ELK 왜 써??
저번 글을 끝으로 CUD 서버와 Kafka의 셋팅을 마쳤습니다. 이제부터는 Reading쪽에 관한 모든 것을 정리하고 시작하고자 합니다.
간단한 플로우를 보여드리면 아래와 같습니다.
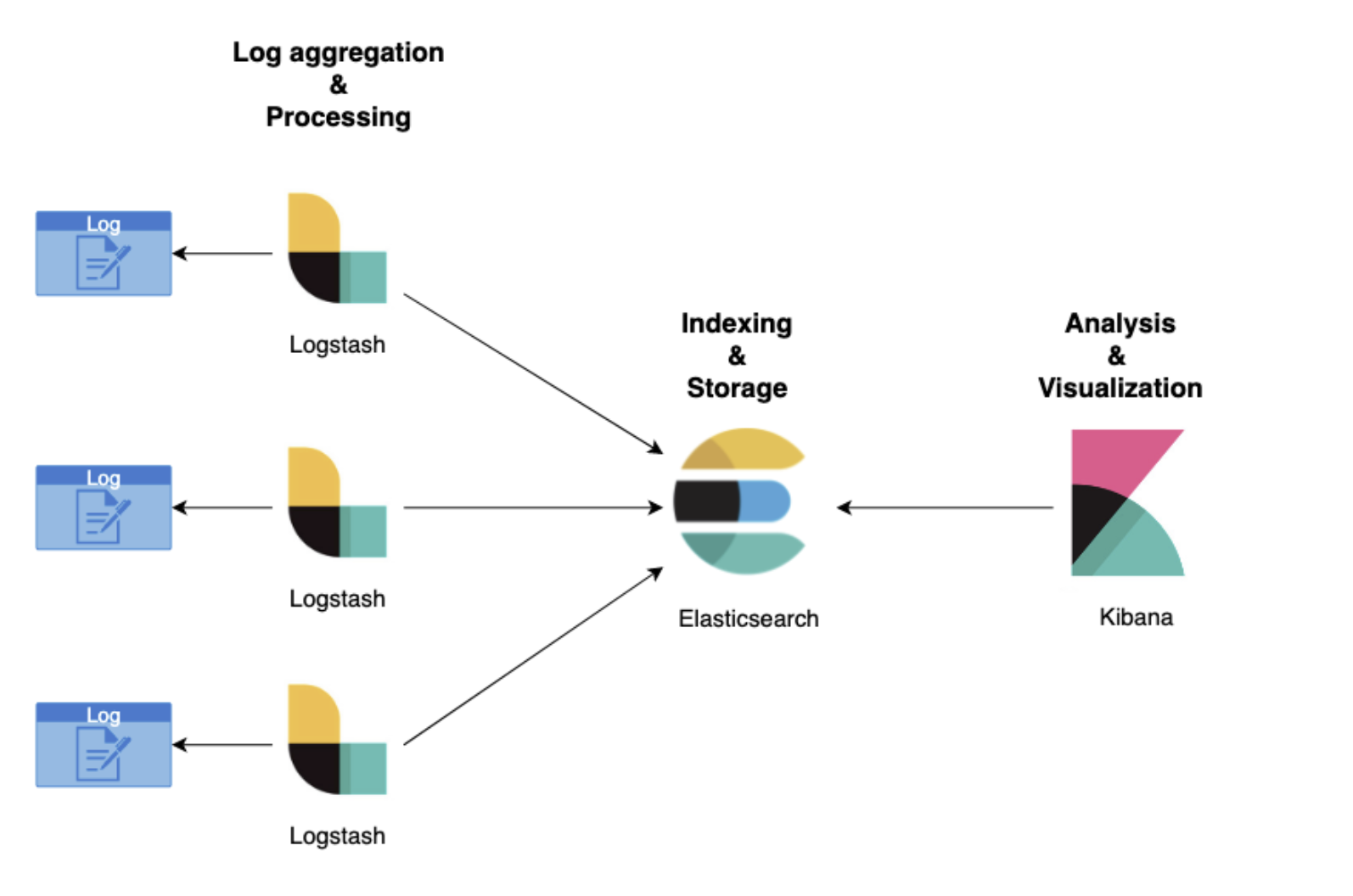
- 왜 ELK를 택하셨습니까???
늘 해당 기술 스택을 쓸 때 내가 왜 쓰는지??그리고 어떤 장점이 있길래 쓰는지에 대한 의문과 해답을 갖고 있어야합니다.- 첫 번째 오픈 소스 입니다.
이는 자유롭게 쓸 수 있으며, 비용을 지불하지 않고 개발자들의 지속적인 업그레이드가 있습니다.- 두 번째 Log의 중요성
알지 못한 이유의 에러가 발생했을 때 우리가 에러를 분석할 수 있는 법은 Log를 분석하는 법입니다. ELK스택은 Log 데이터의 수집, 분석, 시각화까지 한번에 진행할 수 있는 데이터 파이프 라인 입니다.- 세 번째 ElasticSearch의 장점
ElasticSearch는 역인덱스를 통해 기존 RDBMS의 Like 연산보다 빠른 검색 속도를 자랑합니다.
위의 세 가지를 제외하고도 Json 형태의 Document 관리, RestAPI 형식 사용 등 이점들이 존재합니다.
Logstash?
로그스태시는 간단하게 요약하자면 Log들을 정제하는 Pipeline을 제공하는 오픈 소스라고 생각하시면 편합니다.
- 여기서 의문 왜 정제를 하는가??
Log란 정해져있는 정형적인 데이터가 아닙니다. 이런 데이터를 우리가 알아보고 분석할 수 있도록 하기 위해서는 정제하는 과정을 거쳐야합니다!!!
LogStash는 정제하는 역할에서 다양한 기능들을 가지고 뛰어난 능력을 보여줍니다.
-
다양한 타입의 데이터 처리 가능 : Json,XML 등의 구조화된 텍스트 뿐만 아니라 다양한 데이터 형태의 데이터 가공이 가능합니다.
-
플러그인 기반 : 플러그인 기반이기에 다양한 플러그인의 조합으로 처리가 가능하게끔 만들 수 있고, 쉽게 개발이 가능하기에 지속적으로 플러그인들이 나오고 있습니다.
-
Elastisearch와 Kibana의 강력한 결합 : 다들 ELK를 기술 스택으로 묶어서 쓰는 이유가 서로한테 최적화된 서비스를 제공하기 때문입니다. 장점이자 단점이 될 수 있습니다.
-
성능: 자체적으로 내장되어 있는 메모리와 파일 기반의 큐를 사용하므로 처리속도와 안정성이 높다. 인덱싱할 도큐먼트의 수와 용량을 종합적으로 고려해 벌크 인덱싱을 수행할 뿐 아니라 파이프라인 배치 크기 조정을 통해 병목현상을 방지하고 성능 최적화를 할 수 있다.
-
안정성: 엘라스틱 서치의 장애 상황에 대응하기 위한 재시도 로직이나 오류가 발생한 도큐먼트를 따로 보관하는 데드 레터 큐를 내장하고 있다.
Pipeline은 무엇인가???
- LogStash에서 Pipeline은 데이터를 실시간으로 입력받아 가공하여 다른 시스템에게 전달하는 과정을 말합니다.
- Input,Filter,Output 세 가지의 구성요소로 이뤄져있습니다.
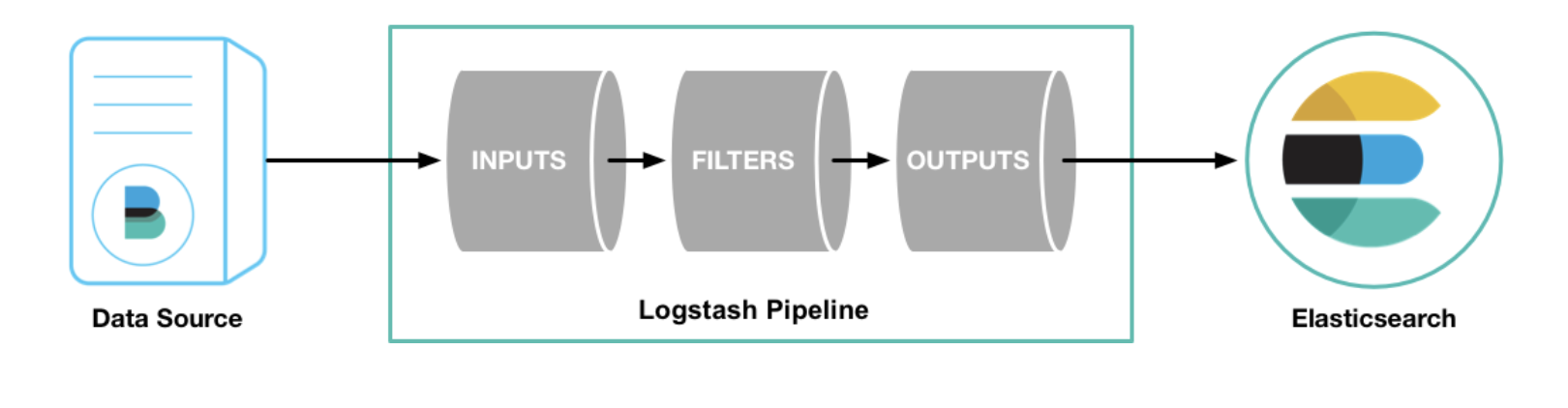
간단하게 Input,Filter,Output에 대한 설명을 진행하고 Logstash를 마치겠습니다.
Input(입력 )
- Pipeline의 가장 앞단에 위치하며 Source로 부터 데이터를 입력받습니다.
- Logstash는 플러그인 기반이기에 Inputs에서도 다양한 플러그인들이 존재합니다.
- 자주 사용하는 플러그인
- file : 리눅스의 tail -f 명령처럼 파일을 스트리밍하며 이벤트를 읽어들인다.
- syslog : 네트워크를 통해 전달되는 시스로그를 수신
- kafka : 카프카 토픽에서 데이터를 읽어드린다.
- jdbc: JDBC 드라이버로 지정한 일정마다 쿼리를 실행해 결과를 읽어들인다.
Filter(필터 )
-
입력 받은 비정형 데이터들을 사용자가 사용할 수 있게 가공이 일어나는 단계
-
자주 사용하는 플러그인
- grok : grok 패턴을 사용해 메시지를 구조화된 형태로 분석한다. grok 패턴은 일반적인 정규식과 유사하나, 추가적으로 미리 정의된 패턴이나 이름 설정, 데이터 타입 정의 등을 도와준다.
- dissect : 간단한 패턴을 사용해 메시지를 구조화 된 현태로 분석한다. 정규식을 사용하지 않아 grok에 비해 자유도는 조금 떨어지지만 더 빠른 처리가 가능하다.
- mutate : 필드명을 변경하거나 문자열 처리 등 일반적인 가공 함수들을 제공한다.
- date : 문자열을 지정한 패턴의 날짜형으로 분석한다.
Output(출력 )
-
Output은 파이프 라인의 입력과 필터를 거쳐 가공된 데이터를 지정한 대상으로내보내는 단계다.
-
자주 사용하는 플러그인
- elasticsearch: bulk API를 사용해 엘라스틱 서치에 인덱싱을 수행
- file : 지정한 파일의 새로운줄에 데이터 기록
- kafka : 카프카 토픽에 데이터를 기록
Pipeline 템플릿 예시

글을 마치면서
ELK 스택에서 LogStash에 대한 이론적인 정리와 함께 ELK에 대한 정리를 시작했습니다. 기존의 Spring boot와 RDBMS외에도 수 없이 많은 오픈소스들이 많다는 것을 알게 되는 시간이였으면 합니다.
그리고 개발자는 그 기술 스택을 왜 쓰게 되었고, 어떤 점이 좋은지 다시 생각하는 시간을 가져야한다고 생각합니다!!!!
다음 글은 ElasticSearch에 대해 정리하면서 돌아오겠습니다.
