가능합니다. 하지만 클러스터들은 각자 독립적이기 때문에 서로 연결할 수 없습니다.
Node?
ElasicSearch를 이루는 하나의 인스턴스라고 생각하시면 편합니다. 노드들은 종류가 여러 개이며 각자의 역할을 가지고 있습니다.
- Master Node
클러스터와 다른 노드들을 관리하고 제어하는 Node입니다.
인덱스 생성, 삭제, 데이터를 어떤 샤드에 할당할지에 결정하는 역할을 수행합니다. - Data Node
실질적인 데이터를 저장하는 노드입니다. 데이터가 실제로 분산 저장되는 물리공간인 샤드가 배치되어 있습니다. - Ingest Node
데이터를 변환하는 등 사전 처리 파이프라인을 실행하는 역할을 하는 노드입니다. - Coordinationd Node
사용자의 요청을 받아서 클러스터 관련 요청은 마스터 노드에 전달하고, 데이터 관련 요청은 데이터 노드에 전달하는 역할을 담당합니다.
별도로 지정하지 않았다면 모든 노드가 코디네이션 노드 역할을 수행하게 됩니다.
Shard?
- 인덱스 내부에는 색인된 데이터들이 존재하는데 이 데이터들은 물리적 공간에 여러 개로 나뉘어서 존재합니다. 이러한 부분을 샤드(shard)라고 합니다. 샤드는 루씬의 단일 검색 인스턴스입니다.
- 처음 생성된 샤드를 Primary Shard(프라이머리 샤드), 복제본을 Replica(레플리카)라고 지칭합니다.
- 레플리카는 원본 shard가 장애가 발생하더라도 복제본 shard를 통해 데이터를 제공할 수 있어 장애 대응에 효과적입니다.
주의사항 !!
노드가 1개만 있는 경우 프라이머리 샤드만 존재하고 복제본은 생성되지 않는다. ES는 아무리 작은 클러스터라도 데이터 가용성과 무결성을 위해 최소 3개의 노드로 구성할 것을 권장한다.
데이터 처리는 어떻게 하는거야???
ElasticSearch는 데이터 형식이 JSON이며,이 뿐만 아니라 쿼리와 정보를 주고 받을 때도 JSON 형식입니다. SQL같은 구문 없이 REST API를 통해서 데이터 처리를 진행합니다.
즉 우리가 알고 있는 CRUD를 GET,POST,PUT,DELETE를 통해서 진행합니다.
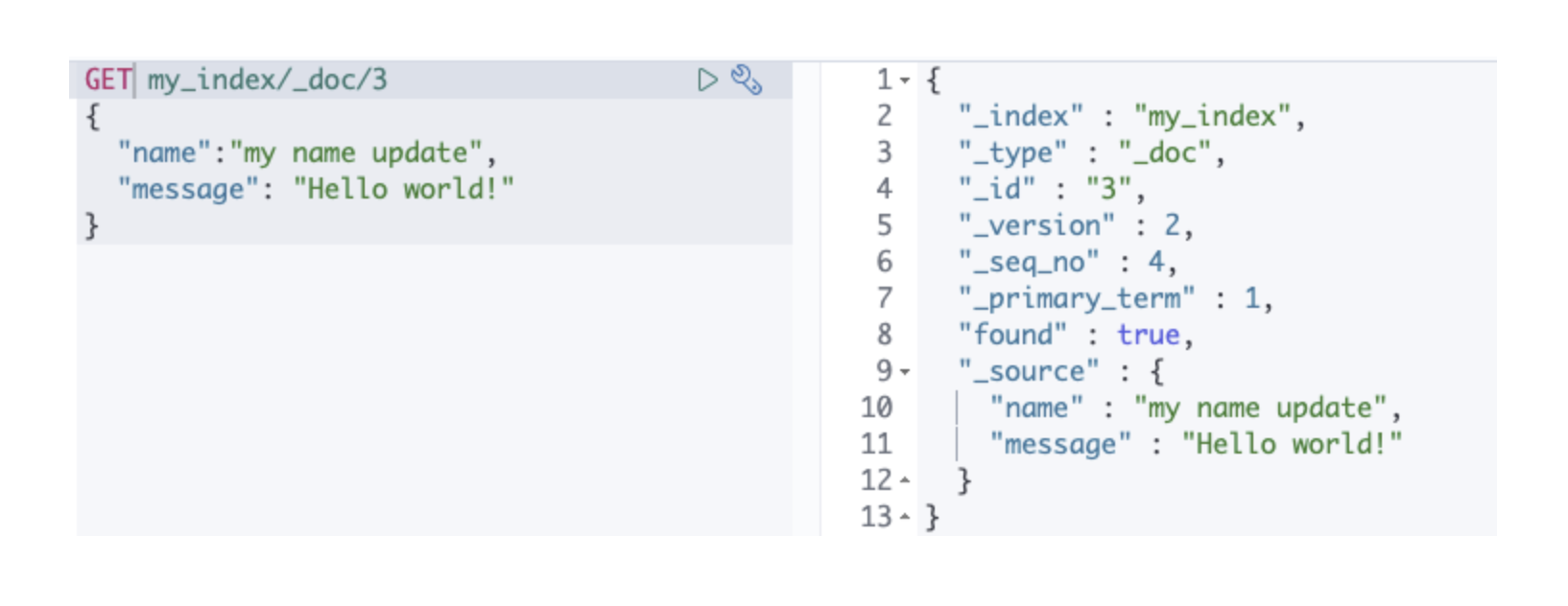
위의 그림처럼 메소드를 바꿔가면서 쿼리를 작성해나가면서 데이터 처리를 할 수 있습니다.
위의 사진처럼 작성 방법은 Kibana에서 DevTools라는 도구를 통해 쉽게 작성해 나갈 수 있습니다.
하지만 필자는 ELK를 저렇게 Kibana에서 작성하며 조회할려고 하는 것이 아니라 REST API 요청을 서버로 받아들이고 서버에서 쿼리를 작성해 ES에서 CRUD를 하는 것 궁극적인 목표이기에 이 부분은 이 정도로 설명하고 마치겠습니다.
역인덱스와 텍스트 분석??
역인덱스에 대해서는 아까 ElasticSearch의 차이점과 장점을 설명드릴때 설명드렸습니다.
ES는 역인덱스화를 통해 Data를 분류하고 저장해놓습니다. 역인덱스화는 데이터가 증가해도 키워드에 해당하는 Data가 증가하는 것이기 때문에 속도측면에 큰 영향을 주지 않는 장점이 있습니다.
텍스트 분석
ES에서는 문자열을 저장할시 여러 단계를 거칩니다. 이러한 전반적인 과정을 텍스트 분석이라고 부릅니다.
이 과정을 처리하는 기능을 Analyzer라고 부릅니다. 그리고 아래와 같이 3가지로 구성되어있습니다.
- Character Filters
- Tokenizer
- Token Filter
아래의 그림을 보면 쉽게 이해하실 수 있습니다.
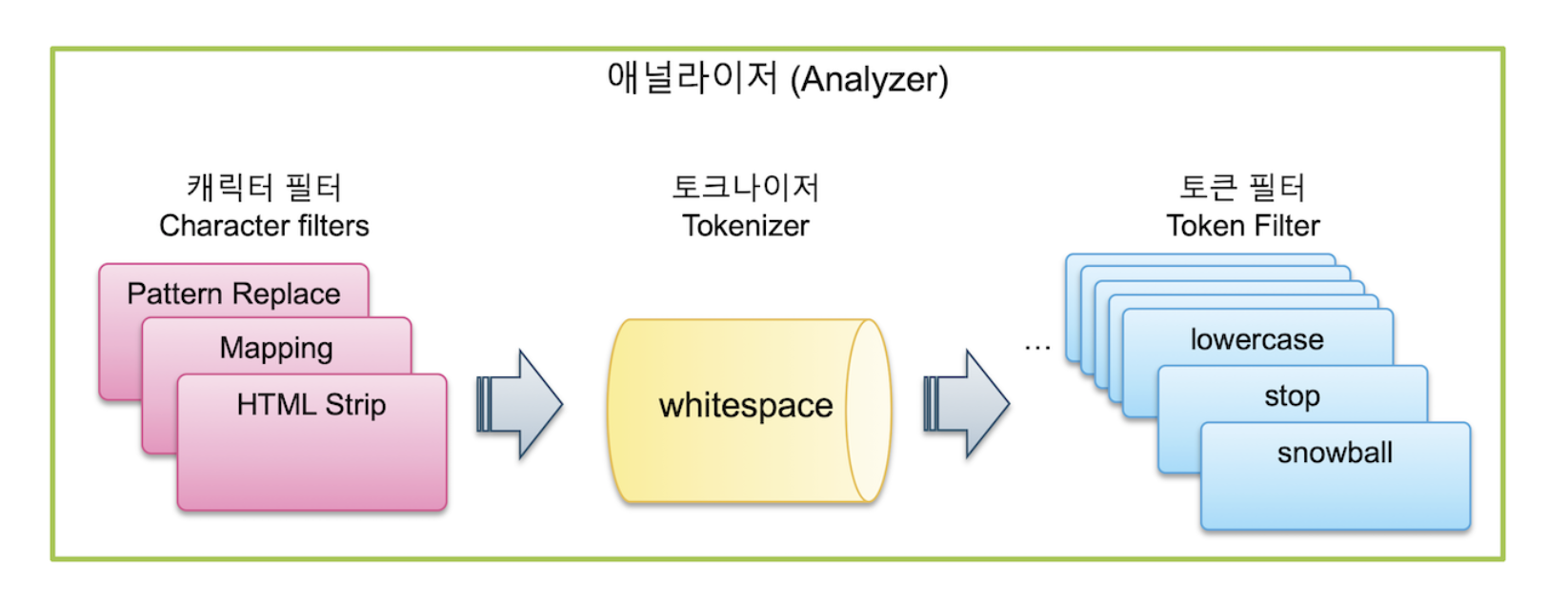
각각의 필터와 토크나이저에 대한 부분은 CQRS 도입기에서 다루기에는 너무 길기에 나중에 다루는 글을 따로 작성해보도록 하겠습니다!!!
글을 마치며
ElasticSearch에 대해 간단히 정리하는 글을 작성해보았습니다. 필자가 다룬 것은 정말 기초적인 부분이라 생각합니다. ES는 현재 검색 및 분석엔진으로써 1위를 지키고 있을 만큼 빅데이터 및 IoT등 다양한 분야에서 많이 쓰입니다. 여러분들도 저의 글을 읽으면서 더 알고 싶은 부분을 좀 더 직접 찾아보며 공부를 진행해보셨으면 좋겠습니다!!!
다음 글은 이제 AWS에서 어떻게 ELK 스택을 구축해 나갔는지 작성하는 글로 찾아오겠습니다 ㅎㅎㅎ
