Reading Server??
우리는 CUD서버와 ELK 스택 구축까지 마무리하였습니다. 이제 마지막으로 CQRS 구조에서 Reading을 담당하는 Server를 구축하는 것만 남았습니다.
필자는 Spring boot를 통해 구축하였습니다!!
Dependency 추가
spring boot에서는 ElasticSearch에 접근하기 위해 springboot-data-elasticSearch package를 제공합니다. 우리는 이것을 활용하기 위해 Dependency에 추가해줍시다.
plugins { id 'java' id 'org.springframework.boot' version '3.0.5' id 'io.spring.dependency-management' version '1.1.0' } group = 'com.example' version = '0.0.1-SNAPSHOT' sourceCompatibility = '17' configurations { compileOnly { extendsFrom annotationProcessor } } repositories { mavenCentral() } dependencies { implementation 'org.springframework.boot:spring-boot-starter-web' compileOnly 'org.projectlombok:lombok' developmentOnly 'org.springframework.boot:spring-boot-devtools' annotationProcessor 'org.projectlombok:lombok' testImplementation 'org.springframework.boot:spring-boot-starter-test' implementation 'org.springframework.boot:spring-boot-starter-data-elasticsearch' implementation 'org.springframework.data:spring-data-elasticsearch:4.2.11' }참고로 버전마다 Deprecated된 메서드들이 존재하므로 확인을 잘하고 사용하시길 바랍니다.
그리고 빠르게 버전들이 올라오고 있기에 서비스에 맞는 버전을 맞게 활용하시길 바랍니다.(Spring 공식 홈페이지에 가면 ES 버전에 맞는 package버전을 추천해줍니다.)
Confing 작성
@Configuration @EnableElasticsearchRepositories @Slf4j public class ESConfiguration extends AbstractElasticsearchConfiguration { @Override public RestHighLevelClient elasticsearchClient() { log.info("elasticsearch configuration"); // http port 와 통신할 주소 주소바꿔줘야하고 ClientConfiguration configuration = ClientConfiguration.builder() .connectedTo("search-elastic-search-uczx3ownbwrizbitzuyg5pkmse.ap-northeast-2.es.amazonaws.com:443") .usingSsl() .withBasicAuth("auto-ever-master", "Qw12345678!") .build(); return RestClients.create(configuration).rest(); } @Override public ElasticsearchOperations elasticsearchOperations(ElasticsearchConverter elasticsearchConverter, RestHighLevelClient elasticsearchClient) { return new ElasticsearchRestTemplate(elasticsearchClient()); }위의 Config 클래스를 보시면 두가지의 Bean을 확인하 실 수 있습니다. 첫번째 RestHighClient, 두 번째 ElasticsearchOperations 입니다.
- RestHighClient는 이름 그대로 java에서 제공하는 고수준 REST API를 위해 제공하는 기능입니다.
- ElasticSearch는 세부내용이 많아질 수 있고, 쿼리문의 복잡성과 디코딩등 기존 통신보다 복잡할 가능성이 높기에 고수준 REST API 통신을 권장합니다.
- ElasticSearchOperations는 Elasticsearch에 대한 CRUD 작업을 수행하는 데 사용되는 인터페이스입니다. 인덱스 생성, 문서 저장 및 쿼리와 같은 작업을 수행하는 데 사용할 수 있습니다.
- ElasticSearchOperations는 RestHighLevelClient를 기반으로 하므로 RestHighLevelClient의 모든 기능을 사용할 수 있습니다.
Entity 및 Repository 작성
Spring boot는 ElasticSearch를 JPA처럼 맵핑하여 편하게 쓸 수 있도록 제공합니다. 그렇기에 JPA처럼 Entity와 Repository 클래스를 작성해줍니다.
Entity 클래스 먼저 보시죠!!
@Data @NoArgsConstructor @AllArgsConstructor @Document(indexName = "topic-kid") @Mapping(mappingPath = "classpath:elastic/settings/Man-mappings.json") @Setting(settingPath = "classpath:elastic/settings/Man-settings.json") public class Man { @Id private String id; @Field(type = FieldType.Text) private String name; @Field(type = FieldType.Integer) private Integer age; @Field(type = FieldType.Text) private String hobby; @Field(type = FieldType.Integer) private Integer height; @Field(type = FieldType.Text) private String job; @Field(type = FieldType.Text) private String tech; @Field(type = FieldType.Text) private String githubUrl; }
- ES에서는 Document가 RDBMS의 Table과 같은 존재이기에 @Document에 해당하는 IndexName을 작성해 매핑을 시작합니다.
- 그 다음 @Mapping과 @Setting을 통해 Index안의 데이터들을 어떻게 Mapping 하고 Nori와 같은 Tokenizer들을 Setting할지 정합니다.
- 그리고 ES는 Column이 없고 모두 Field로 선언되고 매핑을 합니다.
Repository 작성
public interface ManRepository extends ElasticsearchRepository<Man, String> { }이 Repository Class는 JPA에서 Repository를 만들때와 똑같은 녀석입니다.
@RequiredArgsConstructor @Repository @Slf4j public class ManSearchQueryRepository { private final ElasticsearchOperations operations; public List<Man> test(SearchManCondition searchManCondition) { // CriteriaQuery query = createlikesCriteriaQuery(searchManCondition); SearchHits<Man> search = operations.search(query, Man.class); System.out.println(search); log.info("search ={}", search); return search.stream().map(SearchHit::getContent).collect(Collectors.toList()); // return null; } private CriteriaQuery createlikesCriteriaQuery(SearchManCondition searchManCondition) { CriteriaQuery query = new CriteriaQuery(new Criteria()); // Man man = new Man(); if (StringUtils.hasText(searchManCondition.getHobby())) { query.addCriteria(Criteria.where("hobby").contains(searchManCondition.getHobby())); } if (StringUtils.hasText(searchManCondition.getGithubUrl())) { query.addCriteria(Criteria.where("githubUrl").contains(searchManCondition.getGithubUrl())); } if (searchManCondition.getAge() > 60) { query.addCriteria(Criteria.where("age").is(searchManCondition.getAge())); } if (searchManCondition.getHeight() > 50) { query.addCriteria(Criteria.where("height").is(searchManCondition.getHeight())); } return query; } }
- 반면에 이 Repository는 실제로 들어오는 Reading 요청에 따라 쿼리가 동작하도록 쿼리를 작성한 Repository인데요.
- Spring boot에서 ES를 위한 쿼리를 짤 때 총 3가지 방법이 있습니다.
- 문자열 쿼리, Native 쿼리,Criteria 쿼리
필자는 위의 세 가지 방식 중 Criteria 쿼리로 작성했습니다.
그 이유는 Criteria 쿼리는 Query Dsl과 같이 java 코드를 통해 쿼리를 작성해 나가며, 객체지향적이기에 읽기도 편하고 쿼리의 정확한 뜻을 이해하기에 편하기 때문이였습니다.
SearchHits는 무엇인가요???
- SearchHits는 Elasticsearch에서 쿼리 결과를 나타내는 클래스입니다. 각 SearchHit는 Elasticsearch에서 검색된 문서를 나타내며 다음 속성을 포함합니다.
- id: 문서의 ID
- score: 문서에 대한 점수
- source: 문서의 원본 데이터
- SearchHits는 Elasticsearch에서 쿼리 결과를 반환하는 데 사용되며 반복하여 각 문서를 검색할 수 있습니다. SearchHits는 또한 문서의 수를 얻고 정렬하고 필터링하는 데 사용할 수 있습니다.
Service 작성
@RequiredArgsConstructor @Service public class EsService { private final ManSearchQueryRepository manSearchQueryRepository; private final ElasticsearchOperations elasticsearchOperations; public List<Man> getMan(String hobby, String githubUrl, Integer height, String name, Integer age) { // SearchManCondition searchManCondition = SearchManCondition.builder() .hobby(hobby) .githubUrl(githubUrl) .age(age) .height(height) .name(name) .build(); return manSearchQueryRepository.test(searchManCondition); }
- 마지막으로 Service에서는 Controller에서 받아온 paramter를 DTO에 할당한 후 Repository의 test 메소드를 실행시켜 조회 값을 받아오도록 설정해 놓았습니다.
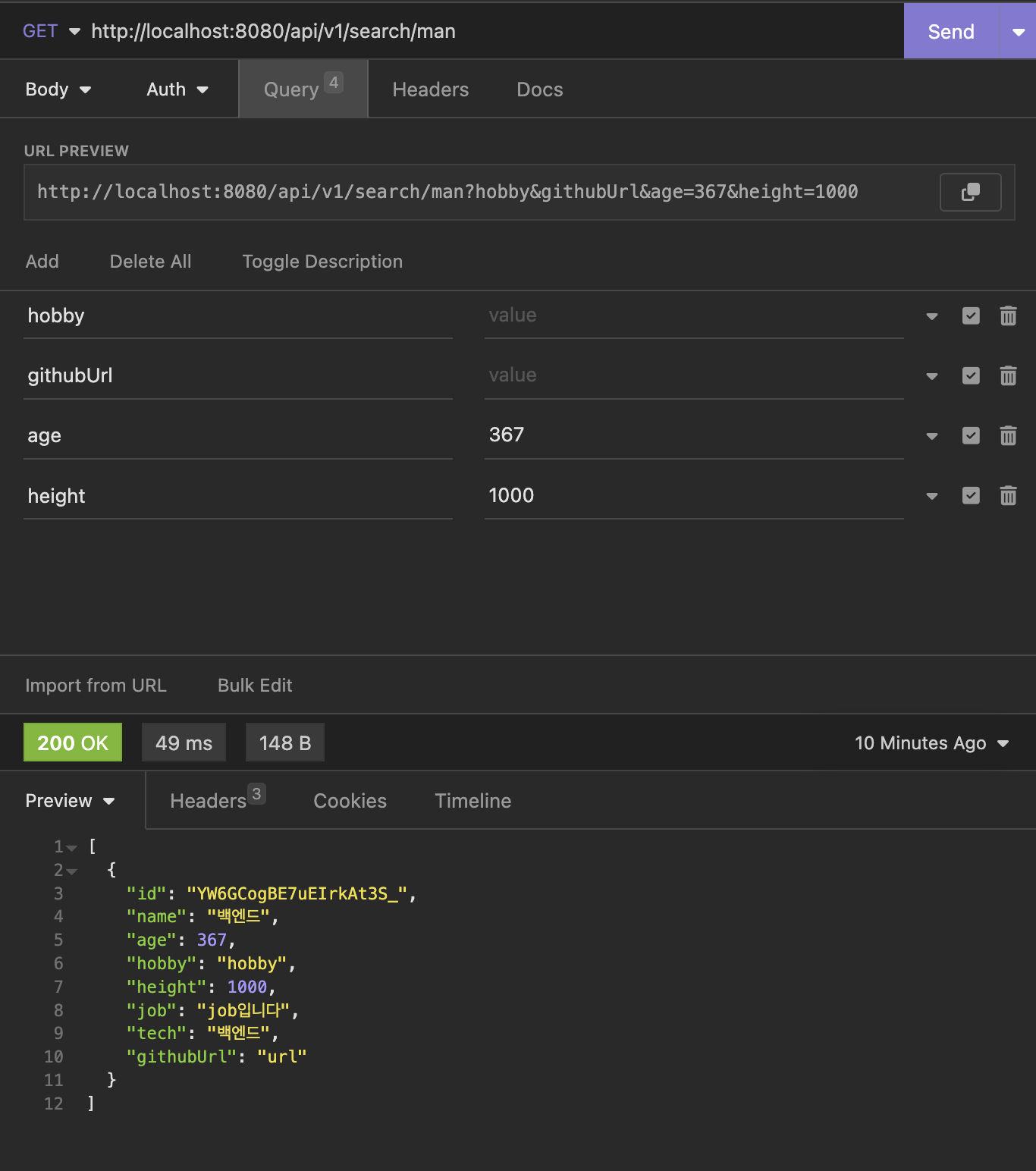
TEST 결과
Postman을 통하여 GET 요청을 날렸을 때 해당하는 검색 결과를 잘 읽어오는 것을 확인 할 수 있었습니다.
글을 마치며
드디어 Reading Server 구축을 마무리 지으며, CQRS 도입기를 마무리 짓습니다. 하지만 아직 더 발전시켜야 할 부분이 너무 많기에 다음에는 CQRS 발전기로 돌아오겠습니다.
예를들어, kafka의 효율적인 Replication, Ack 설정과 다중 토픽일 때의 설정과 ES에서의 Node,Sharding 등 제대로된 클러스터 활용과 Spring Batch를 통한 kafka의 제대로된 주기적인 메세지 전송 처리 등 이제 시작인 기분입니다!!!!
또한 Tokenizer 등과 같은 Filter 활용 그리고 FileBeats 활용 등 아직 공부할 부분이 더 많습니다. 만약 이 글을 끝까지 읽어주셨다면 정말 감사하고 같이 공부하셨으면 좋겠습니다.
